二进制文件
动态链接
位置无关代码,PIC
RELRO
实际上,为了引人 RELRO 保护机制,GOT 被拆分为.got 节和.got.plt 节两个部分,不需要延迟绑定的前者用于保存全局变量引用,加载到内存后被标记为只读;需要延迟绑定的后者则用于保存函数引用,具有读写权限。
延迟绑定
- 延迟绑定为了解决计算机多次调用带来的性能问题
- ELF文件通过PLT和GOT实现延迟绑定,每次调用库函数都有一组对应的PLT和GOT
- .plt节和.got.plt节都是数组,分别占16个和8个字节
汇编基础
ISA(指令集架构)
分为CISC(复杂指令集计算机)和RISC(精简指令集计算机)
x86/x64汇编基础
- x86有三种主要模式:保护模式(还有虚拟8086模式,即早期的虚拟机来源)、实地址模式(直接访问实际内存地址,方便开发)和系统管理模式(比如电源管理或者安全保护等等特殊的机制)。除此之外还有IA-32e的操作模式(兼容模式和64位模式):兼容模式让32位和16位的重新无需重新编译,64位模式是让cpu在64位的地址空间下运行程序
- 汇编语言风格:AT&T和Intel
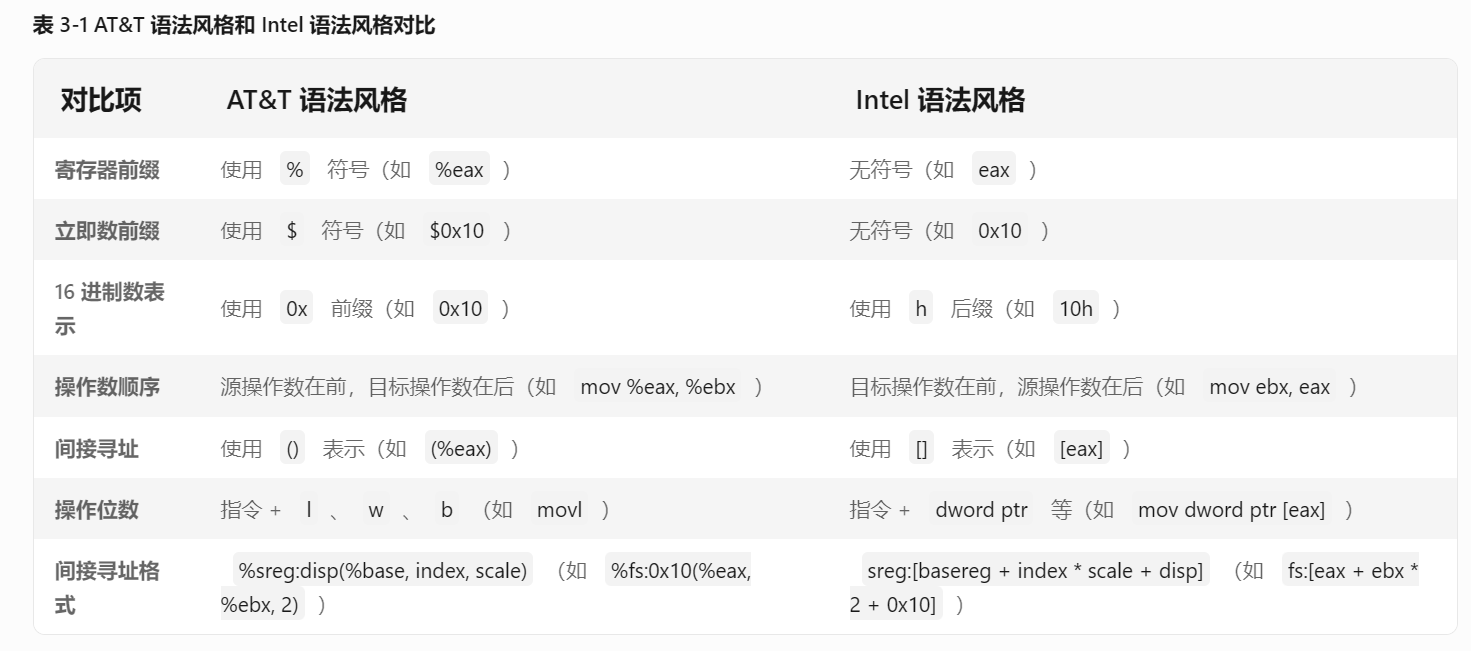
- 寄存器与数据类型
书(p37)
- 数据传达与访问
MOV EAX, ECX就是将ECX寄存器的值赋给EAX,如果说这里的ECX是一个数字的话belike:MOV EAX, 10那么10就是立即数。MOV不支持内存到内存的数据传输
- 全零扩展用于无符号数,高位补 0。
- 符号扩展用于有符号数,高位补符号位。
算数和逻辑运算+跳转和循环指令
INC和DEC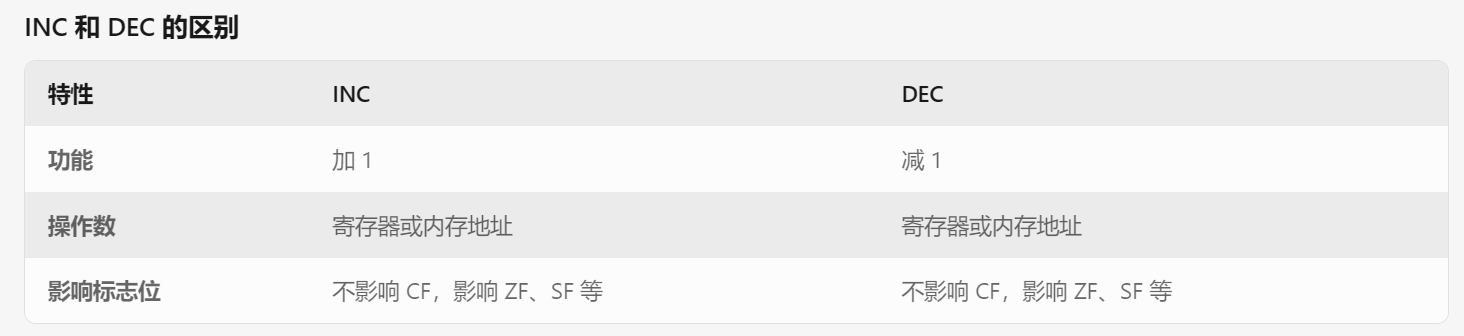
补码(Two’s Complement)
是计算机中表示有符号整数的一种方式。它是现代计算机系统中最常用的整数编码方法,因为它简化了硬件设计,并使得加法和减法运算可以统一处理。
补码的运算
- 加法:
- 补码的加法可以直接进行,无需区分正负数。
- 例如,
5 + (-3)的补码运算:
1 | 5 的补码:00000101 |
- 减法:
- 减法可以转换为加法运算,即
A - B = A + (-B)。 - 例如,
5 - 3的补码运算:
- 减法可以转换为加法运算,即
1 | 5 的补码:00000101 |
- 溢出检测:
- 如果两个正数相加结果为负数,或者两个负数相加结果为正数,则发生了溢出。
NEG就是将操作数转换为二进制补码并将符号取反
ADD和SUB
ADD就是相加,SUB就是相减
JMP和LOOP
JMP:无条件跳转指令.
