22 在A市发生了一起贩卖假烟案,警方已掌握了贩卖团伙中的5位嫌疑人,并调取了他们的手机通讯数据,现想通过分析他们的通话情况挖掘出更多参与假烟贩卖的其他人员,请根据提供的数据进行分析研判,完成以下问题:
5位嫌疑人的手机号分别是:
1397748
1389744
1514398
1393593
1363489
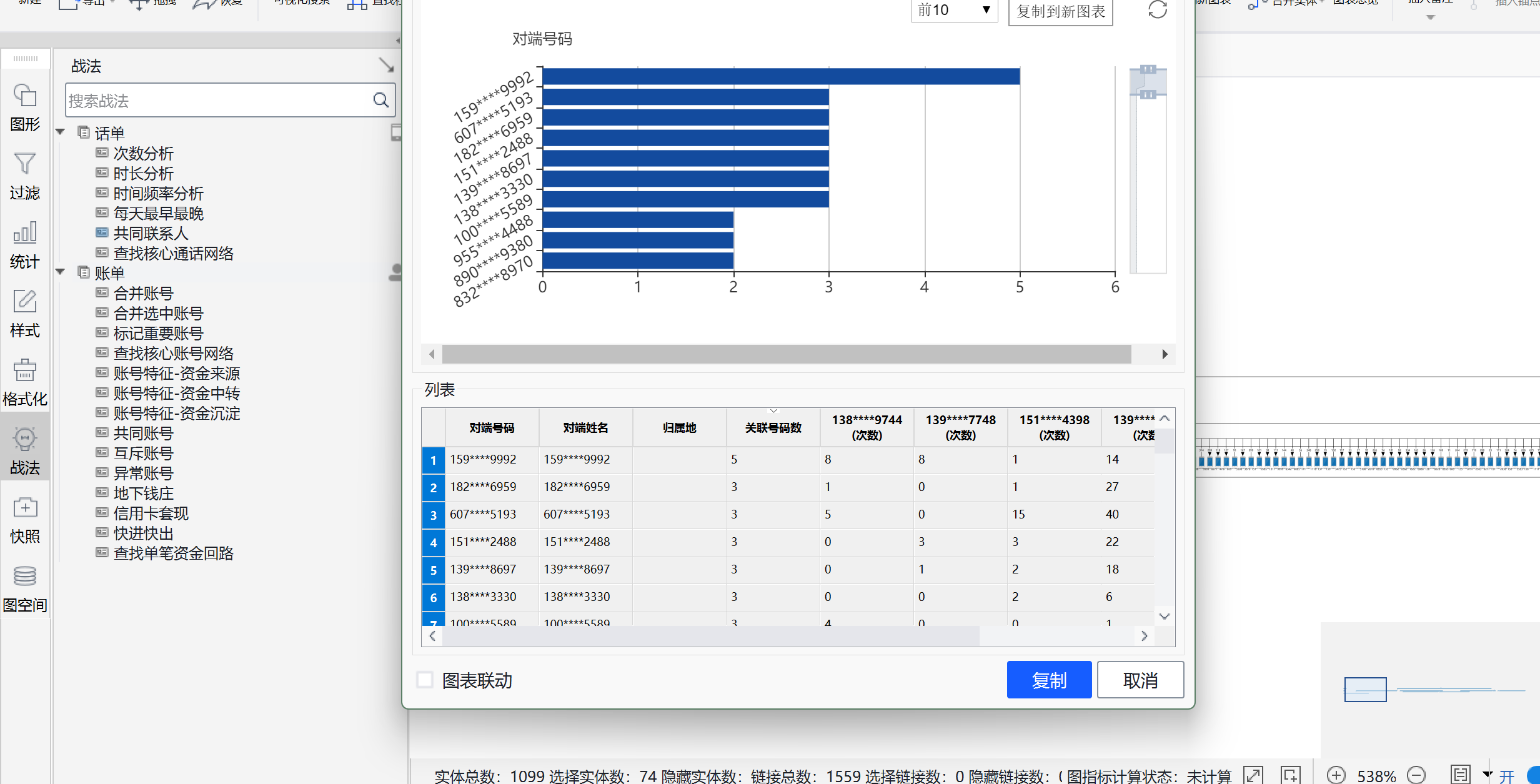
(1)请问和5位嫌疑人中任意3个及以上嫌疑人发生过通话关系的对方号码有哪些?(填写手机号) (8分)
导入ai之后有共同联系人分析即可
(2)请问在夜间22:00-6:00期间通话总时长最长的已知嫌疑人是谁?在此期间与该已知嫌疑人通话总时长最长的对方号码又是谁?(填写手机号)(6分)
# 题目
# 答题区
# 在夜间22:00-6:00期间通话总时长最长的已知嫌疑人是谁?
# 在此期间与该已知嫌疑人通话总时长最长的对方号码又是谁?
“”E:\大数据\比赛\智器云模拟\22\第22题数据.xlsx”这是文件地址,结果输出到”E:\大数据\比赛\智器云模拟\22””
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 import pandas as pd # 读取Excel文件 df = pd.read_excel(r'E:\大数据\比赛\智器云模拟\22\第22题数据.xlsx', sheet_name='Sheet1') # 转换通话时间为datetime格式 df['通话时间'] = pd.to_datetime(df['通话时间']) # 提取通话时间中的小时 df['通话小时'] = df['通话时间'].dt.hour # 筛选夜间通话记录(22:00-06:00) night_mask = (df['通话小时'] >= 22) | (df['通话小时'] < 6) night_calls = df[night_mask].copy() # 将通话时长转换为数值型 night_calls['通话时长'] = pd.to_numeric(night_calls['通话时长'], errors='coerce') # 按嫌疑人号码分组计算总通话时长 night_call_sums = night_calls.groupby('本方号码')['通话时长'].sum().reset_index() # 找到通话时长最大的嫌疑人 longest_night_caller = night_call_sums.loc[night_call_sums['通话时长'].idxmax()] # 输出结果 print("="*60) print(f"夜间通话时长最长的嫌疑人号码: {longest_night_caller['本方号码']}") print(f"总夜间通话时长(秒): {longest_night_caller['通话时长']:.0f}") print("="*60) # 详细数据输出 print("\n所有嫌疑人的夜间通话总时长统计:") print(night_call_sums.sort_values('通话时长', ascending=False))
“请问在夜间22:00-6:00期间通话总时长最长的已知嫌疑人是谁?
