密码学
1.AES
1 | #!/usr/bin/env python3 |
1 | def xor_bytes(a, b): |
(keystream):
e38339bee8cd0e5acce0c5ffde3f14505b900edbe163edb3f8bf014d5cef86cb871d8362b4d5b6d23df2135dc12b1915fa81589dc0d6
flag{GCM_IV_r3us3_1s_d4ng3r0us_f0r_s3cur1ty}
2.rsadl
1 | from Crypto.Util.number import * |
1 | import math |
3.多重Caesar密码
“myfz”对应“flag”,用的是依次前移7、13、5、19位,“pfxddi”对应“caesar”用的是13、5、19、11、3、7位,这些规律其实就是每一位字母分别按照不同的质数位数进行前移(字母表循环,A=1, …, Z=26)。比如“ypgm”每位分别前移2、7、13、5位后,就能解出“WITH”。结合前面的密文结构,猜测前四个单词有可能是“easy”。整个过程的核心思路就是按照对应的质数,分别对每一位字母做位移变换。
flag{easy_caesar_with_multiple_shifts_2025}
数据安全
1.AES_Custom_Padding
1 | 背景:某系统对备份数据使用 AES-128-CBC 加密,但采用了自定义填充: |
1 | from Cryptodome.Cipher import AES |
b'flag{T1s_4ll_4b0ut_AES_custom_padding!}\x80'
2.DB_Log
1 | 本题目模拟企业数据库安全审计场景,需要分析数据库操作日志,检测违反企业安全政策的异常行为。系统包含4个部门(HR、Finance、IT、Sales)的权限管理,每个部门只能访问特定的数据表。 |
database局部:
用户许可:

解题代码:
1 | import hashlib |
输出结果:
1 | 读取用户权限文件... |
flag{1ff4054d20e07b42411bded1d6d895cf}
3.SQLi_Detection
1 | import re |
4.ACL_Allow_Count
1 | deny tcp any any 23 |
1 | tcp 39.128.113.192 7.244.88.218 53 |
1 | ACL 规则匹配与允许条数统计 |
解题代码:
1 | import ipaddress |
flag{1729}
5.JWT_Weak_Secret
1 | 题目描述 |