1 | JMP label1 ;跳转到label1标号处 |
JMP也可以创造循环,在循环结束的时候JMP到开始的地方从而循环,除非用其他方式退出。
LOOP:跳转到指定标号,并让寄存器减一
1 | ... |
1 | 循环执行过程: |
所以作用是:跳转到指定标号并让寄存器-1(也就是循环,寄存器是几就循环几次)
(LOOP和LOOPW的计数器一般是CX,LOOPD的计数器一般是ECX,64位x86的LOOP的计数器一般是RCX)
栈与函数调用
(终于讲到栈了,因为在这之前看到好多好多栈相关的知识点,但是全然不知道啥是栈)
栈,一个先入后出的数据结构,类似于一个薯片桶(先放入的薯片被最后拿出)
作用:1.储存局部变量;2.CALL指令调用完函数之后能够正确返回;3.传递参数函数
C语言函数调用栈(一) - clover_toeic - 博客园
入栈和出栈(PUSH&POP)
PUSH入栈会对ESP/RSP/SP(这里的SP就是stack pointer)寄存器的值进行减法运算,减4(32位)或8(64位)(也就是向低地址挪动)belike:
1 | MOV EAX,1234h |
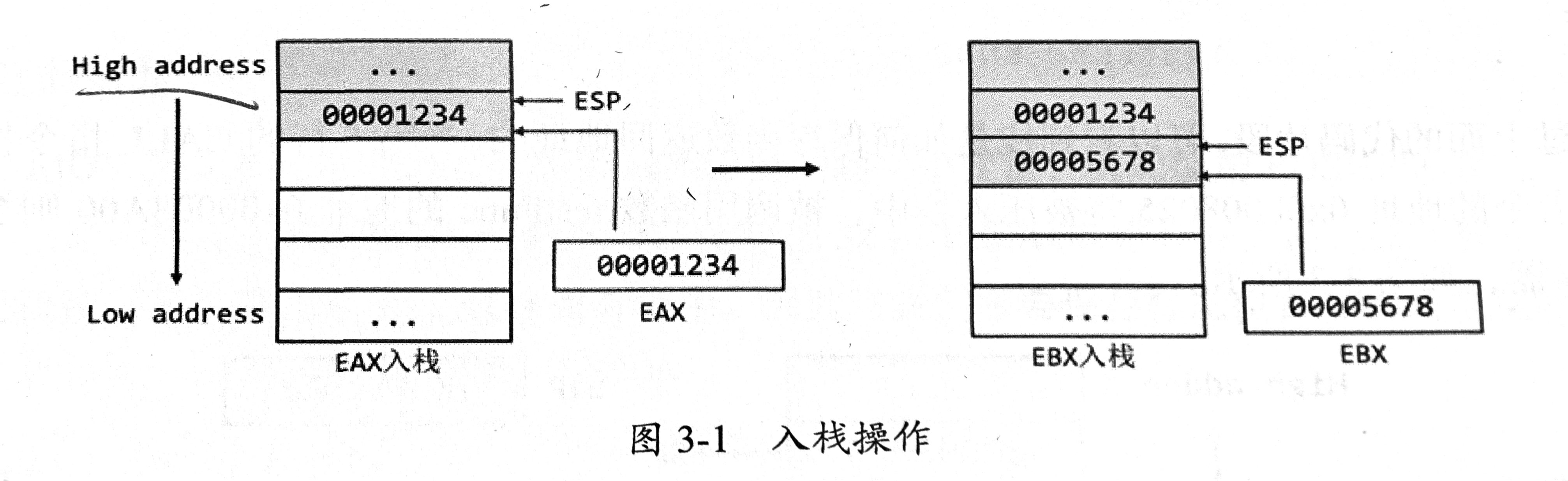
从高地址向低地址写入。
字节数会减少是因为:栈从高地址向低地址增长,因此每次压入数据时,栈指针需要 减小,以指向新的栈顶位置。(我的个人理解就是会留出2/4/8个字节来放寄存器里的数据)
POP出栈其实就是PUSH的逆操作
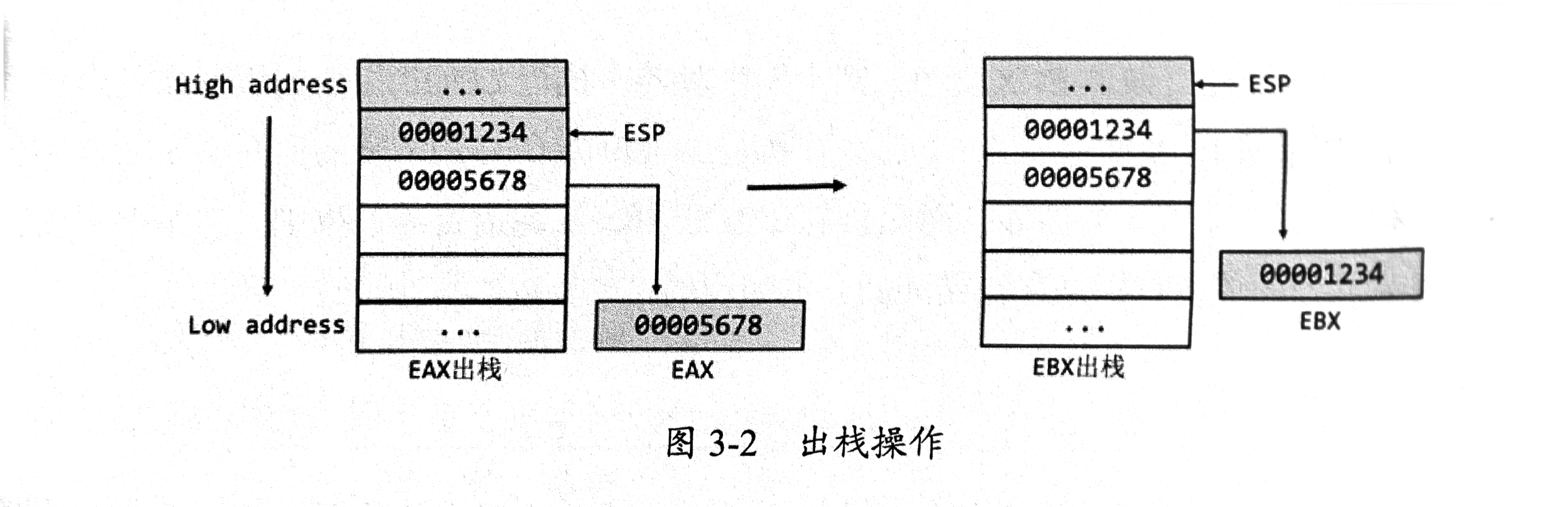
出栈:把寄存器里面的值写到其他内存地址或者寄存器,然后栈指针数值加4(32位)或8(64位)(也就是向高地址挪动)
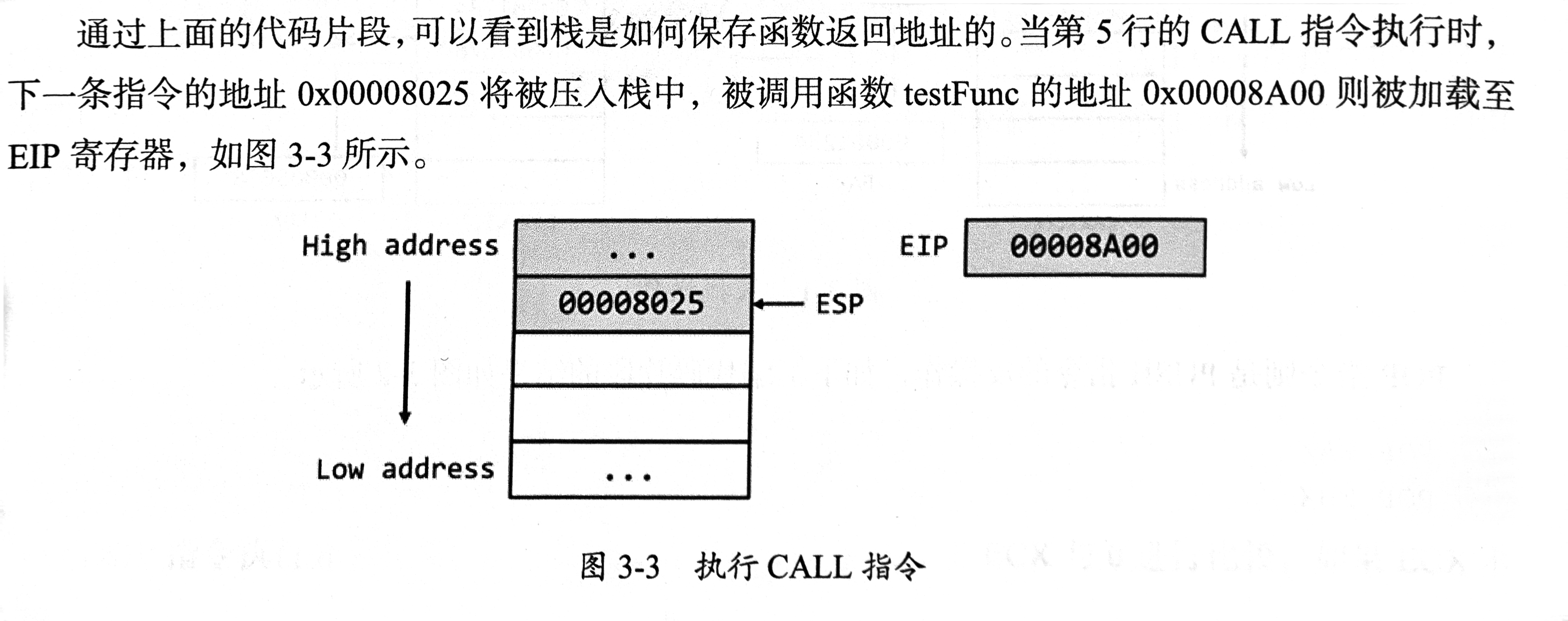
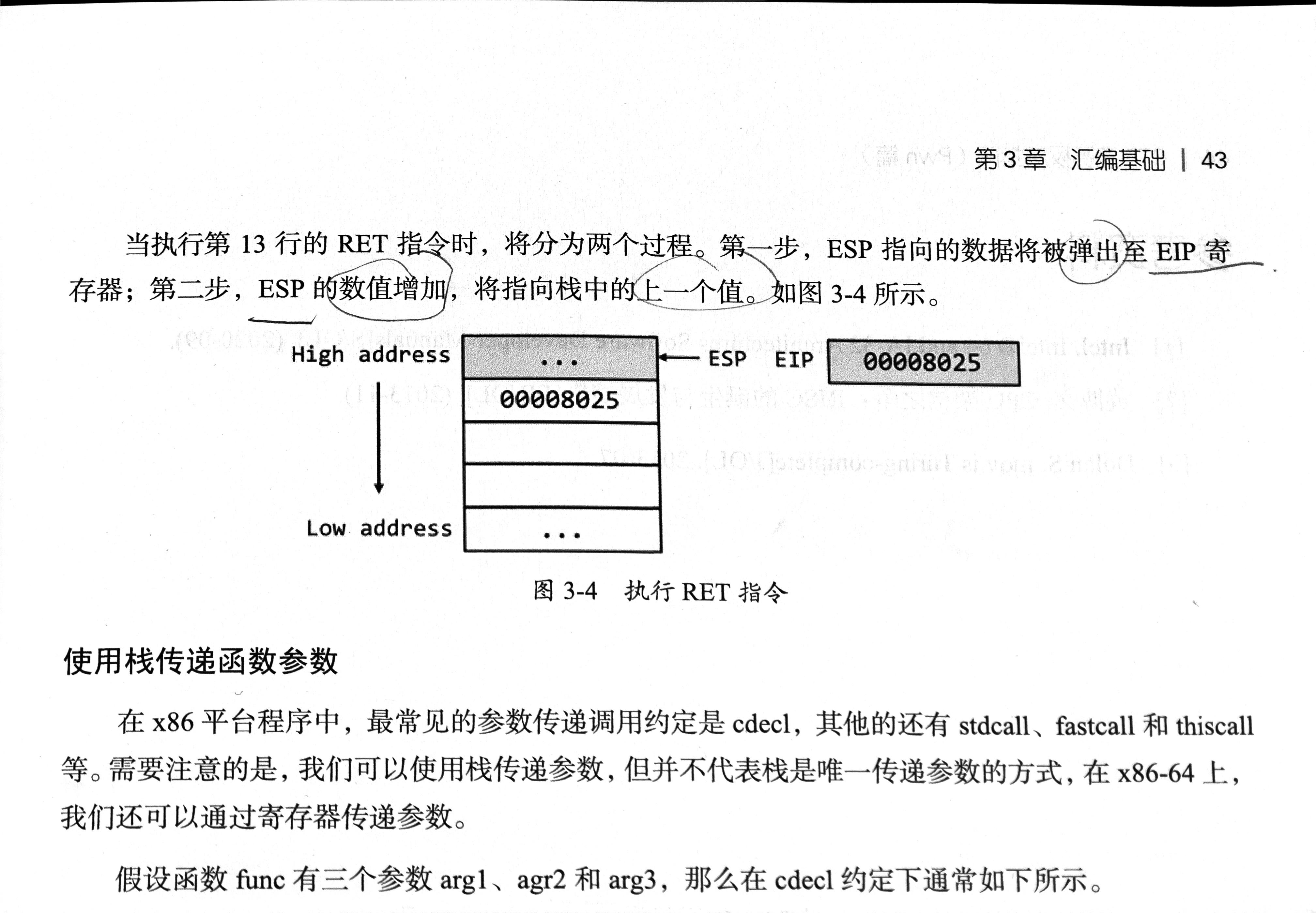
CALL&RET
CALL指令=PUSH+JMP,下一条指令作为返回指令保存在栈中(-4/8)
RET指令=POP+JMP,返回到CALL指令的下一个指令(+4/8),控制权交给main函数,非main函数都要用RET指令将控制权还给调用函数。
演示: 
用栈传递函数参数
1 | //假设func有三个参数arg1,arg2,arg3 |
对参数可变的函数来说要说明符标示格式化说明(printf的转换符像%d)
用栈储存变量
PUSHFD 和 POPFD 是汇编语言中用于操作 EFLAGS 寄存器 的指令,它们的作用分别是将 EFLAGS 寄存器的值压入栈中和从栈中弹出并恢复 EFLAGS 寄存器的值。
PUSHFD 和 POPFD 的典型使用场景
在调用子程序或中断处理程序时,通常需要保存和恢复 EFLAGS 寄存器的值,以确保程序的正确执行。例如:
1 | PUSHFD ; 保存 EFLAGS 寄存器的值 |
(PUSHFD 和 POPFD 必须成对使用,且顺序相反。例如,先PUSHFD, 再POPFD。)
汇编指令(push/pop/leave/ret/call)
| 指令 | 功能 | 示例 | 等同于 |
|---|---|---|---|
| push | 压栈 | push ebp | 等同于: mov esp,esp - 4 mov [esp],ebp []的作用是取寄存器里的地址指向的值 没有[]的作用是取寄存器的地址 |
| pop | 弹栈 | pop ebp | 等同于: mov ebp,[esp] mov esp,esp+4 |
| leave | 返回上级函数时,恢复原本栈空间 | leave | 等同于: mov esp,ebp pop ebp |
| ret | 返回上级函数后,执行上级函数的指令 | ret | 等同于: pop eip (注:图中此条有红色下划线,且标注”这条指令实际是不存在的,不能直接向RIP寄存器传送数据”) |
| call | 调用指定函数,注意,调用函数时,push eip的值实际上eip下一条指令的地址值 | call dofunc | 等同于: push eip jmp dofunc |
Linux安全机制
Linux基础
常用命令
shell是一个用户与Linux进行交互的接口程序,通常它会输出一个提示符,等待用户输入命令。如果该命令行的第一个单词不是一个内置的shell命令,那么shell就会假设这是一个可执行文件的名字,它将加载并运行这个文件。bash是当前Linux标准的默认shell,我们也可以选用其他的shell脚本语言,如zsh、fish等。下面我们列举一些日常使用的命令。
1 | 标准格式:命令名称[命令参数][命令对象] |
流、管道和重定向
书P46、47
流:可以理解成一串连续的、可边读边处理的数据。
管道(Pipeline)是命令行中用于将多个命令连接起来的强大工具,它通过 | 符号将一个命令的输出直接作为另一个命令的输入。以下是一个典型的管道示例:
统计当前目录下的 .txt 文件数量
假设你想统计当前目录下有多少个 .txt 文件,可以使用以下命令:
1 | ls | grep .txt | wc -l |
命令解析
ls:列出当前目录下的所有文件和文件夹。
grep .txt:从 ls 的输出中筛选出包含 .txt 的行(即 .txt 文件)。
wc -l:统计 grep 输出的行数,即 .txt 文件的数量。
执行过程:
1 | file1.txt |
1 | file1.txt |
1 | 2 |
通过管道 |,你可以将多个命令串联起来,实现复杂的数据处理任务。在这个例子中,ls、grep 和 wc 三个命令通过管道连接,最终统计出 .txt 文件的数量。
以下是权限标示