1读取excel中“通话时间”(例如2023-09-09 15:40:50,读取里面的小时分钟,筛选出22:00-6:00),计算总计时长
给我筛选代码”
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 import pandas as pd # 1. 读取Excel文件 df = pd.read_excel(r'E:\大数据\比赛\智器云模拟\22\第22题数据.xlsx', sheet_name='Sheet1') # 2. 处理通话时间列 df['通话时间'] = pd.to_datetime(df['通话时间'], errors='coerce') df['通话小时'] = df['通话时间'].dt.hour # 3. 筛选特定嫌疑人的夜间通话记录(1393593在22:00-6:00期间) target_suspect = '1393593' night_calls = df[ (df['本方号码'] == target_suspect) & ((df['通话小时'] >= 22) | (df['通话小时'] < 6)) ].copy() # 4. 确保通话时长为数值类型 night_calls['通话时长'] = pd.to_numeric(night_calls['通话时长'], errors='coerce') # 5. 按对方号码分组并计算总通话时长 partner_duration = night_calls.groupby('对方号码')['通话时长'].sum().reset_index() # 6. 找出通话总时长最长的对方号码 if not partner_duration.empty: max_duration_row = partner_duration.loc[partner_duration['通话时长'].idxmax()] top_partner = max_duration_row['对方号码'] total_duration = max_duration_row['通话时长'] # 7. 输出结果 print("=" * 50) print(f"与嫌疑人 {target_suspect} 在夜间通话最频繁的对方号码") print("=" * 50) print(f"对方号码: {top_partner}") print(f"总通话时长: {total_duration:.0f} 秒") print(f"通话次数: {len(night_calls[night_calls['对方号码'] == top_partner])}") # 输出详细统计 print("\n所有与嫌疑人通话的对方号码及其总时长:") print(partner_duration.sort_values('通话时长', ascending=False).reset_index(drop=True)) else: print(f"嫌疑人 {target_suspect} 在夜间没有通话记录")
(3)请问与1389744和1363489这两个已知嫌疑人共同通话总次数最多的密切联系对方号码是谁(填写手机号)?这两个嫌疑号码跟该密切联系对手发生通话时最常在哪个基站大区号下(填写基站大区号)?(6分)
# 题目
# 答题区
# 与1389744和136
# 这两个嫌疑号码跟该密切联系对手发生通话时最常在哪个基站大区号下?
(4)有人举报在2023年9月1日(含)至9月30日(含)期间,有嫌疑人在“基站大区号:21088,基站小区号:16427”的位置区域内进行线下交易,请根据通话数据找出疑似参与线下交易的已知嫌疑人有哪些,并统计他们期间在该位置区域的联系对手分别有多少个?(填写手机号和通话对手数量)(5分) 23. 近日,某地一家大型银行反洗钱部门发现部分银行账户在近期交易金额成倍增长,交易次数暴增,资金流动异常,遂将线索移交至本地经侦部门,请根据提供的数据进行分析研判,完成以下问题:
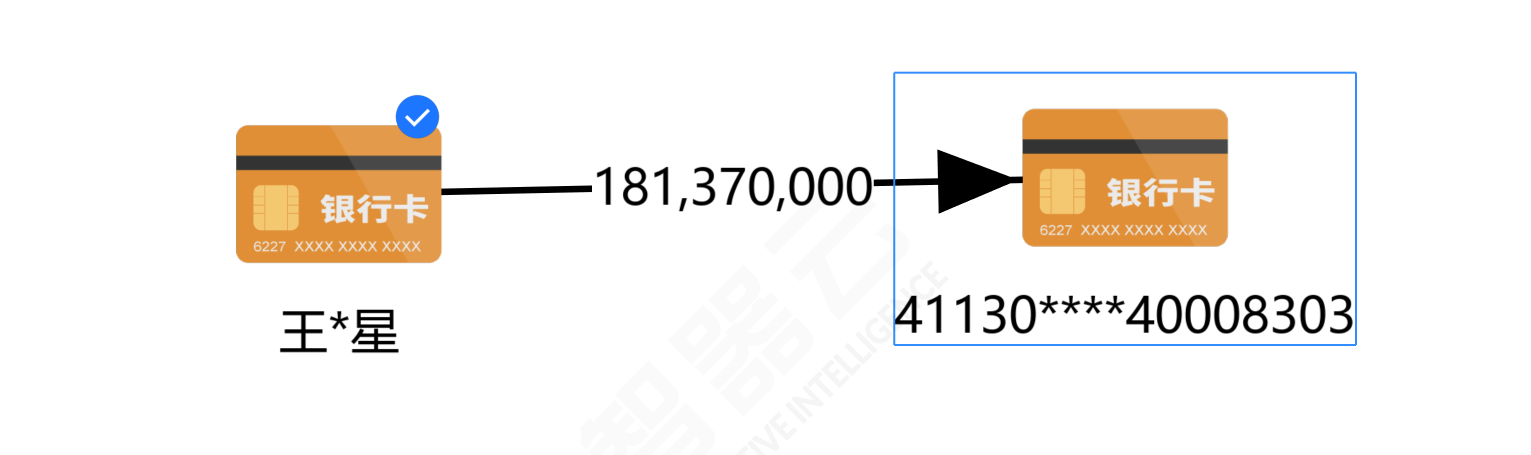