解题代码:
1 | import jwt |
flag{1:3:4:5:9:14:15:17:19:20:21:24:27:28}
6.Brute_Force_Detection
1 | from datetime import datetime, timedelta |
检测到暴力破解迹象的IP:192.168.3.13, 192.168.5.15
最终Flag:
flag{192.168.3.13:192.168.5.15}
逆向
1.EasyRE
1 | int __fastcall main(int argc, const char argv, const char envp) |
其中:
1 | char __fastcall sub_140001070(__int64 a1, int a2, _BYTE *a3) |
所以这是rc4加密:
1 | def rol8(x, shift): |
十六进制结果: 666C61677B546831735F31735F415F466C347733645F4372797074307D
ASCII 表示: flag{Th1s_1s_A_Fl4w3d_Crypt0}
原始字节: b’flag{Th1s_1s_A_Fl4w3d_Crypt0}‘
2.cookie
1 | import struct |
去除花指令即可
杂项
1.ModelUnguilty
1 | import pandas as pd |
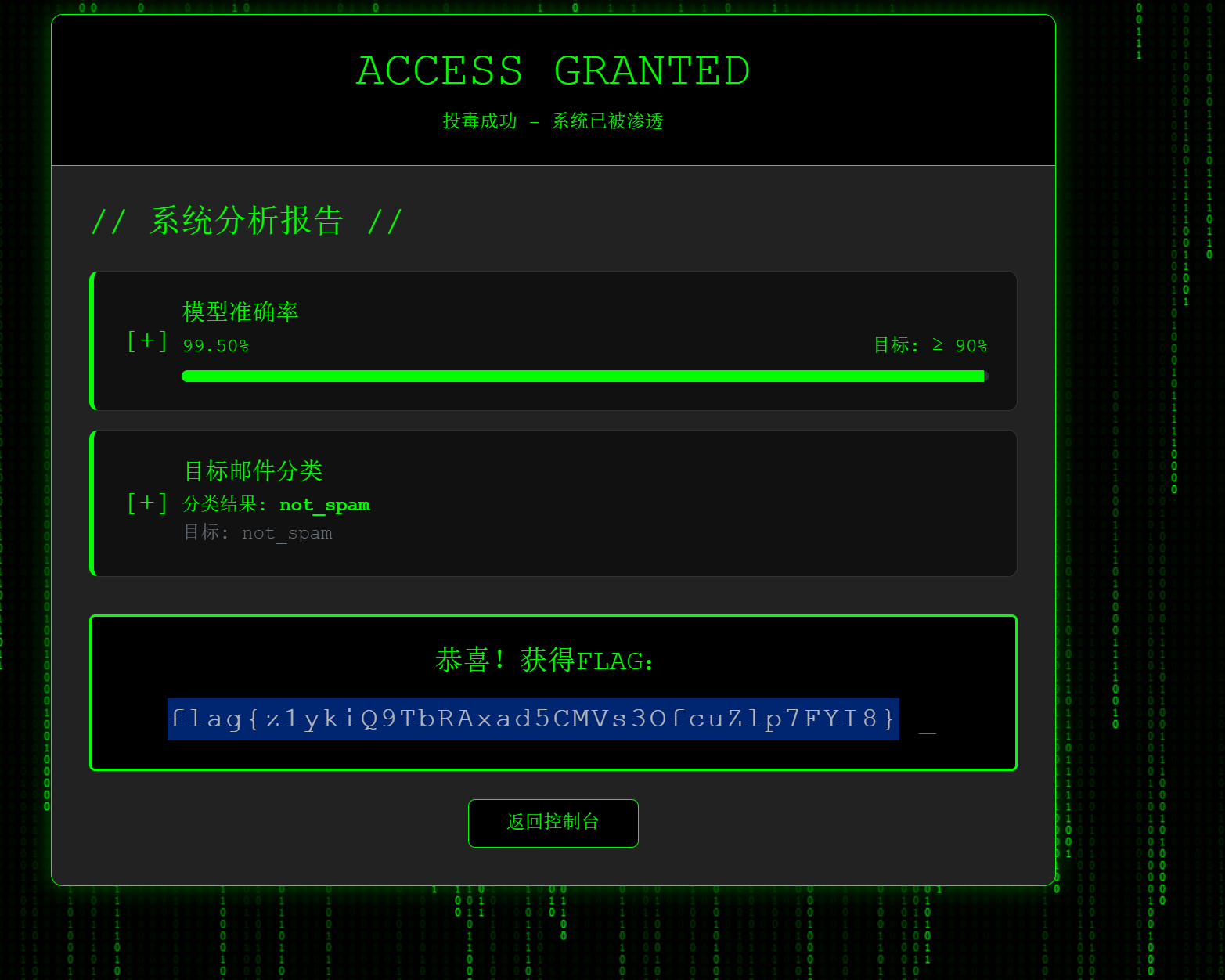
2.easy_misc
ezmisc
直接打开来是个缺定位角的二维码
手动补齐
FAKE_FLAG{nizenmezhemeshuliana!}
好被骗了
导入tweakpng看看,发现下图
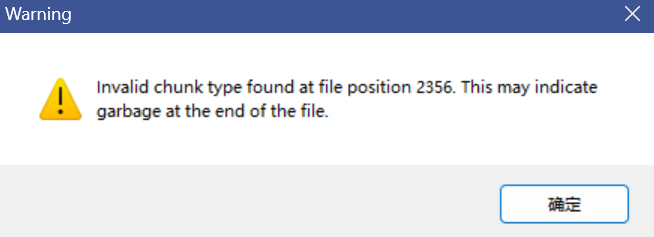
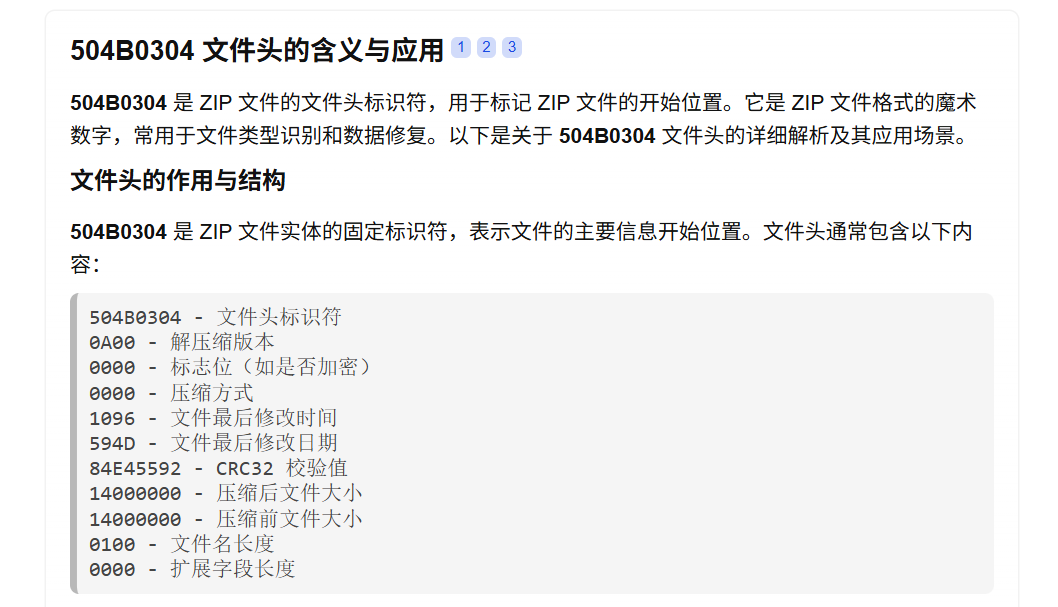
在文件的位置 2356 处发现了一个无效的数据块类型(chunk type),这可能是文件末尾存在无用的垃圾数据导致的。
找到2356处
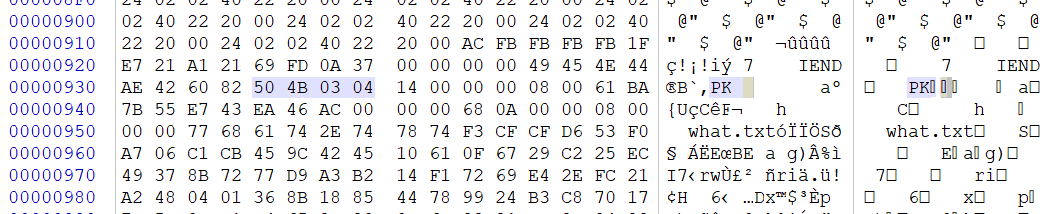
有个压缩包
分离
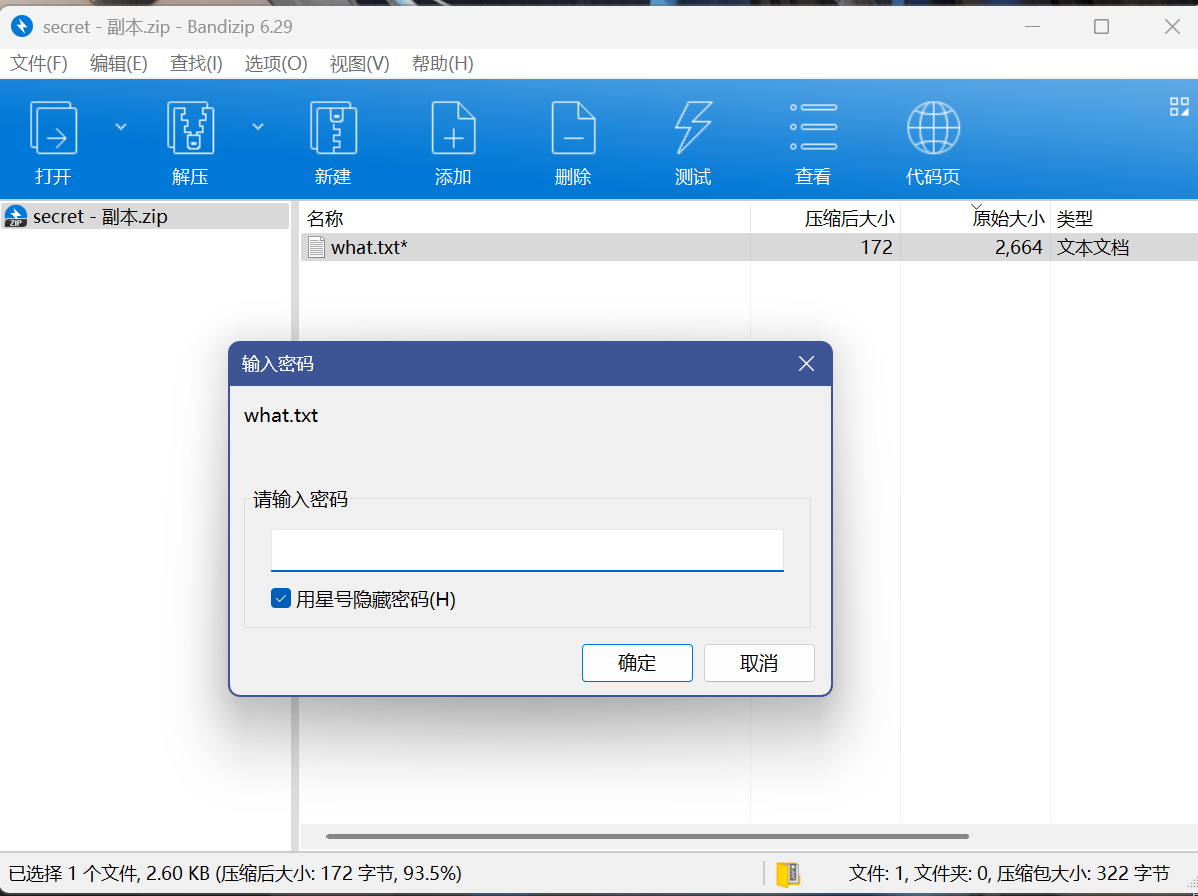
发现还是个txt文件
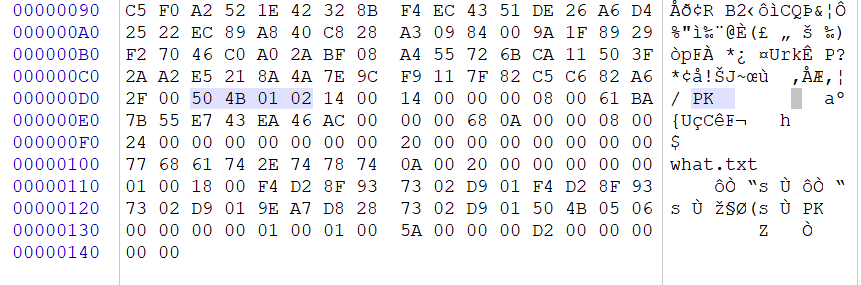
怀疑是伪加密,成功破解

打开如上,显然为Ook编码
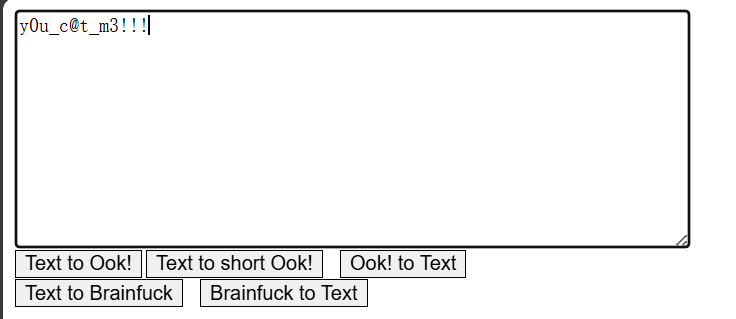
解得如上y0u_c@t_m3!!!