环境变量
LD_PRELOAD:优先调用指定数据库
environ:指向内存中的环境变量表,获得栈地址
procfs:查看系统硬件和运行进程的信息,所有运行的进程都对应/proc下的一个目录(名字就是进程的PID)
字节序
大小端和M/LSB:
1. MSB(Most Significant Bit)和 LSB(Least Significant Bit)
- MSB(最高有效位):
在二进制数中,权重最大的那个位。例如,十进制数13的二进制是1101,左边的第一个1就是 MSB(对应 8),因为它代表最大的值。 - LSB(最低有效位):
在二进制数中,权重最小的那个位。例如,1101中右边的第一个1是 LSB(对应 1)。
通俗理解:
- 想象一个数字 `1234`,左边的 `1` 是“千位”(MSB),右边的 `4` 是“个位”(LSB)。
- <strong>MSB 决定数值的大头,LSB 决定数值的小尾巴</strong>。
2.大端序(Big-Endian)
- 规则:高位字节存储在低地址,低位字节存储在高地址。(高对低,低对高)
- 示例:32 位整数
0x12345678的存储:
| 内存地址 | 0x1000 | 0x1001 | 0x1002 | 0x1003 |
|---|---|---|---|---|
| 字节内容 | 0x12 | 0x34 | 0x56 | 0x78 |
3.小端序(Little-Endian)
- 规则:低位字节存储在低地址,高位字节存储在高地址。(高对高,低对低)
- x86/x86-64 采用 小端序(Little-Endian),x86 始终是小端序!
- 示例:同一整数
0x12(高位)345678(低位)的存储:
| 内存地址 | 0x1000(低位) | 0x1001 | 0x1002 | 0x1003(高位) |
|---|---|---|---|---|
| 字节内容 | 0x78 | 0x56 | 0x34 | 0x12 |
核心转储
1.核心转储
是操作系统在程序崩溃时生成的一种文件,包含了程序崩溃时的内存映像(如堆栈、寄存器、全局变量等)。它用于调试和分析程序崩溃的原因。
2.**abort**
是 C 和 C++ 标准库中的一个函数,用于立即终止程序的执行,并生成一个核心转储文件(如果系统配置允许)。它通常用于处理无法恢复的错误或异常情况。作用如下:
终止程序:立即结束当前进程,不执行任何清理操作(如析构函数、atexit 注册的函数等)。
生成核心转储:如果系统配置允许,abort 会触发核心转储文件的生成,便于调试。
返回状态码:向操作系统返回一个非零状态码,通常表示程序异常终止。
3.Trace/Breakpoint Trap
是一种由操作系统或调试器触发的异常(或信号),用于暂停程序的执行并进入调试模式。它通常与调试器(如 GDB)或程序中的断点设置相关。
在 Linux/Unix 系统中,Trace/Breakpoint Trap 对应信号 SIGTRAP。
4.核心转储信号
| 信号 | 动作 | 解释 |
|---|---|---|
| SIGQUIT | Core | 通过键盘退出时 |
| SIGILL | Core | 遇到不合法的指令时 |
| SIGABRT | Core | 从 abort 中产生的信号 |
| SIGSEGV | Core | 无效的内存访问 |
5.示例:
GDB 调试核心转储文件的简单示例
以下是一个完整的示例,演示如何生成核心转储文件并用 GDB 分析它:
1. 编写示例程序(触发崩溃)
创建一个 C 程序 crash.c,故意制造一个段错误(访问空指针):
1 | #include <stdio.h> |
2. 编译程序(启用调试符号)
使用 -g 选项编译,生成调试信息:
1 | gcc -g -o crash crash.c |
3. 允许生成核心转储文件
在终端中设置核心转储文件大小无限制:
1 | ulimit -c unlimited |
4. 运行程序并生成核心转储文件
运行程序,触发段错误:
1 | ./crash |
输出结果:
1 | 程序启动 |
此时会生成一个名为 core 或 core.<PID> 的核心转储文件。
5. 使用 GDB 分析核心转储文件
加载可执行文件和核心转储文件:
1 | gdb ./crash core |
GDB 输出示例:
1 | GNU gdb (Ubuntu 9.2-0ubuntu1~20.04) 9.2 |
6. 查看崩溃位置
在 GDB 中输入 bt(backtrace)查看堆栈回溯:
1 | (gdb) bt |
解释:
#0:当前崩溃的代码位置(crash函数的第 5 行)。#1:调用链(main函数调用了crash函数)。
7. 查看源码和变量
- 查看源码上下文:
1 | (gdb) list |
- 查看指针
**p**的值:
1 | (gdb) print p |
关键步骤总结
- 编译时加
**-g**:保留调试信息。 - 运行程序生成 core:需确保
ulimit -c unlimited。 - GDB 加载 core 文件:
gdb <可执行文件> <core文件>。 - 分析崩溃点:
bt查看调用栈,print查看变量。
常见问题
- 找不到 core 文件:
- 检查路径:
/var/lib/apport/coredump(Ubuntu 默认)。 - 强制生成:
echo core | sudo tee /proc/sys/kernel/core_pattern。
- 检查路径:
- GDB 显示无符号:编译时未加
-g选项。
通过这个例子,你可以快速定位到 crash.c 第 5 行的空指针解引用错误!