(1)找出嫌疑人梁*坤(卡号:62262 8369212)的最大资金来源账户与最大资金去向账户。(填写银行卡号)(8分) “找出嫌疑人梁坤(“客户名称”=梁 坤)(卡号:622628369212(查询卡号=622628369212))的最大资金来源账户(“借贷标志”=进)与最大资金去向账户(“借贷标志”=出)。(填写银行卡号)
地址=”E:\大数据\比赛\智器云模拟\23\第23题数据.xlsx”
给我筛选代码(py pandas库)”
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 import pandas as pd # 读取Excel文件 file_path = r"E:\大数据\比赛\智器云模拟\23\第23题数据.xlsx" df = pd.read_excel(file_path, sheet_name='Sheet1') # 筛选梁*坤且卡号为62262****8369212的所有交易记录 suspect_trans = df[ (df['客户名称'] == '梁*坤') & (df['查询卡号'] == '62262****8369212') ] # 筛选资金来源账户(借贷标志为“进”) in_trans = suspect_trans[suspect_trans['借贷标志'] == '进'] # 筛选资金去向账户(借贷标志为“出”) out_trans = suspect_trans[suspect_trans['借贷标志'] == '出'] # 按交易对方卡号分组,计算总交易金额 in_grouped = in_trans.groupby('交易对方卡号')['交易金额'].sum().reset_index() out_grouped = out_trans.groupby('交易对方卡号')['交易金额'].sum().reset_index() # 找出最大资金来源账户(进) if not in_grouped.empty: max_in = in_grouped.loc[in_grouped['交易金额'].idxmax()] max_in_card = max_in['交易对方卡号'] else: max_in_card = "无交易记录" # 找出最大资金去向账户(出) if not out_grouped.empty: max_out = out_grouped.loc[out_grouped['交易金额'].idxmax()] max_out_card = max_out['交易对方卡号'] else: max_out_card = "无交易记录" print(f"最大资金来源账户(进)银行卡号: {max_in_card}") print(f"最大资金去向账户(出)银行卡号: {max_out_card}")
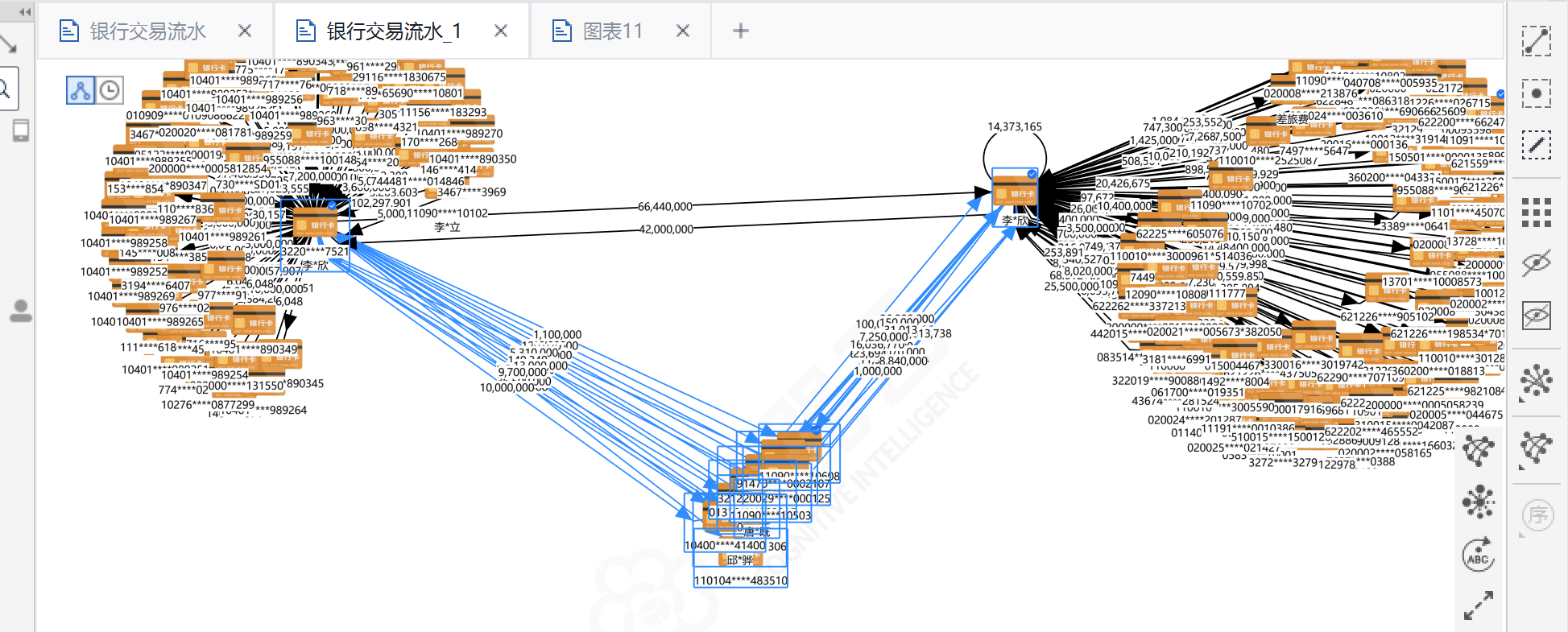
(2)请问哪些银行卡同时接收过李欣名下两张卡的钱且没有给李 欣任何一张银行卡转过钱?(填写银行卡号)(10分) 转出转入筛选李*欣,有两张卡: **3220****7521**、 **020024****122707**
可视化图也可以看到,复制出来两张卡都有交易信息的,然后筛选即可
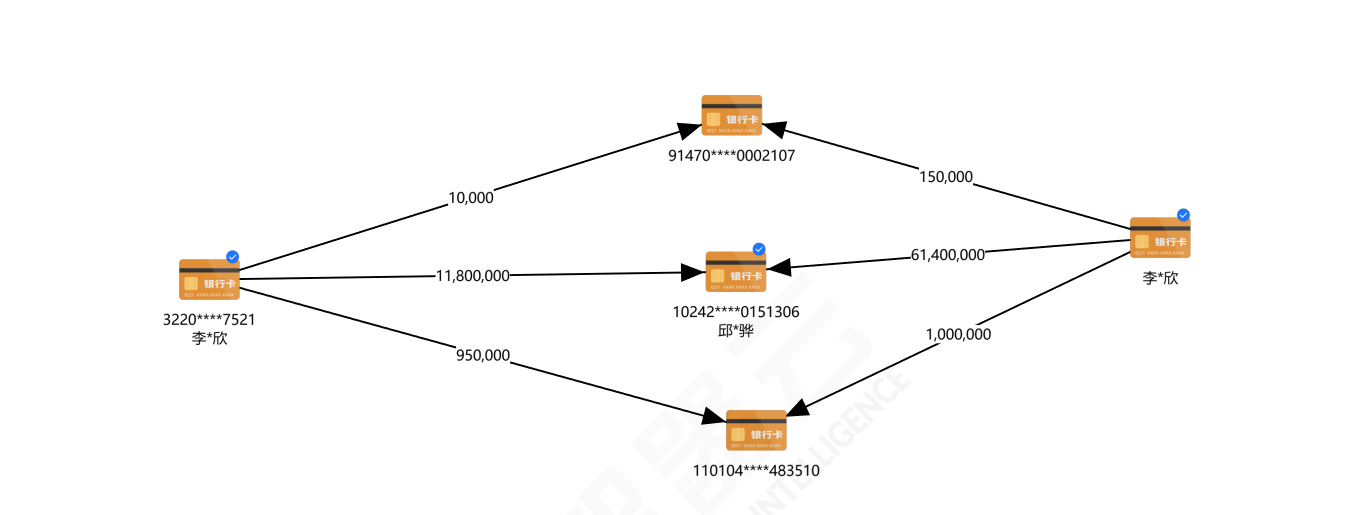
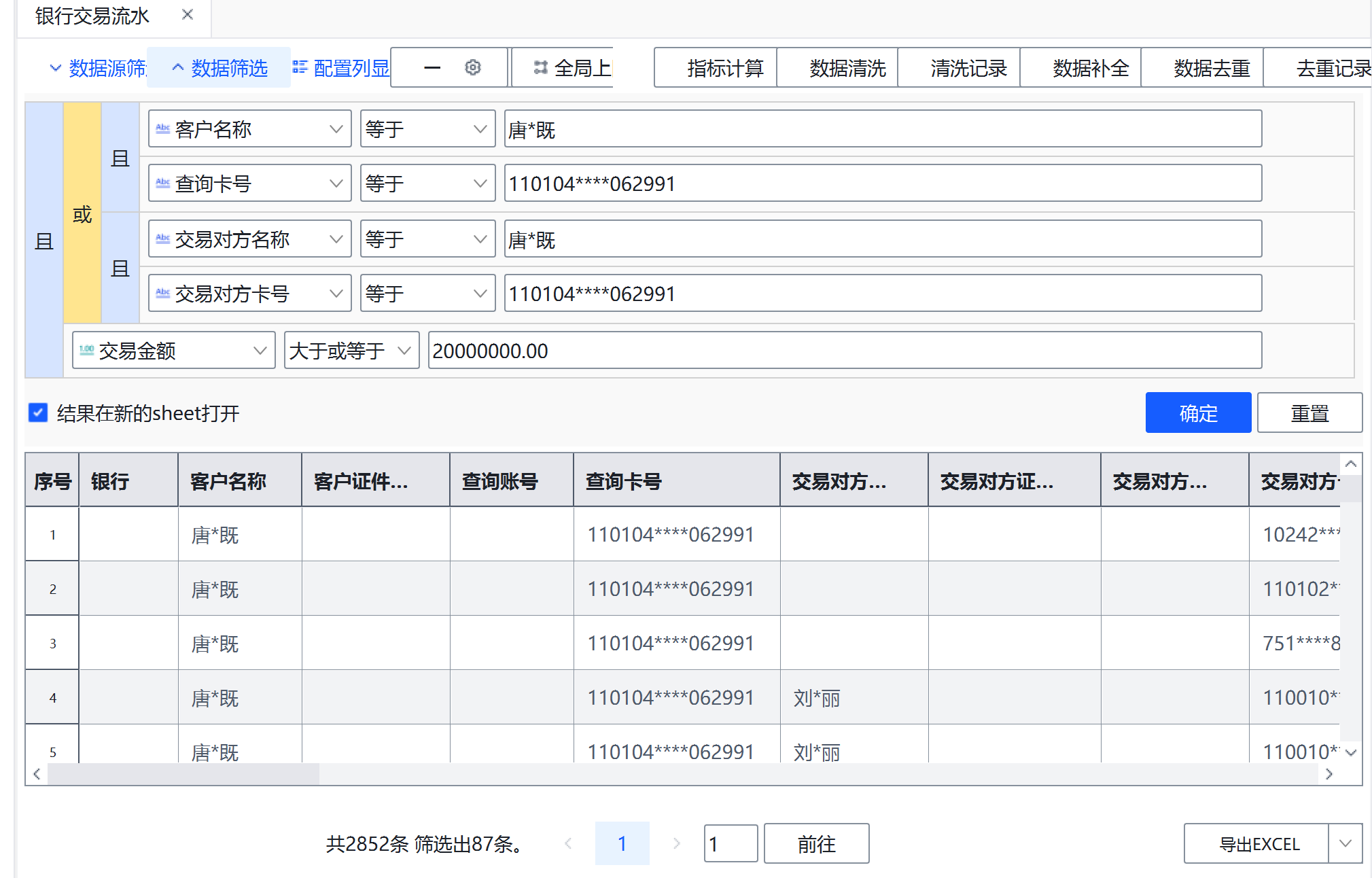
(3)在本案中,需追踪大额可疑资金的最终去向。以唐*既110104 062991的银行卡为1级卡,追踪1级卡的大额资金去向账户(流入金额÷交易总金额≥80%且流入金额在 2000万及以上)作为2级卡,再继续追踪2级卡的大额资金去向账户(流入金额÷交易总金额≥80%且流入金额在 2000万及以上)作为3级卡,请找出满足上述条件的3级卡有哪些?(填写银行卡号)(6分) 筛选出2级卡:1992****5448&110010****3018090&20029****000125