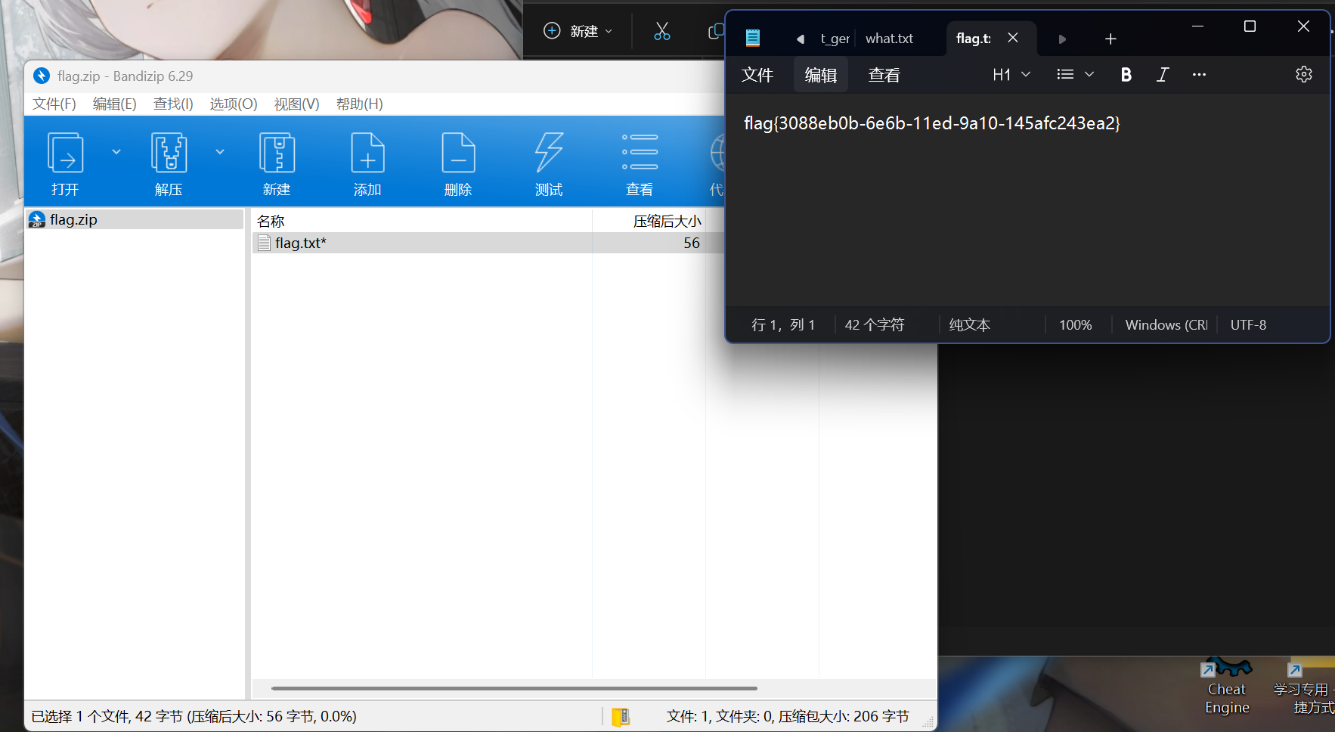
然后即可打开,答案为flag{3088eb0b-6e6b-11ed-9a10-145afc243ea2}