系统调用
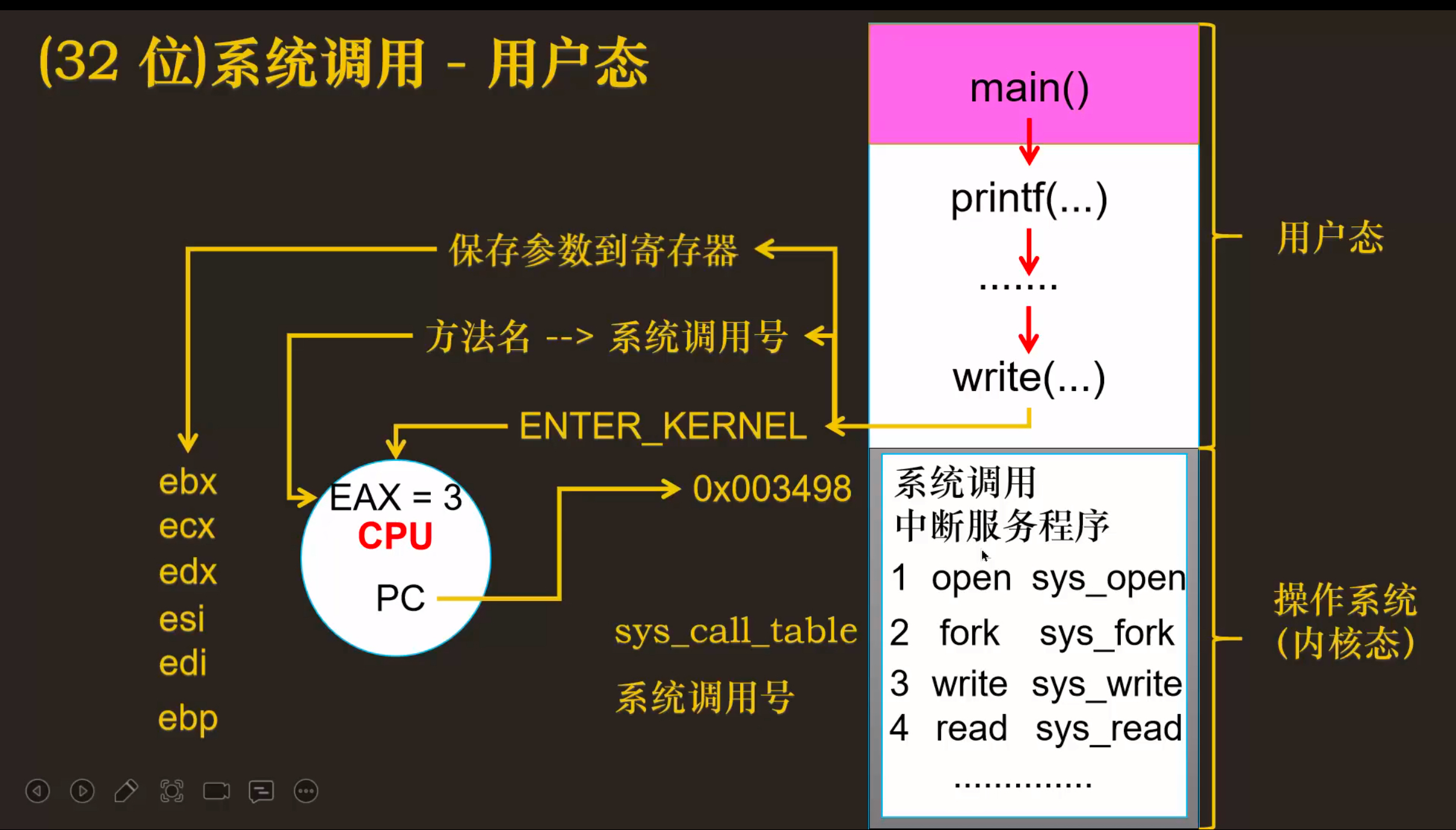
32位系统调用流程如下:
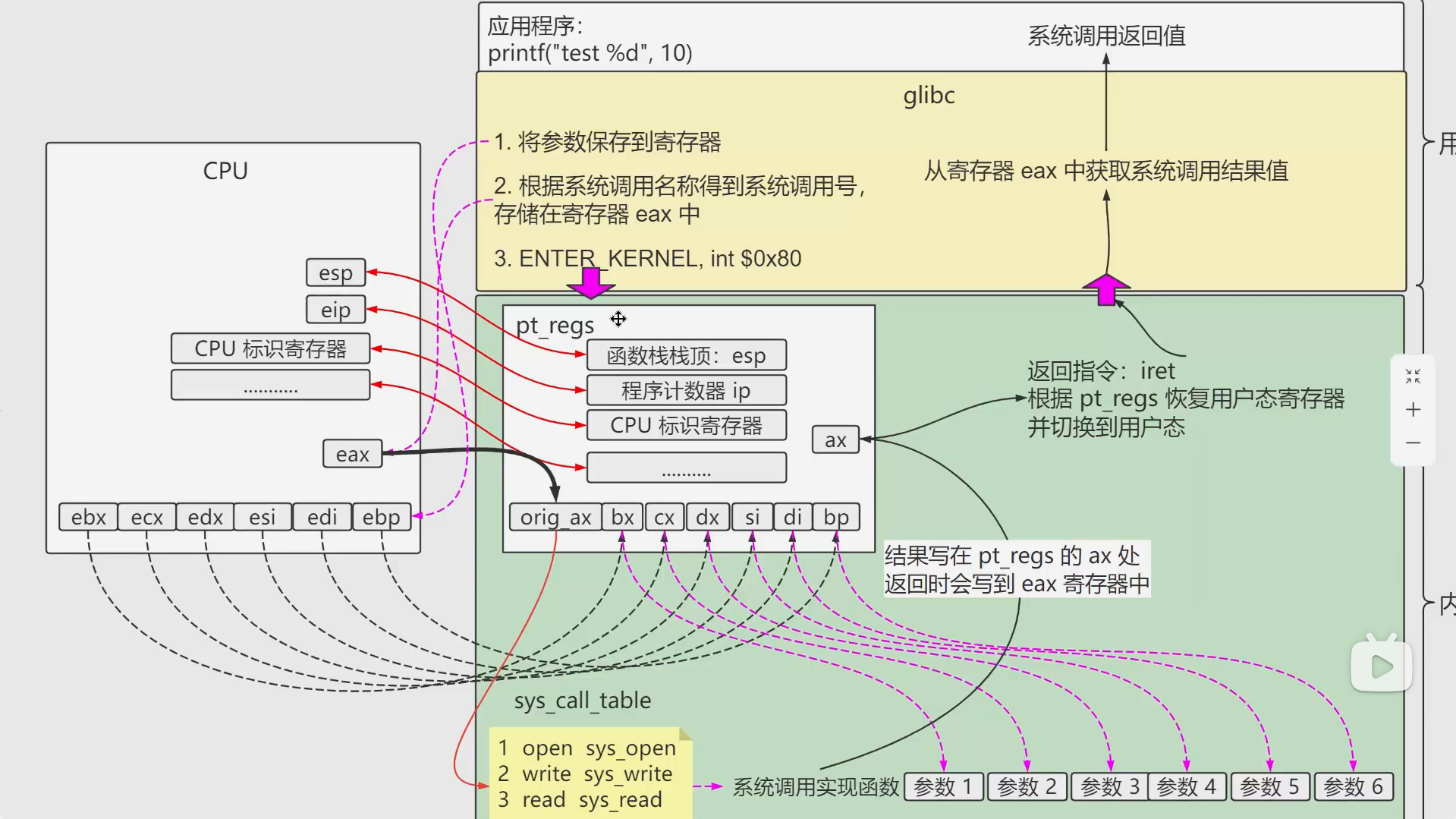
enter_kernel 的作用:
用户程序通过 enter_kernel 进入内核态,获得执行特权指令的能力(如访问硬件、修改页表)。以下是 enter_kernel 的典型工作流程:
- 保存用户态上下文:将用户程序的寄存器(如 eip、esp)保存到内核栈。
- 切换 CPU 模式:从用户态切换到内核态,更新 CPU 的标志寄存器(如 EFLAGS)。
- 跳转到内核入口:根据中断号或系统调用号,跳转到对应的内核服务函数。
- 执行内核服务:内核验证请求的合法性,执行相应操作(如读写文件、创建进程)。
- 恢复用户态上下文:将保存的寄存器恢复,切换回用户态。
- 返回用户程序:继续执行用户程序的下一条指令。
**int $0x80** 是 **enter_kernel** 的一种实现方式
enter_kernel是抽象概念:表示用户程序进入内核态的过程。int $0x80是具体实现:在传统 x86 架构中,通过int $0x80指令实现enter_kernel的功能。
系统调用号:每个系统调用有唯一的编号,定义在 /usr/include/asm/unistd.h 中。例如:
exit:编号 1read:编号 3write:编号 4open:编号 5
参数传递:系统调用的参数通过寄存器传递(各种寄存器的作用)例如:
EAX:系统调用号。EBX:第一个参数。ECX:第二个参数。EDX:第三个参数。ESI:第四个参数。EDI:第五个参数。EBP:第六个参数。
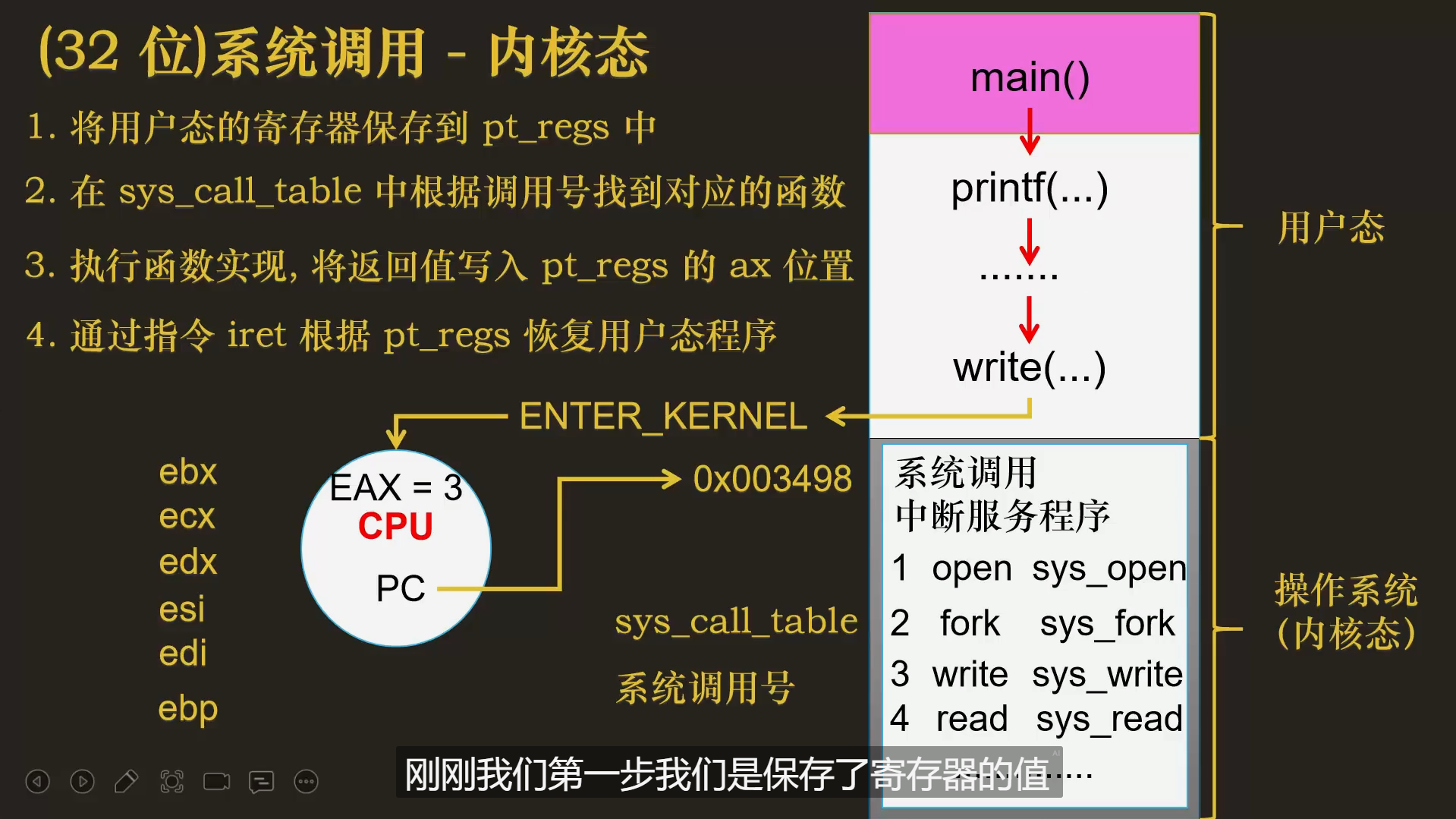
pt_regs :
是 Linux 内核中定义的一个数据结构,用于保存用户态程序的寄存器状态。当用户程序通过系统调用、中断或异常进入内核态时,内核会将用户程序的寄存器值保存到 pt_regs 结构中,以便在返回用户态时恢复上下文。
当用户程序通过系统调用进入内核态时,内核会将寄存器状态保存到 pt_regs 中,例如:
1 | asmlinkage long sys_example(struct pt_regs *regs) { |
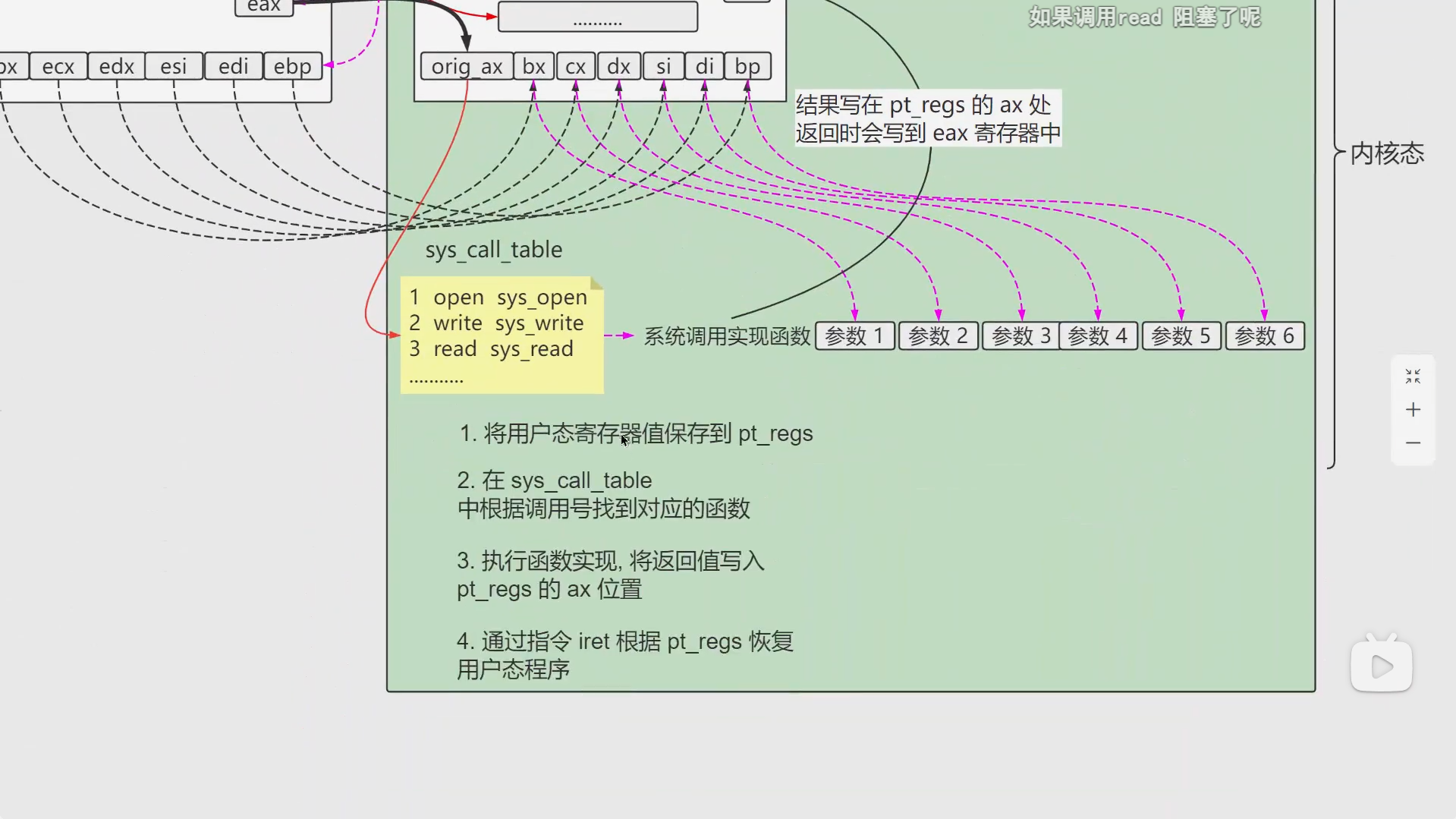
iret(Interrupt Return)
是 x86 架构中的一条机器指令,用于从中断或异常处理程序返回到被中断的程序。它是中断处理流程的收尾步骤,负责恢复被中断程序的上下文(如寄存器、栈指针、指令指针等),并切换回用户态(如果中断来自用户态)。
1 | .section .data |
64位如下:
和32位的区别其实就是一些指令和寄存器名称出现了差别,流程一模一样
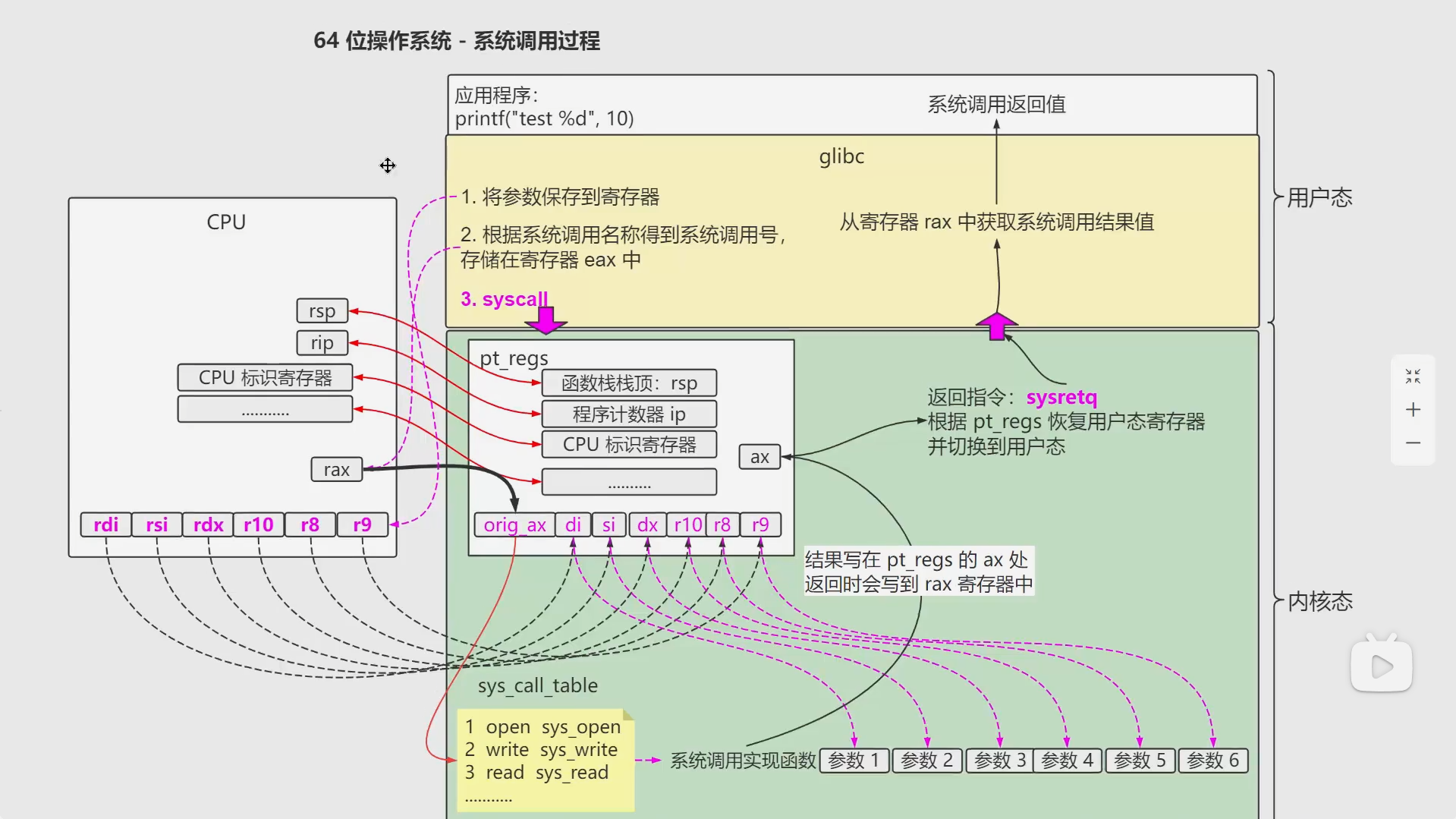
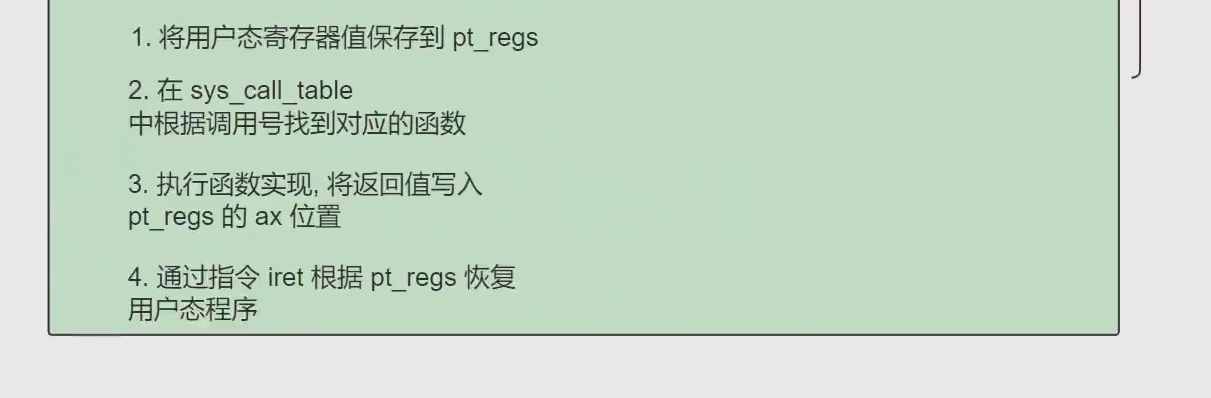
syscall
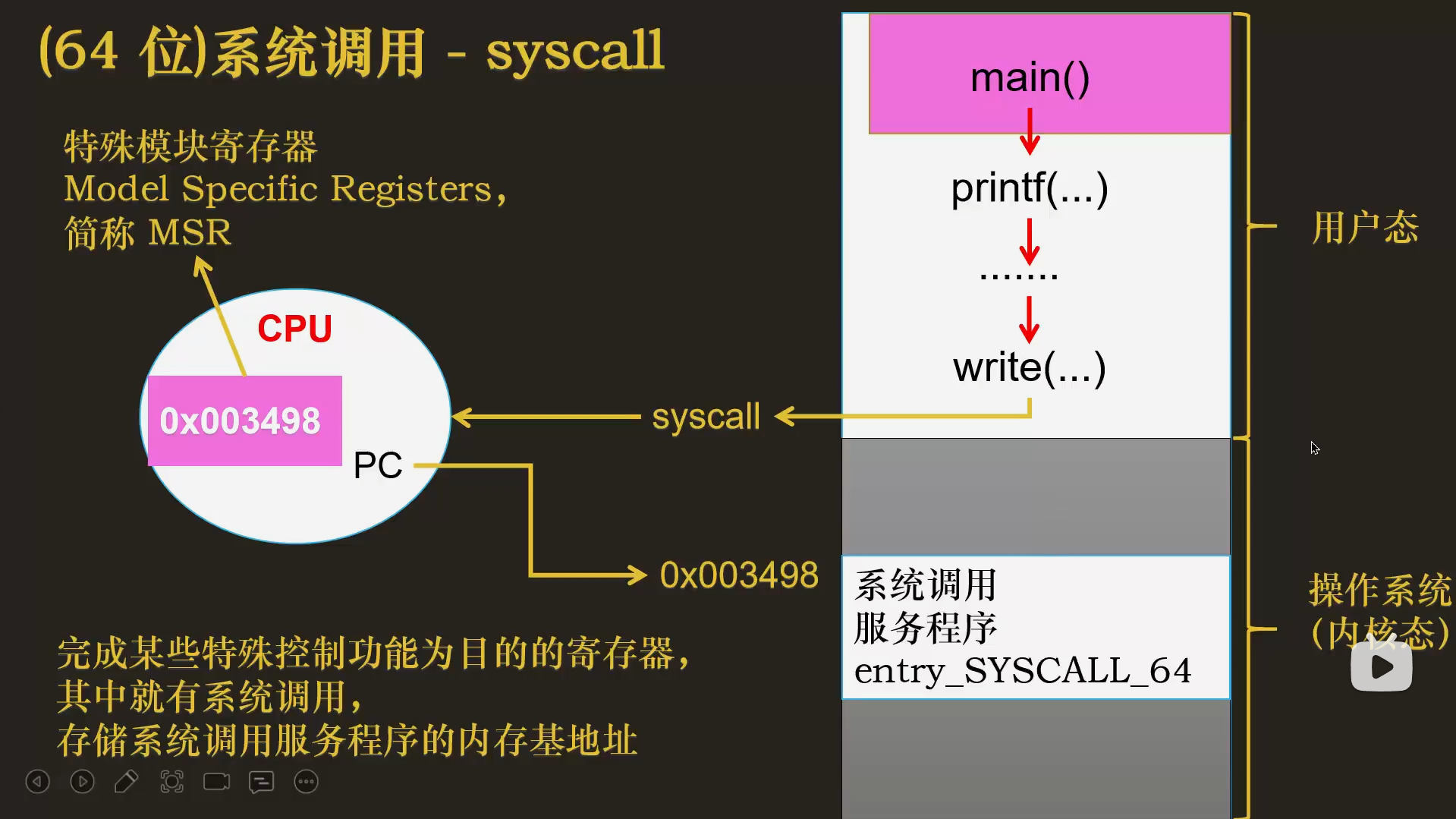
MSR(Model-Specific Register)
是 CPU 中的一组特殊寄存器,用于控制和监控 CPU 的硬件行为和性能状态。这些寄存器因 CPU 型号而异,提供了对底层硬件功能的直接访问。系统调用需要从用户态转向内核态,这里就可以用msr寄存器来存储对系统的调用部分。
内存基地址(Base Address)
是计算机系统中用于定位内存区域起始位置的一个关键概念。它通常表示一段连续内存的起始地址,是访问内存中特定数据或资源的基础。
Stack Canaries