## 110010****3018090
## 1992****5448
## 20029****000125
## 020305****001192
三级卡筛完就剩一张卡了。。
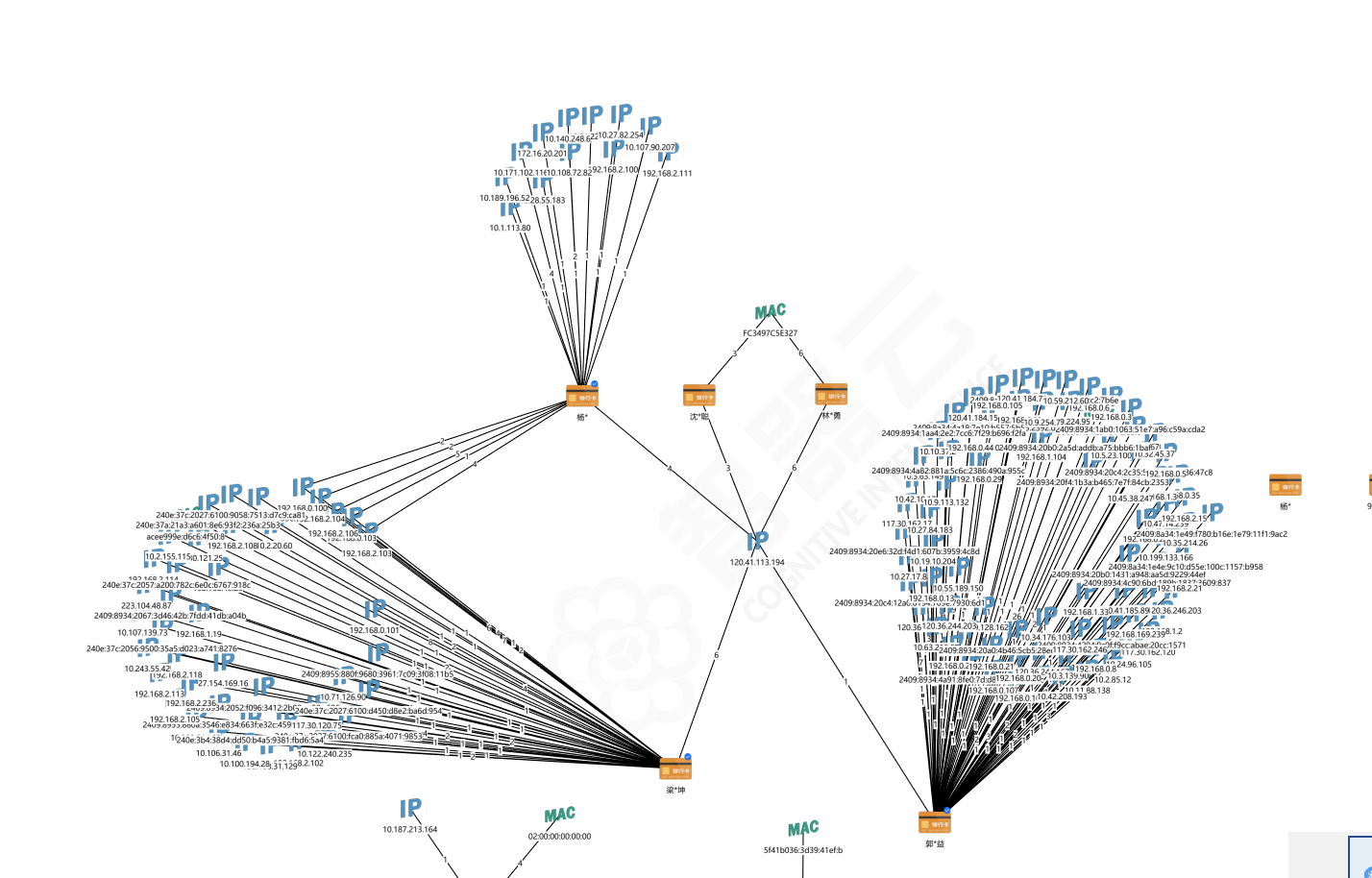
(4)资金分析中常常通过共用IP或MAC找可疑团伙,该案件中的银行卡若同时满足以下2个条件:①银行卡在相同IP或MAC地址上登陆过(相同IP或MAC地址:该IP或 MAC 地址至少关联2张及以上银行卡);②银行卡至少在该IP或MAC地址上登陆过2次及以上。则将这些银行卡视为同一团伙所控制,请问同时满足以上2个条件的银行卡有哪些?(填写银行卡号)(6分) 数据上图,然后根据这个图片分析
根据题目要求来看其实就是筛选中间这个ip120.41.113.194
就这两张卡登录了多次
24 在某件正在侦办的涉黄案件中,警方已掌握了涉黄团伙中 3 位专门用于接收嫖资的嫌疑人的微信号并调取了相关微信交易数据,请根据提供的数据进行下一步的分析,完成以下问题:
已知的 3位嫌疑人微信账号分别是:
L13315704334
liqin13145209
y1298477937
(1)根据嫖客账号特征:①交易时间在晚上22点到凌晨6点;②向已知嫌疑账户转过钱,且单笔交易金额在200元(含)到300元(含)之间。请找出同时满足以上2个条件的对手微信账号,即有可能为嫖客账号。(填写微信账号)(5分) 先用ai跑一个分离小时的代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 import pandas as pd # 读取Excel文件 file_path = r"E:\大数据\比赛\智器云模拟\第24题数据.xlsx" df = pd.read_excel(file_path, sheet_name='Sheet1') # 确保列名正确(处理可能的前后空格) df.columns = [col.strip() for col in df.columns] # 找到接收时间列的位置 # Q列对应索引位置16(0-based),列名应为'接收时间' try: # 尝试通过列名定位 receive_time_idx = df.columns.get_loc('接收时间') except KeyError: # 如果列名不存在,使用位置索引(第17列) receive_time_idx = 16 # 转换接收时间为datetime格式 df['接收时间'] = pd.to_datetime(df.iloc[:, receive_time_idx], errors='coerce') # 提取小时并创建新列 df['接收小时'] = df['接收时间'].dt.hour # 将新列插入到接收时间列后面 col_position = receive_time_idx + 1 df.insert(col_position, '接收小时', df.pop('接收小时')) # 保存处理后的数据到新文件 output_path = r"E:\大数据\比赛\智器云模拟\第24题数据_处理后.xlsx" df.to_excel(output_path, index=False) print("处理完成!新文件已保存至:", output_path)
接下来按照题目的要求筛选:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 import pandas as pd # 读取处理后的Excel文件 file_path = r"E:\大数据\比赛\智器云模拟\第24题数据_处理后.xlsx" df = pd.read_excel(file_path) # 筛选条件: # 1. 接收小时在22点到凌晨6点之间(包含22点和6点) # 2. 借贷标志为"进" # 3. 