web
查看源代码有个js文件
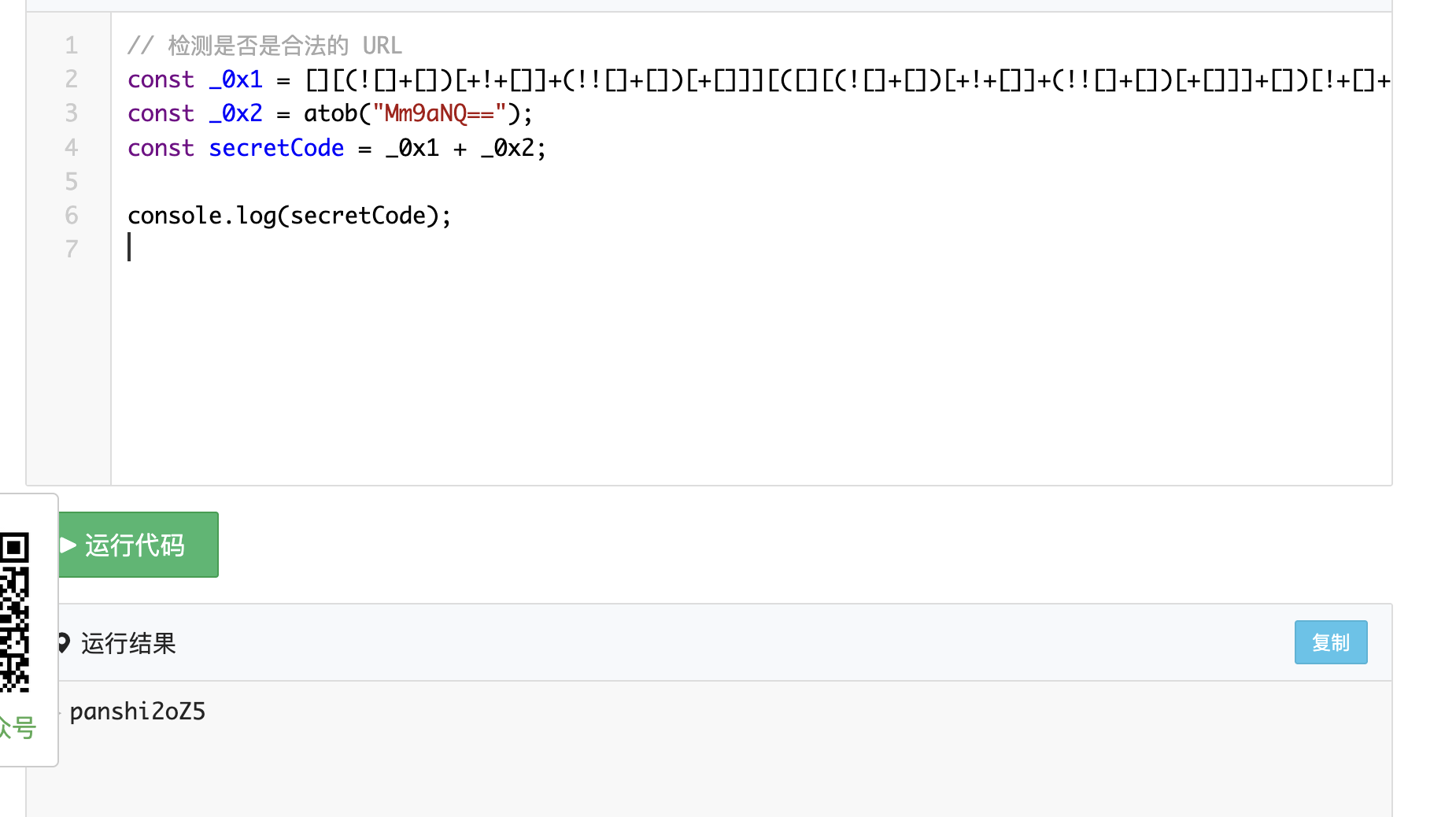
抓包修改step为3然后数据改为这个panshi2oZ5