Stack Canaries (取名自地下煤矿的金丝雀,因为它能比矿工更早地发现煤气泄露,有预警的作用)是一种对抗栈溢出攻击的技术,即SSP安全机制(这个就是Stack Canaries)。它的核心思想是在函数的栈帧中插入一个随机值(称为“金丝雀”),并在函数返回前验证该值是否被篡改。如果金丝雀被破坏,程序会立即终止,防止攻击者利用溢出控制程序流。
Canary的值是栈上的一个随机数,在程序启动时随机生成并保存在比函数返回地址更低的位置。由于栈溢出是从低地址向高地址进行覆盖,因此攻击者要想控制函数的返回指针,就一定要先覆盖到Canary。程序只需要在函数返回前检查Canary是否被篡改,就可以达到保护栈的目的。
栈布局与金丝雀的位置:在启用 Stack Canaries 时,函数栈帧的结构会发生变化:
1 | +------------------+ |
示例
1 | ; 函数入口 |
小记:
i) mov DWORD PTR [ebp-0xc], eax;将 EAX 寄存器中的值存储到 栈上的一个内存位置(ebp偏移12个字节位置),这里的DWORD PTR(数据大小修饰符)是为了明确告诉汇编器:操作的是一个 32 位(4字节)的数据。相关的还有一下修饰符:
| 修饰符 | 位数 | 字节数 | 典型用途 | 示例指令 |
|---|---|---|---|---|
BYTE PTR |
8 | 1 | 操作字节(如 char) |
mov BYTE PTR [eax], 0x41 |
WORD PTR |
16 | 2 | 操作字(如 short) |
mov WORD PTR [ebx], 0x1234 |
**DWORD PTR** |
32 | 4 | 操作双字(如 int、指针) |
mov DWORD PTR [ecx], eax |
QWORD PTR |
64 | 8 | 操作四字(如 long long) |
mov QWORD PTR [rdx], rax |
TBYTE PTR |
80 | 10 | 操作扩展精度浮点(long double) |
fld TBYTE PTR [ebp-0x10] |
ii) gs还有fs:段寄存器(Segment Register),在 x86-32 和 x86-64 中用于指向当前线程的特定内存区域(如 TLS)。
iii) TLS:线程局部存储(TLS, Thread-Local Storage),在多线程程序中,每个线程可以有自己的局部变量(如 errno),只有当前线程能读取TLS,而其他线程读取不了。
补充(数据的写入流程)
在 x86/x86-64 架构中,数据从寄存器写入内存的顺序(或从内存加载到寄存器)涉及多个层次的概念,包括 字节序(Endianness)、数据对齐(Alignment) 和 CPU 的微架构行为。下面详细解释这些关键点:
1. 数据写入内存的基本流程
当执行类似 mov DWORD PTR [ebp-0xc], eax 的指令时,CPU 会完成以下步骤:
- 计算内存地址:
- 先计算
[ebp-0xc]的地址(ebp是基址指针,-0xc是偏移量)。 - 例如,若
ebp = 0x7ffffff0,则目标地址是0x7fffffe4(0x7ffffff0 - 0xc)。
- 先计算
- 检查权限:
- CPU 会检查该地址是否可写(是否属于当前进程的合法内存范围)。
- 写入数据:
- 将
eax的 32 位(4 字节)数据写入[ebp-0xc]指向的内存位置。 - 写入顺序取决于字节序(Endianness)。
- 将
2. 字节序(Endianness)决定写入顺序
x86/x86-64 采用 小端序(Little-Endian),即:
- 低字节存储在低地址,高字节存储在高地址。
示例:**mov DWORD PTR [ebp-0xc], eax**
假设:
eax = 0x11223344(4 字节数据)- 目标地址
[ebp-0xc]指向0x7fffffe4
写入后的内存布局:
| 内存地址 | 存储的字节值 |
|---|---|