交易金额在200-300之间(包含边界值) # 创建筛选条件 condition = ( # 接收小时在22-23点或0-6点之间 ((df['接收小时'] >= 22) & (df['接收小时'] <= 23)) | ((df['接收小时'] >= 0) & (df['接收小时'] <= 6)) ) & ( # 借贷标志为"进" df['借贷标志'] == '进' ) & ( # 交易金额在200-300之间 (df['交易金额'] >= 200) & (df['交易金额'] <= 300) ) # 应用筛选条件 filtered_df = df[condition] # 保存筛选结果到新文件 output_path = r"E:\大数据\比赛\智器云模拟\第24题数据_筛选结果.xlsx" filtered_df.to_excel(output_path, index=False) print(f"筛选完成!共找到 {len(filtered_df)} 条符合条件的记录") print(f"结果已保存至: {output_path}") # 如果需要查看筛选结果的前几行 print("\n筛选结果前5行预览:") print(filtered_df.head())
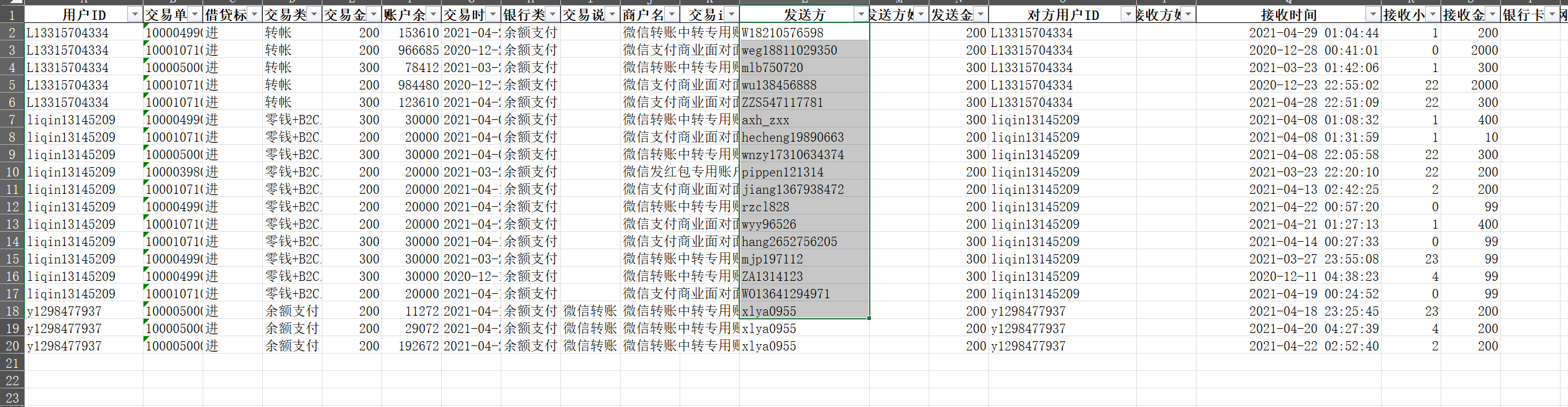
(2)根据卖淫组织中介账号特征:①接收已知嫌疑账户资金转入,且累计接收3位嫌疑人转入交易总金额在10000元(含)以上;②接收过3位嫌疑人中任意2位及以上资金转入的账户。请找出同时满足以上2个条件的对手微信账号,即有可能为中介账号。(填写微信账号)(5分) 微信账号
…
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 import pandas as pd # 读取处理后的Excel文件 file_path = r"E:\大数据\比赛\智器云模拟\第24题数据_处理后.xlsx" df = pd.read_excel(file_path) # 1. 获取所有嫌疑用户ID(用户ID列) suspect_ids = df['用户ID'].unique().tolist() # 2. 筛选相关交易记录: # - 借贷标志为"出"(嫌疑用户转出) # - 交易对手是微信账号(根据实际情况可能需要调整) suspect_transactions = df[ (df['借贷标志'] == '出') & (df['用户ID'].isin(suspect_ids)) ] # 3. 按对手微信账号分组统计 # - 统计接收的不同嫌疑人数量 # - 计算累计接收金额 result = suspect_transactions.groupby('对手微信账号').agg( suspect_count=('用户ID', 'nunique'), # 不同嫌疑人数量 total_amount=('交易金额', 'sum') # 累计接收金额 ).reset_index() # 4. 应用筛选条件 # 条件①:接收≥3位不同嫌疑人且总金额≥10,000元 # 条件②:接收≥2位不同嫌疑人(已隐含在条件①中) intermediary_accounts = result[ (result['suspect_count'] >= 3) & (result['total_amount'] >= 10000) ] # 5. 输出结果 print(f"找到 {len(intermediary_accounts)} 个可能的中介账号:") print(intermediary_accounts[['对手微信账号', 'suspect_count', 'total_amount']]) # 保存结果到Excel output_path = r"E:\大数据\比赛\智器云模拟\中介账号分析结果.xlsx" intermediary_accounts.to_excel(output_path, index=False) print(f"\n结果已保存至: {output_path}")
25 在一起跨境网赌案件中,某地警方发现辖区内有人在某赌博APP上参与赌博,并推广发展其他赌客获利,立案后,警方通过技术渗透得到了网赌平台的后台代理数据,请根据提供的后台代理数据进行分析:
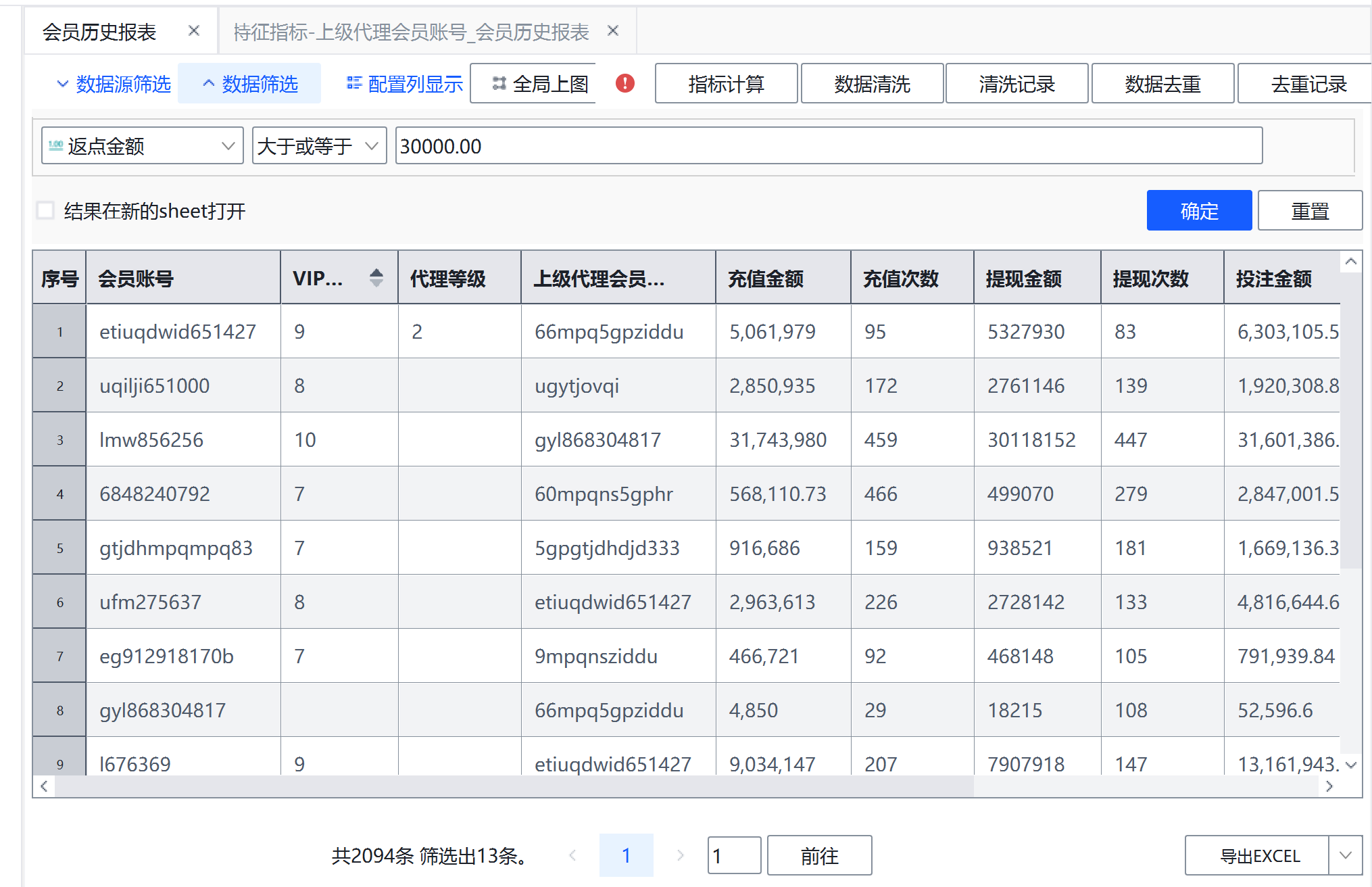
(1)请问返点金额在3万元及以上代理会员有哪些?每个账号的返点金额是多少(四舍五入,保留至小数点后两位)?(填写会员账号和返点金额)(6分)
筛选即可
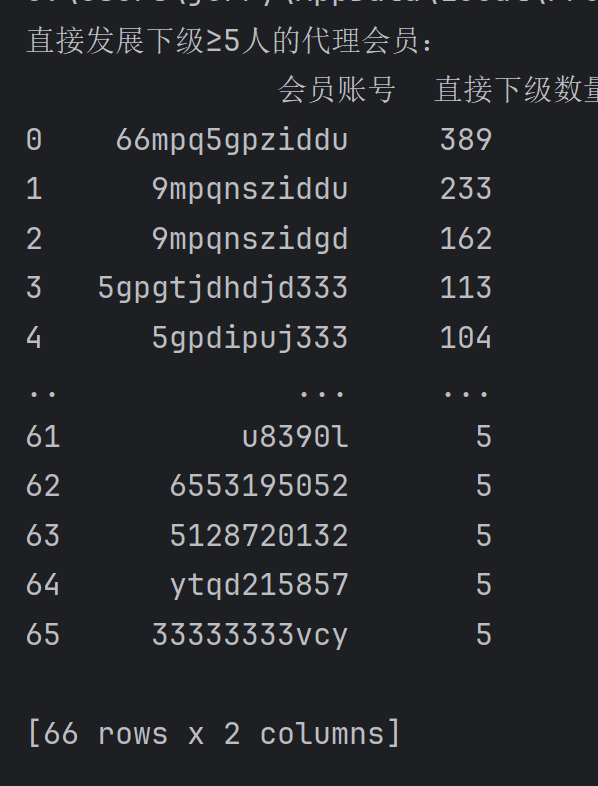
(2)对代理推荐关系进行分析,请问直接发展下级会员数量在5人及以上的会员有哪些?这些会员账号发展的直接下级数量有多少个?(填写会员账号及其发展的直接下级数量)(6分) “对代理推荐关系进行分析,请问直接发展下级会员数量在5人及以上的会员有哪些?这些会员账号发展的直接下级数量有多少个?(填写会员账号及其发展的直接下级数量)
我的思路是:1.读取D列“上级代理会员账号”,统计每个账号出现的次数,并输出到心表格中,给我对应的py代码(pandas库)
地址是”E:\大数据\比赛\智器云模拟\第25题数据\会员历史报表.xlsx””
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import pandas as pd # 读取Excel文件 file_path = r"E:\大数据\比赛\智器云模拟\第25题数据\会员历史报表.xlsx" df = pd.read_excel(file_path, sheet_name='Sheet1') # 统计每个上级代理会员账号出现的次数(即其直接下级数量) direct_subordinate_counts = df['上级代理会员账号'].value_counts().reset_index() direct_subordinate_counts.columns = ['会员账号', '直接下级数量'] # 筛选直接下级数量≥5的会员 result = direct_subordinate_counts[direct_subordinate_counts['直接下级数量'] >= 5] # 按直接下级数量降序排列 result_sorted = result.sort_values(by='直接下级数量', ascending=False) # 打印结果 print("直接发展下级≥5人的代理会员:") print(result_sorted) # 可选:保存结果到新文件 result_sorted.to_excel('下级数量统计结果.xlsx', index=False)
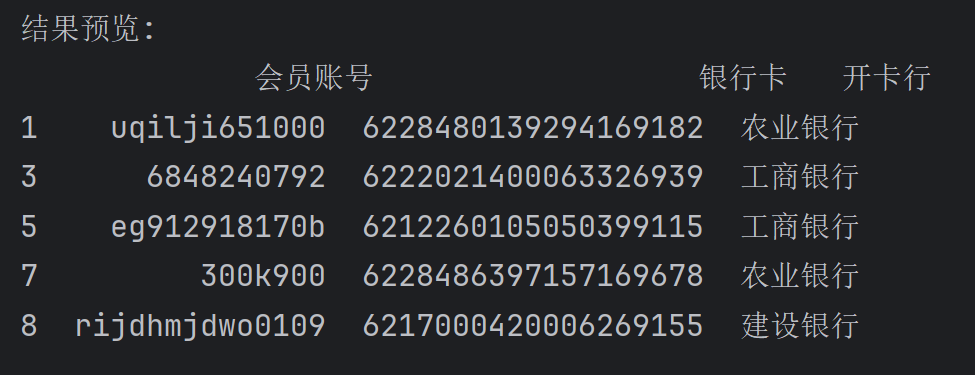
(3)结合第(1)问和第(2)问的结果,请问返点金额在3万元及以上、直接发展下级会员数量在5人及以上且最后登录时间在2023年1月1日(含)后,有银行卡信息的会员有哪些?(填写会员账号及其对应的卡号和开卡行)(3分) “题目:结合第(1)问和第(2)问的结果,请问返点金额在3万元及以上、直接发展下级会员数量在5人及以上且最后登录时间在2023年1月1日(含)后,有银行卡信息的会员有哪些?(填写会员账号及其对应的卡号和开卡行)(3分)
1.我的思路是先读取大于三万的表格”E:\大数据\比赛\智器云模拟\第25题数据\大于3万.xlsx”,记住“会员账号”之后再在”E:\大数据\比赛\智器云模拟\第25题数据\下级数量统计结果.xlsx”的“会员账号”找到对应的会员,最后在”E:\大数据\比赛\智器云模拟\第25题数据\会员详情表.xlsx”中找到前两个文档重叠的会员,最后再筛选出“最后登录时间”在2023-1-1后的数据(“最后登录时间”的示例是:2023-03-19 14:02:12),给我py代码”