0x7fffffe4 |
0x44(最低字节, AL部分) |
0x7fffffe5 |
0x33 |
0x7fffffe6 |
0x22 |
0x7fffffe7 |
0x11(最高字节, AH部分) |
内存可视化(从低地址到高地址):
1 | 0x7fffffe4: 44 33 22 11 |
3. 未对齐访问(Unaligned Access)
- 对齐(Alignment):数据地址最好是数据大小的整数倍(如 4 字节数据应对齐到 4 的倍数地址)。
- 可以用nop辅助对齐
- x86 允许未对齐访问,但性能可能下降(某些架构如 ARM 会直接报错)。
示例:
1 | asm |
4. 多字节写入的原子性
- 单字节访问:总是原子的。
- 多字节访问(如 32/64 位):
- 在自然对齐的地址上是原子的(现代 x86 CPU 保证)。
- 未对齐时可能分多次总线操作,非原子。
5. 实际调试观察
用调试器(如 GDB)查看内存变化:
1 | # 假设执行 `mov DWORD PTR [ebp-0xc], eax`,eax=0x11223344 |
简介
canaries可以分为3类:terminator, random, random XOR
具体实现是
1 | 栈溢出许多都是由于字符串操作不正当 (strcpy)所产生的 |
1 | 防止canaries 被攻击者猜到 random canaries 通常在程序初始化的时候 |
1 | 和random canaries 类似 但是多了一个XOR操作 |
Canaries有关参数
| -fstack-protector | 对alloca 系列函数和内部缓冲区大于8字节的函数启用保护 |
|---|---|
| -fstack-protector-strong | 增加对包含局部数组定义和地址引用的函数的保护 |
| -fstack-protector-all | 对所有函数启用保护 |
| -fstack-protector-explicit | 对包含stack_ protect 属性的函数启用保护 |
| -fno-stack-protector | 禁用保护 |
结构体(struct)是什么?
- 基本概念
结构体(struct) 是 C/C++ 中的一种 复合数据类型,可以将多个不同类型的变量组合成一个整体。
它类似于现实生活中的“表格”,比如:
一个“学生”的结构体可以包含:姓名(字符串)、年龄(整数)、成绩(浮点数)等字段。
一个“坐标点”的结构体可以包含:x 坐标(整数)、y 坐标(整数)。
2.定义结构体
1 | // 定义一个名为 "Student" 的结构体类型 |
struct Student是类型的名字(类似int、float)。- 内部的
name、age、score是结构体的 成员(字段)。
3.示例代码
1 | #include <stdio.h> |
tcbhead_t
在操作系统(尤其是 Linux 内核)的上下文中,tcbhead_t 是一个与 线程控制块(Thread Control Block, TCB) 相关的数据结构,主要用于存储线程的上下文信息和架构特定的控制数据。以下是详细解析:
1. **tcbhead_t** 的基本定义
- 作用:
tcbhead_t是线程本地存储(Thread-Local Storage, TLS)和线程上下文的核心数据结构,通常定义在操作系统内核或 C 库(如 glibc)中。 - 典型场景:
- 在 Linux x86_64 架构中,
tcbhead_t存储线程的栈指针、TLS 指针、浮点寄存器状态等。 - 在 多线程程序 中,每个线程通过
tcbhead_t维护独立的执行环境。
- 在 Linux x86_64 架构中,
2. **tcbhead_t** 的典型字段(以 x86_64 为例)
以下是 Linux 内核或 glibc 中常见的 tcbhead_t 结构体定义(简化版):
1 | typedef struct { |
关键字段说明:
| 字段 | 作用 |
|---|---|
tcb |
指向当前线程的 TCB 结构,用于快速访问线程本地数据。 |
******stack_guard** |
栈溢出保护的金丝雀值(Stack Canary),防止缓冲区溢出攻击。 |
fs_base |
在 x86_64 中,fs段寄存器通常指向线程本地存储(TLS)的基地址。 |
gs_base |
在 Linux 内核中,gs可能用于存储每 CPU 数据或内核线程信息。 |
static
是一个 存储类说明符(storage class specifier),用于修饰变量或函数,改变它们的 存储期(lifetime) 或 链接属性(linkage)。
两种主要用法
(1) 修饰局部变量(在函数内部)
- 作用:使局部变量的生命周期延长到整个程序运行期间(存储在静态存储区),但作用域仍限于函数内部。
- 特点:
- 变量只初始化一次,即使函数多次调用,它的值也会保留。
- 默认初始化为
0(如果是全局变量或静态变量)。
示例:
1 | #include <stdio.h> |
(2) 修饰全局变量或函数(在文件作用域)
- 作用:限制变量或函数的链接属性,使其仅在当前文件可见(内部链接),避免与其他文件的同名变量/函数冲突。
- 特点:
- 如果全局变量或函数声明为
static,它们不能被其他文件通过extern访问。
- 如果全局变量或函数声明为
示例:
1 | // file1.c |
******static** 与数据类型的关系
static不改变变量的数据类型,它只是改变变量的存储方式和作用域。- 它可以和任何数据类型一起使用,例如:
static int x;static char c;static float f;
| 用法 | 作用 | 示例 |
|---|---|---|
| 修饰局部变量 | 使变量生命周期延长,但作用域不变 | static int count = 0; |
| 修饰全局变量/函数 | 限制为当前文件可见(内部链接) | static int hidden_var = 42; |
lifetime
1. 变量的生命周期(Lifetime)是什么?
生命周期 指的是变量 从创建到销毁的时间范围。在 C 语言中,变量可以有两种主要的生命周期:
- 自动存储期(auto):变量在进入作用域时创建,离开作用域时销毁(如普通局部变量)。
- 静态存储期(static):变量在程序启动时创建,程序结束时才销毁(如全局变量、
static变量)。
2. 普通局部变量(自动存储期)
1 | void func() { |
- 存储位置:栈内存(stack)
- 生命周期:
- 每次调用
func()时,x被创建并初始化为0。 - 函数结束时,
x被销毁。 - 下次调用
func()时,x又是一个全新的变量。
- 每次调用
3. **static** 局部变量(静态存储期)
1 | void func() { |
- 存储位置:静态存储区(全局数据区)
- 生命周期:
- 程序启动时,
x被创建并初始化为0(只初始化一次)。 - 每次调用
func()时,x的值会保留(不会被重新初始化)。 - 程序结束时,
x才被销毁。
- 程序启动时,
| 变量类型 | 存储位置 | 创建时机 | 销毁时机 | 初始化次数 |
|---|---|---|---|---|
| 普通局部变量 | 栈(stack) | 每次函数调用时创建 | 函数返回时销毁 | 每次调用 |
static变量 |
静态存储区 | 程序启动时创建 | 程序结束时销毁 | 仅第一次 |
总结一句话就是普通局部变量每次调用会刷新,static 局部变量每次不刷新(程序结束才结束)
4. 深入理解:为什么 **static** 变量能保留值?