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 import pandas as pd from datetime import datetime # 读取三个数据文件 # 1. 返点金额≥3万的会员 rebate_df = pd.read_excel(r"E:\大数据\比赛\智器云模拟\第25题数据\大于3万.xlsx") # 2. 直接下级≥5人的会员 subordinate_df = pd.read_excel(r"E:\大数据\比赛\智器云模拟\第25题数据\下级数量统计结果.xlsx") # 3. 会员详情表 detail_df = pd.read_excel(r"E:\大数据\比赛\智器云模拟\第25题数据\会员详情表.xlsx") # 确保列名一致(去除前后空格) for df in [rebate_df, subordinate_df, detail_df]: df.columns = df.columns.str.strip() # 找出同时满足返点金额≥3万和下级≥5人的会员 # 取两个数据集的交集 common_members = pd.merge( rebate_df[['会员账号']], subordinate_df[['会员账号']], on='会员账号', how='inner' ) # 从会员详情表中提取这些会员的详细信息 result_df = pd.merge( common_members, detail_df, on='会员账号', how='left' ) # 筛选最后登录时间在2023-01-01之后的数据 # 将最后登录时间转换为datetime格式 result_df['最后登录时间'] = pd.to_datetime(result_df['最后登录时间']) # 设置筛选日期 cutoff_date = datetime(2023, 1, 1) # 应用时间筛选条件 result_df = result_df[result_df['最后登录时间'] >= cutoff_date] # 筛选有银行卡信息的会员(假设银行卡号和开卡行列都存在) # 需要根据实际列名调整 result_df = result_df[ result_df['银行卡'].notna() & result_df['开卡行'].notna() ] # 选择需要的列(会员账号、银行卡号、开卡行) final_result = result_df[['会员账号', '银行卡', '开卡行']] # 保存结果 output_path = r"E:\大数据\比赛\智器云模拟\第25题数据\最终结果.xlsx" final_result.to_excel(output_path, index=False) print("筛选完成!结果已保存至:", output_path) print("符合条件的会员数量:", len(final_result)) print("\n结果预览:") print(final_result.head())
26 2020年7月10日,某市发生一起盗窃案件,根据排查,警方掌握了嫌疑人高某霞和其关系圈的其他可疑人员,现已调取了以上嫌疑人的酒店住宿和铁路出行记录,请根据调取的酒店住宿信息和铁路出行数据完成以下分析:
(1)请分析在2020年6月27日(含)至2020年7月27日(含)期间,与高某霞入住过同一家酒店且入住时间间隔在3天以内(含3天)的人员有哪些?(填写身份证号和姓名)(5分) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 import pandas as pd import numpy as np # 读取Excel文件,指定身份证号列为字符串类型 file_path = r"E:\大数据\比赛\智器云模拟\第26题数据\云搜-酒店入住数据.xlsx" df = pd.read_excel(file_path, dtype={'证件号码': str}) # 将日期列转换为datetime类型 df['入住时间'] = pd.to_datetime(df['入住时间']) df['离店时间'] = pd.to_datetime(df['离店时间']) # 筛选指定日期范围内的数据 start_date = pd.Timestamp('2020-06-27') end_date = pd.Timestamp('2020-07-27') df_period = df[(df['入住时间'] >= start_date) & (df['入住时间'] <= end_date)] # 获取高某霞在指定时间段内的入住记录 gao_records = df_period[df_period['姓名'] == '高某霞'] # 创建空列表保存结果 results = [] # 分析每一条高某霞的入住记录 for _, gao_row in gao_records.iterrows(): # 获取当前高某霞入住信息 hotel_name = gao_row['旅店名称'] # 修改为"旅店名称" gao_id_card = gao_row['证件号码'] # 修改为"证件号码" gao_checkin = gao_row['入住时间'] # 筛选同一酒店的记录 same_hotel = df_period[df_period['旅店名称'] == hotel_name] # 修改为"旅店名称" # 筛选时间间隔在3天以内的人员(排除高某霞自己) for _, row in same_hotel.iterrows(): # 排除高某霞本人 if row['证件号码'] == gao_id_card: # 修改为"证件号码" continue # 计算入住时间差(绝对值) time_diff = abs((row['入住时间'] - gao_checkin).days) # 如果时间差在3天以内,记录结果 if time_diff <= 3: results.append({ '证件号码': row['证件号码'], # 修改为"证件号码" '姓名': row['姓名'], '旅店名称': hotel_name, # 修改为"旅店名称" '高某霞入住时间': gao_checkin.strftime('%Y-%m-%d'), '相关人员入住时间': row['入住时间'].strftime('%Y-%m-%d'), '时间差(天)': time_diff }) # 创建结果DataFrame if results: results_df = pd.DataFrame(results) # 按证件号码去重 results_df = results_df.drop_duplicates(subset=['证件号码']) # 按证件号码排序 results_df = results_df.sort_values('证件号码') # 确保身份证号以文本格式显示 results_df['证件号码'] = results_df['证件号码'].astype(str) # 打印结果 print("与高某霞同住旅店且时间间隔3天内的人员:") print(results_df[['证件号码', '姓名']]) # 保存结果到Excel文件(确保身份证号以文本格式保存) with pd.ExcelWriter('分析结果.xlsx', engine='xlsxwriter') as writer: results_df[['证件号码', '姓名']].to_excel(writer, index=False) workbook = writer.book worksheet = writer.sheets['Sheet1'] # 设置单元格格式为文本 text_format = workbook.add_format({'num_format': '@'}) worksheet.set_column('A:A', None, text_format) print("\n分析结果已保存到 '分析结果.xlsx'") else: print("未找到符合条件的记录")
(2)现想要进一步挖掘出疑似高某霞作案团伙的其他成员,请结合第(1)问中的结果,分析与高某霞在2020年6月27日(含)至2020年7月27日(含)有过入住同一家酒店且入住时间间隔在3天内,并与高某霞有过同一天乘坐同一车号火车记录的人员有哪些?(填写身份证号和姓名)(5分)