(1) 普通局部变量(栈内存)
- 栈内存是 临时存储,函数调用时会分配,返回后立即回收。
- 每次调用函数时,栈帧(stack frame)被创建,变量重新初始化。
(2) static 变量(静态存储区)
- 静态存储区是 全局持久内存,程序启动时就分配好,直到程序结束才释放。
static变量只初始化一次,后续函数调用直接访问同一内存地址。
5. 实际内存布局示例
假设程序运行时内存布局如下:
1 | 内存地址 存储内容 |
- 每次调用
func()时:- 普通变量
int y会在0x4000附近分配,函数返回后立即回收。 static int x始终位于0x2000,值会一直保留。
- 普通变量
编译与链接
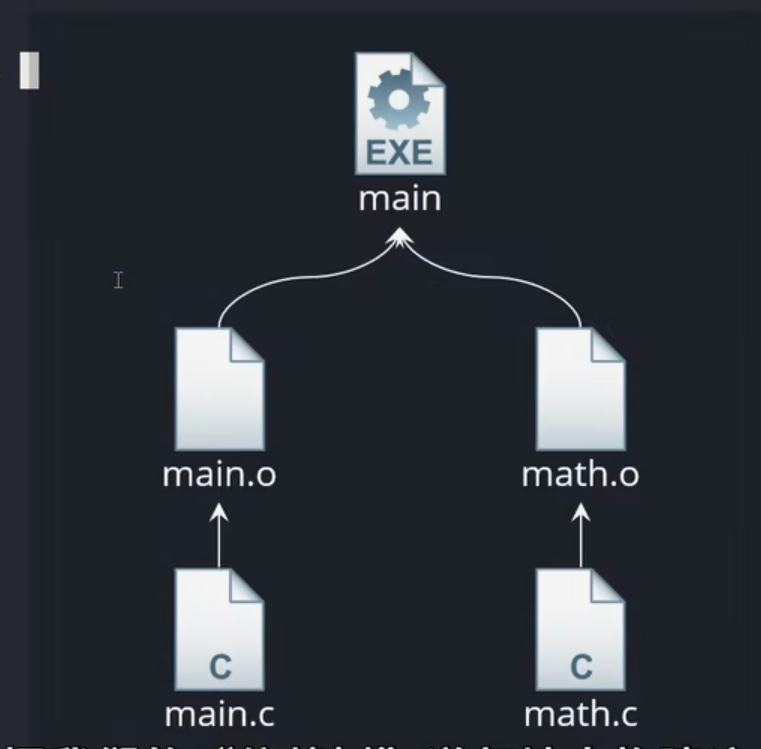
makefile指令可以直接将main编译成可执行文件并将相对应的可执行文件一一对应的构建,从而生成了依赖树;
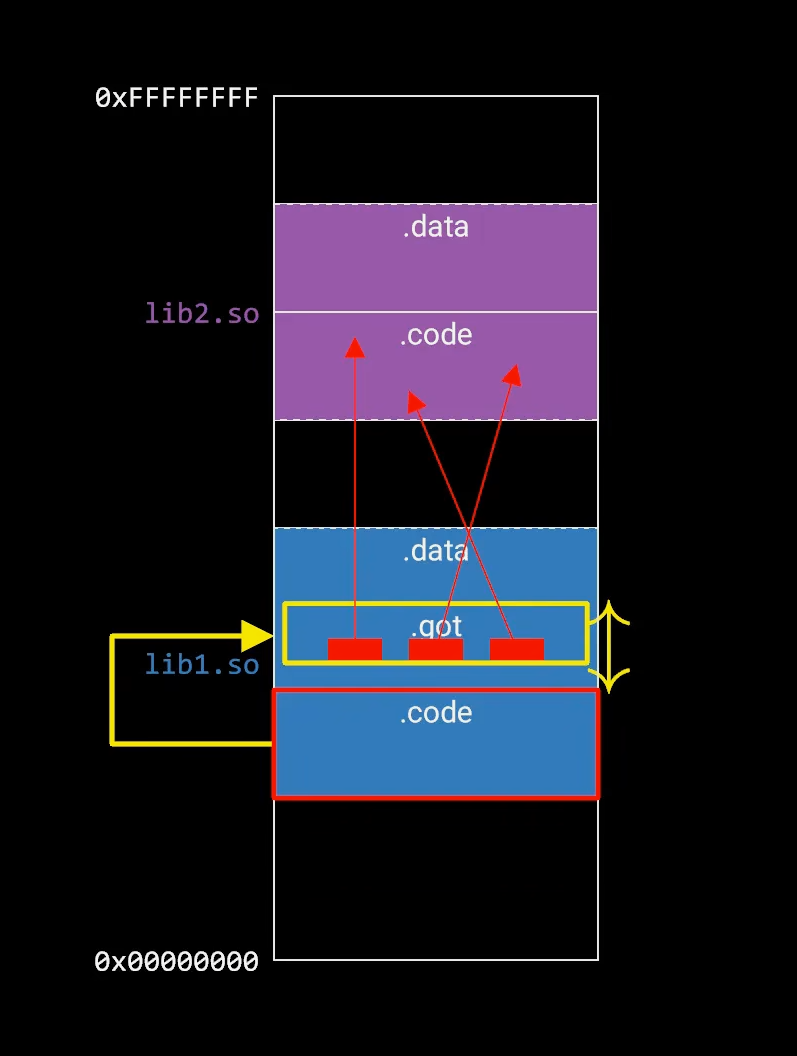
got全局偏移表
链接地址在代码段中是不会改变的,因为这样一来其他进程就无法与之共享代码段,所以重定位步骤放到了数据段中的got.当中,这里专门存储了全局变量和函数跳转地址。
Canaries的实现
1 | #0 security_init () at rtld.c:711 |
调用栈概览
该调用栈展示了 动态链接器(ld.so) 的初始化过程,涉及安全机制(如栈保护)、程序加载和系统相关初始化。以下是每个栈帧的详细说明:
Frame #0: **security_init()**
- 位置:
rtld.c:711 - 作用:动态链接器的 安全初始化函数。
- 关键操作:
- 设置 栈保护金丝雀(Stack Canary),防止缓冲区溢出攻击。
- 初始化 Pointer Guard(用于保护函数指针,防止劫持)。
- 准备 地址空间布局随机化(ASLR) 相关数据。
- 示例代码(glibc 源码):
1 | // rtld.c |
Frame #1: **dl_main()**
- 位置:
rtld.c:1688 - 作用:动态链接器的 主逻辑函数,负责加载程序依赖的共享库。
- 关键操作:
- 解析程序头(
phdr和phnum),加载程序段(如.text,.data)。
- 解析程序头(
| 字段 | 类型 | 说明 |
|---|---|---|
e_phoff |
ElfN_Off |
程序头表在文件中的偏移量(从文件开头计算)。 |
e_phnum |
ElfN_Half |
程序头的数量(即有多少个 ElfN_Phdr条目)。 |
e_phentsize |
ElfN_Half |
每个程序头的大小(通常为 sizeof(ElfN_Phdr))。 |
- 处理动态段(`.dynamic`),获取依赖库列表(如 `libc.so`)。
- 执行符号解析和重定位(Relocation)。
- 调用 `security_init()` 初始化安全机制。
- 参数说明:
phdr,phnum: 程序头信息(来自 ELF 文件),此处被优化(<optimized out>)。user_entry: 最终将跳转到用户程序的入口(如main函数)。
Frame #2: **_dl_sysdep_start()**
- 位置:
../elf/dl-sysdep.c:249 - 作用:系统相关的初始化入口,为动态链接器准备执行环境。
- 关键操作:
- 获取环境变量(
LD_PRELOAD,LD_LIBRARY_PATH)。 - 解析辅助向量(
auxv),获取内核传递的信息(如页大小、平台类型)。 - 调用
dl_main()进入动态链接主逻辑。
- 获取环境变量(
Frame #3: **_dl_start_final()**
- 位置:
rtld.c:307 - 作用:动态链接器启动的 最终阶段初始化。
- 关键操作:
- 设置动态链接器自身的全局数据。
- 调用
_dl_sysdep_start()进行系统相关初始化。
Frame #4: **_dl_start()**
- 位置:
rtld.c:413 - 作用:动态链接器的 入口函数,由汇编代码
_start调用。 - 关键操作:
- 初始化动态链接器的栈和全局状态。
- 调用
_dl_start_final()继续启动流程。
Frame #5: **_start()**
- 位置:
/usr/local/glibc-2.23/lib/ld-2.23.so - 作用:动态链接器自身的 入口点(Entry Point),由内核加载后执行。
- 关键操作:
- 调用
_dl_start()进入动态链接器的主逻辑。 - 最终跳转到用户程序入口(如
main函数)。
- 调用
调用栈流程图
1 | plaintext |
关键点总结
- 动态链接器的启动流程:
- 从
_start()开始,逐步初始化动态链接器自身。 - 通过
_dl_sysdep_start()处理系统相关配置。 - 在
dl_main()中加载用户程序及其依赖库。 - 在
security_init()中启用安全机制(如 Stack Canary)。
- 从
<optimized out>的含义:- 表示编译器优化(如
-O2)导致某些参数在调试时不可见。 - 可通过禁用优化(
-O0)或检查源码恢复上下文。
- 表示编译器优化(如
- 安全机制的时机:
- 安全机制(如 Stack Canary)在动态链接器自身初始化时已启用,因此攻击动态链接器的漏洞需要绕过这些保护。
杂记
1.动态调试
https://blog.csdn.net/2301_76262491/article/details/144476637
开始debugger后输入地址和密码
之后在虚拟机里运行终端:
1 | chmod 777 ./* |
2.pwntool的常用语法
- p.sendlineafter(b’*character ‘, b’*data‘) //在某字符后输入
- p = remote(‘*ip address‘, port) //nc连接端口
p.interactive():在取得shell之后使用,直接进行交互,相当于回到shell的模式。
3.Ubuntu运行带有pwntools的py文件开头
1 | python3 -m venv ~/my_venv # 创建虚拟环境 |
4.分屏显示
vim ~/.gdbinit
set context-output /dev/pts/2 (这里的2可以根据终端编号改变,终端编号用tty来查看)